Във всички основни продукти на RDBMS, Ограниченията на първичния ключ в SQL има жизненоважна роля. Те идентифицират записите, присъстващи в таблицата, уникално. Следователно трябва внимателно да изберем сървъра с първични ключове по време на дизайна на таблицата, за да подобрим производителността.
В тази статия ще научим какво е ограничение за първичен ключ. Освен това ще видим как да създаваме, модифицираме или премахваме ограничения за първични ключове.
Ограничения на SQL сървъра
В SQL Server, Ограничения са правила, които регулират въвеждането на данните в необходимите колони. Ограниченията налагат точността на данните и как тези данни отговарят на бизнес изискванията. Освен това те правят данните надеждни за крайните потребители. Ето защо е от решаващо значение да се идентифицират правилните ограничения по време на фазата на проектиране на схемата на базата данни или таблицата.
SQL Server поддържа следните типове ограничения за налагане на целостта на данните:
Ограничения на първичния ключ се създават в една колона или комбинация от колони, за да наложат уникалността на записите и да идентифицират записите по-бързо. Включените колони не трябва да съдържат стойности NULL. Следователно свойството NOT NULL трябва да бъде дефинирано в колоните.
Ограничения за външни ключове се създават в една колона или комбинация от колони, за да създадат връзка между две таблици и да наложат данните, присъстващи в една таблица, към друга. В идеалния случай колоните на таблицата, където трябва да наложим данните с ограничения на външния ключ, се отнасят до таблицата източник с първичен ключ в SQL или ограничение на уникален ключ. С други думи, само записите, налични в ограниченията на първичния или уникалния ключ на таблицата източник, могат да бъдат вмъкнати или актуализирани в таблицата местоназначение.
Уникални ключови ограничения се създават в една колона или комбинация от колони, за да се наложи уникалност в данните в колоната. Те са подобни на ограниченията на първичния ключ с една промяна. Разликата между ограниченията на първичния ключ и ограниченията на уникалния ключ е, че последните могат да бъдат създадени на Nullable колони и разреши един запис на стойност NULL в колоната му.
Проверете ограничения се създават в една колона или комбинация от колони чрез ограничаване на приетите стойности на данни за участващите колони чрез логически израз. Има разлика между външния ключ и ограниченията за проверка. Външният ключ налага целостта на данните, като проверява данни от първичния или уникалния ключ на друга таблица. Ограничението за проверка обаче прави това, като използва логически израз.
Сега нека преминем през ограниченията на първичния ключ.
Ограничение на първичния ключ
Ограничението на първичния ключ налага уникалност на една колона или комбинация от колони без стойности NULL вътре в участващите колони.
За да наложи уникалност, SQL Server създава уникален клъстериран индекс за колоните, където са създадени първичните ключове. Ако има някакви съществуващи клъстерирани индекси, SQL Server създава уникален неклъстериран индекс в таблицата за първичния ключ.
Нека да видим как създаваме, модифицираме, пускаме, деактивираме или активираме първични ключове в таблица с помощта на T-SQL скриптове.
Създаване на първичен ключ
Можем да създадем първични ключове на таблица или по време на създаването на таблицата, или след това. Синтаксисът варира леко за тези сценарии.
Създаване на първичен ключ по време на създаването на таблица
Синтаксисът е по-долу:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Нека създадем таблица с име Служители в Човешки ресурси схема за целите на тестване със скрипта по-долу:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
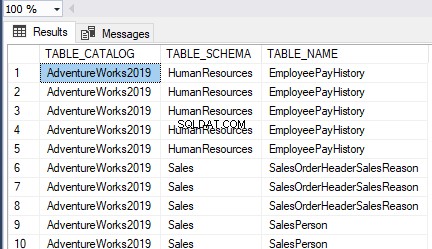
Успешно създадохме HumanResources.Employees таблица на AdventureWorks база данни:
Можем да видим, че клъстерираният индекс е създаден в таблицата, съответстваща на името на първичния ключ, както е подчертано по-горе.
Нека пуснем таблицата с помощта на скрипта по-долу и опитаме отново с новия синтаксис.
DROP TABLE HumanResources.EmployeesЗа да създадете първичен ключ в SQL в таблица с дефинираното от потребителя име на първичен ключ PK_Employees , използвайте следния синтаксис:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Създадохме HumanResources.Employees таблица с името на първичния ключ PK_Employees :
Създаване на първичен ключ след създаването на таблица
Понякога разработчиците или администраторите на база данни забравят за първичните ключове и създават таблици без тях. Но е възможно да се създаде първичен ключ на съществуващи таблици.
Нека пуснем Човешки ресурси.Служители таблица и я създайте отново, като използвате скрипта по-долу:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Когато изпълните успешно този скрипт, можем да видим HumanResources.Employees таблица, създадена без първични ключове или индекси:

За да създадете първичен ключ с име PK_Employees на тази таблица, използвайте следния синтаксис:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Изпълнението на този скрипт създава първичния ключ в нашата таблица:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Създаване на първичен ключ върху множество колони
В нашите примери създадохме първични ключове на единични колони. Ако искаме да създадем първични ключове в множество колони, се нуждаем от различен синтаксис.
За да добавим няколко колони като част от първичния ключ, трябва просто да добавим разделени със запетая стойности на имената на колоните, които трябва да са част от първичния ключ.
Първичен ключ по време на създаването на таблица
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Първичен ключ след създаването на таблица
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Изхвърлете първичния ключ
За да премахнем първичния ключ, използваме синтаксиса по-долу. Няма значение дали първичният ключ е бил в една или няколко колони.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
За да премахнете ограничението на първичния ключ върху HumanResources.Employees таблица, използвайте следния скрипт:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Отпадането на първичния ключ премахва както първичните ключове, така и клъстерирани или неклъстерни индекси, създадени заедно със създаването на първичен ключ:
Промяна на първичния ключ
В SQL Server няма директни команди за промяна на първичните ключове. Трябва да премахнем съществуващ първичен ключ и да го създадем отново с необходимите модификации. Следователно, стъпките за промяна на първичния ключ са:
- Изхвърлете съществуващ първичен ключ.
- Създайте нови първични ключове с необходимите промени.
Деактивиране/активиране на първичния ключ
Докато извършвате групово натоварване на таблица с много записи, деактивирайте първичния ключ и го активирайте обратно за по-добра производителност. Стъпките са по-долу:
Деактивирайте съществуващия първичен ключ със следния синтаксис:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;За да деактивирате първичния ключ на HumanResources.Employees таблица, скриптът е:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Активирайте съществуващите първични ключове, които са в деактивирано състояние. Трябва да ПРЕБИДИМ индекса, използвайки следния синтаксис:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;За да активирате първичния ключ на HumanResources.Employees таблица, използвайте следния скрипт:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Митовете за първичния ключ
Много хора се объркват относно митовете по-долу, свързани с първичните ключове в SQL Server.
- Таблица с първичен ключ не е Heap Table
- Първичните ключове имат клъстериран индекс и данни, сортирани във физически ред
Нека ги изясним.
Таблица с първичен ключ не е Heap Table
Преди да се гмурнем по-дълбоко, нека преразгледаме дефиницията на първичния ключ и таблицата на Heap.
Първичният ключ създава клъстериран индекс върху таблица, ако там няма налични други клъстерирани индекси. Таблица без клъстериран индекс ще бъде Heap Table.
Въз основа на тези дефиниции можем да разберем, че първичният ключ създава клъстериран индекс само ако в таблицата няма други клъстерирани индекси. Ако има съществуващи клъстерирани индекси, създаването на първичен ключ ще създаде неклъстериран индекс в таблицата, съответстващ на първичния ключ.
Нека потвърдим това, като пуснем HumanResources.Employees Таблица и пресъздаването й:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Можем да посочим опцията NONCLUSTERED index за първичния ключ (вижте по-горе). Създадена е таблица с уникален, неклъстериран индекс за първичния ключ PK_Employees .
Следователно тази таблица е Heap Table, въпреки че има първичен ключ.
Нека видим дали SQL Server може да създаде неклъстериран индекс за първичния ключ, ако не посочим ключовата дума Неклъстериран по време на създаването на първичен ключ. Използвайте следния скрипт:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Тук сме създали клъстериран индекс отделно преди създаването на първичния ключ. И една таблица може да има само един клъстериран индекс. Следователно SQL Server е създал първичния ключ като уникален, неклъстериран индекс. В момента таблицата не е Heap таблица, защото има клъстериран индекс.
Ако промених решението си и изпусна клъстерирания индекс на First_Name и Фамилия колони с помощта на скрипта по-долу:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Успешно премахнахме клъстерирания индекс. Човешки ресурси.Служители таблицата е Heap таблица, въпреки че имаме първичен ключ, наличен в таблицата:
Това изчиства мита, че таблица с първичен ключ може да бъде таблица на Heap, ако в таблицата няма налични клъстерирани индекси.
Първичният ключ ще има клъстериран индекс и данни, сортирани във физически ред
Както научихме от предишния пример, първичен ключ в SQL може да има неклъстериран индекс. В този случай записите няма да бъдат сортирани във физически ред.
Нека проверим таблицата с клъстерирания индекс на първичен ключ. Ще проверим дали сортира записите във физически ред.
Създайте отново Човешки ресурси.Служители таблица с минимални колони и свойството IDENTITY премахнато за Employee_ID колона:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Сега, когато създадохме таблицата без първичния ключ или клъстериран индекс, можем да ВМЕСМЕМ 3 записа в несортиран ред за Employee_Id колона:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Нека изберем от Човешки ресурси.Служители таблица:
SELECT *
FROM HumanResources.Employees
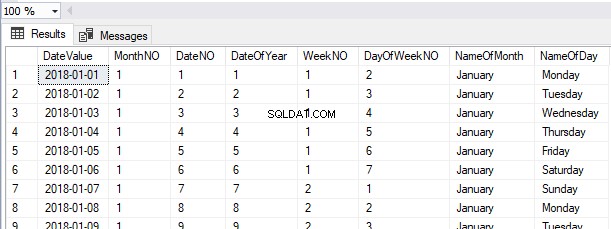
Можем да видим записите, извлечени в същия ред като записите, вмъкнати от таблицата Heap в този момент.
Нека създадем първичен ключ в тази таблица на Heap и да видим дали има някакво влияние върху оператора SELECT:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

След създаването на първичния ключ, можем да видим, че операторът SELECT извлича записи във възходящ ред на Employee_Id (Колона Първичен ключ). Това се дължи на клъстерирания индекс на Employee_Id .
Ако е създаден първичен ключ с опцията за неклъстериране, данните в таблицата няма да бъдат сортирани въз основа на колоната Първичен ключ.
Ако дължината на единичен запис в таблицата надвишава 4030 байта, само един запис може да се побере на страница. Клъстерираният индекс гарантира, че страниците са във физически ред.
Страницата е основна единица за съхранение във файлове с данни на SQL Server с размер 8 KB (8192 байта). Само 8060 байта от това устройство могат да се използват за съхранение на данни. Останалата сума е за заглавки на страници и други вътрешни елементи.
Съвети за избор на колони за първичен ключ
- Колоните с тип данни с цяло число са най-подходящи за колони с първичен ключ, тъй като заемат по-малки размери за съхранение и могат да помогнат за по-бързото извличане на данните.
- Тъй като първичните ключови колони имат клъстериран индекс по подразбиране, използвайте опцията IDENTITY в колони с целочислен тип данни, за да имате нови стойности, генерирани в нарастващ ред.
- Вместо да създавате първичен ключ за множество колони, създайте нова целочислена колона с дефинирано свойство IDENTITY. Освен това създайте уникален индекс за множество колони, които първоначално са били идентифицирани за по-добра производителност.
- Опитайте се да избягвате колони с низов тип данни като varchar, nvarchar и т.н. Не можем да гарантираме последователното увеличаване на данните за тези типове данни. Това може да повлияе на производителността на INSERT в тези колони.
- Изберете колони, в които стойностите няма да се актуализират като първични ключове. Например, ако стойността на първичния ключ може да се промени от 5 на 1000, B-дървото, свързано с клъстерирания индекс, трябва да бъде актуализирано, което води до леко влошаване на производителността.
- Ако колоните с низов тип данни трябва да бъдат избрани като колони с първичен ключ, уверете се, че дължината на колоните с тип данни varchar или nvarchar остава малка за по-добра производителност.
Заключение
Минахме през основите на ограниченията, налични в SQL Server. Разгледахме подробно ограниченията на първичния ключ и научихме как да създаваме, пускаме, модифицираме, деактивираме и възстановяваме първични ключове. Освен това изяснихме някои популярни митове около първичните ключове с примери.
Очаквайте следващата статия!