Въведение
Преди няколко години бяхме натоварени с бизнес изискване за картови данни в специфичен формат с цел нещо, наречено „съгласуване“. Идеята беше данните да се представят в таблица на приложение, което да използва и обработва данните, което ще има период на съхранение от шест месеца. Трябваше да създадем нова база данни за тази бизнес нужда и след това да създадем основната таблица като разделена таблица. Процесът, описан тук, е процесът, който използваме, за да гарантираме, че данните, по-стари от шест месеца, се преместват от таблицата по чист начин.
Малко за разделянето на дялове
Разделянето на таблица е технология на база данни, която ви позволява да съхранявате данни, принадлежащи на една логическа единица (таблицата) като набор от дялове, които ще се намират в отделна физическа структура – файлове с данни – чрез слой на абстракция, наречен файлови групи в SQL Server. Процесът на създаване на тази разделена таблица включва два ключови обекта:
Функция за дял :Функцията за разделяне дефинира как редовете на разделена таблица се картографират въз основа на стойностите на определена колона (Колоната на дяла). Разделената таблица може да се основава на списък или диапазон. За целите на нашия случай на използване (запазване на данни само за шест месеца) използвахме Разпределение на диапазона . Функцията на дял може да бъде дефинирана като RANGE DIGHT или RANGE LEFT. Използвахме RANGE RIGHT, както е показано в кода в листинг 1, което означава, че граничната стойност ще принадлежи към дясната страна на интервала на граничните стойности, когато стойностите са сортирани във възходящ ред отляво надясно.
-- Списък 1:Създайте функция на дял.USE [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime) КАТО ДИАПАЗОН ПРАВО ЗА СТОЙНОСТИ ('20190201','20190301','20190301','201902010101010109010101090101909 '20190801', '20190901', '20191001', '20191101', '20191201')GO Схема за дялове :Схемата за дялове се основава на функцията за дял и определя върху кои физически структури ще бъдат поставени редовете, принадлежащи на всеки дял. Това се постига чрез съпоставяне на такива редове с файлови групи. Списък 2 показва кода за създаване на схема на дялове. Преди да създадете схемата за дялове, трябва да съществуват файловите групи, към които ще се отнася.
-- Листинг 2:Създайте схема на дялове ---- Стъпка 1:Създайте файлови групи --ИЗПОЛЗВАЙТЕ [главна] GOALTER БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [JAN] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [FEB] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history ] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [MAR] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [APR] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [МАЙ] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [JUN]ALTER_DATABASE_DATABASE [JUN]ALTER_office_post_gis. ] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [AUG]АЛТЕР БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [SEP]ALTER БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [OCT]ALTER БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛОВА ГРУПА [NOV]ALTER DATABASE_STEP_GRUPA [публикация-GO] 2:Добавете файлове с данни към всяка файлова група -- ИЗПОЛЗВАЙТЕ [master]GOALTER DATABASE [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf'2,=1048576KB) КЪМ ФАЙЛОВА ГРУПА [JAN] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_02', ИМЕ НА ФАЙЛА =N'E:\MSSQL\DATA\post_office_history_part_02.ndf425 KB =THZZE152 5KB =02.ndf.4 KB FEB]ПРОМЕНЯ БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB_office_part_03.ndf', SIZE =2097152KB_office_story_1_file_1_file_1_file_1_file_1.df. ] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', РАЗМЕР =2097152 КБ, FILEGROWTH =1048576 КБ FILEGROWTH =1048576 КБ) [post_office_history_part_04'] [post_office_history_part_04.ndf'] [post_office_history_part_04.ndf', FILEGROWTH =1048576 КБ] N'post_office_history_part_05', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) КЪМ FILEGROUP [MAY]POST_PARTY_OFFICE_NAME (POST_FILE_PARTS_NAME) =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', SIZE =2097152 KB, FILEGROWTH =1048576 KB) КЪМ ФАЙЛОВА ГРУПА [JUN] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (NAME =N'post_office_history_part_07', FILENAMES =N'G_office_part_07', FILENAME =N'G_office_2007_2007_2002_2012_2. , FILEGROWTH =1048576KB) КЪМ ФАЙЛОВА ГРУПА [JUL] ПРОМЕНЯНЕ НА БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history, SIZE16KB2, SIZE17KB2, SIZE17KB2, SIZE17KB ФАЙЛОВА ГРУПА [AUG]ПРОМЕНЯ БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_09', ИМЕ НА ФАЙЛА =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =209716KB 209716KB 209716KB) [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (ИМЕ =N'post_office_history_part_10', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE =2097152KB, FILEGROWTH =104KBStory_office] [post_office_history_part_10'] [post_office_history_part_10.ndf'] [post_office_history_part_10.ndf', FILEGROWTH =104. ИМЕ =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) КЪМ ФАЙЛОВА ГРУПА [NOV] ПРОМЕНИ БАЗА ДАННИ [post_office_history] ДОБАВЯНЕ НА ФАЙЛ (NAME =N'post_office_part_history:NAME =N'post_office_part_history, FILEGROWTH =1048576 KB) ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) КЪМ ФАЙЛОВА ГРУПА [DEC]GO-- Стъпка 3:Създайте схема на дялове --ПЕЧАТ 'създаване на схема на дялове ...'GOUSE [post_office_history]GOCREATE APARTITION TORANTParTIANFUPT ,ФЕВ, МАР, АПР, МАЙ, ЮНИ, ЮЛ, АВГ, СЕП, ОКТ, НОЕВ, ДЕК) ГО
Забележете, че за N дялове, винаги ще имаN-1 граници. Трябва да се внимава при дефинирането на първата файлова група в схемата на дяловете. Първата граница, посочена във функцията за разделяне, ще лежи между първата и втората файлова група, така че тази гранична стойност (20190201) ще седи във втория дял (FEB). Освен това е възможно да поставите всички дялове в една файлова група, но в този случай сме избрали отделни файлови групи.
Замърсяване на ръцете
Така че нека се потопим в задачата за превключване на дялове!
Първото нещо, което трябва да направим, е да определим как точно се разпределят нашите данни между дяловете, за да можем да знаем кой дял бихме искали да изключим. Обикновено ще изключим най-стария дял.
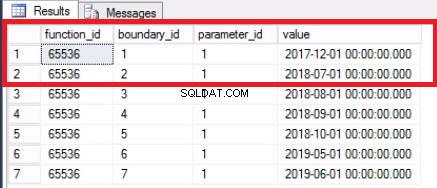
-- Списък 3:Проверете разпределението на данни в дялове --ИЗПОЛЗВАЙТЕ POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) КАТО [НОМЕР НА ПАРТИЦИЯ] , MIN(DATETIME_TRAN_LOCAL) КАТО [MIN DATE] , MAX(DATEALTIME)AS_TRAN COUNT(*) КАТО [РЕДОВЕ В ДЯЛ]ОТ DBO.POST_TRAN_TAB -- РАЗДЕЛЕНА ГРУПА НА ТАБЛИЦА ОТ $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) ПОРЪЧКА ПО [НОМЕР НА ПАРТИЦИЯ]GO
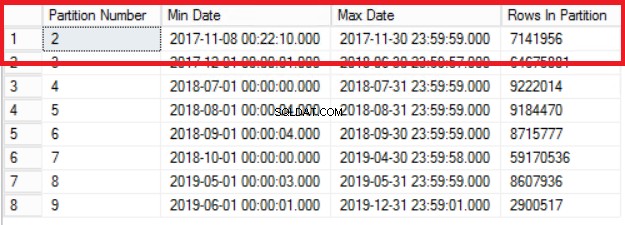
Фиг. 1 Изход от листинг 3
Фиг. 1 ни показва изхода на заявката в листинг 3. Най-старият дял е дял 2, който съдържа редове от 2017 г. Ние проверяваме това със заявката в листинг 4. Листинг 4 също ни показва коя файлова група съдържа данните в дял 2.
-- Листинг 4:Проверете файловата група, свързана с дял --ИЗПОЛЗВАЙТЕ POST_OFFICE_HISTORYGOSELECT PS.NAME КАТО PSNAME, DDS.DESTINATION_ID КАТО PARTITIONNUMBER, FG.NAME КАТО FILEGROUPNAMEFROM (((SYS.TABLES КАТО T INNER JOIN SYS.INDEXES КАТО (T.OBJECT_ID =I.OBJECT_ID)) INNER JOIN SYS.PARTITION_SCHEMES КАТО PS ON (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) INNER JOIN SYS.DESTINATION_DATA_SPACES КАТО DDS ON (PS.DATA_DSSY.SPACEEID_ID =DATA_DSSY.SPACE_ID_ID ФАЙЛОВИ ГРУПИ КАТО FG НА DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') И (I.INDEX_ID IN (0,1)) И DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('081)>
Фиг. 1 Изход от листинг 3
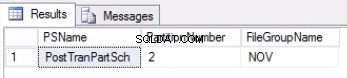
Фиг. 2 Изход от листинг 4
Списък 4 ни показва, че файловата група, свързана с дял 2, е NOV . За да изключим дял 2, се нуждаем от таблица с история, която е реплика на живата таблица, но се намира в същата файлова група като дяла, който възнамеряваме да изключим. Тъй като вече имаме тази таблица, всичко, от което се нуждаем, е да я пресъздадем в желаната файлова група. Вие също трябва да пресъздадете клъстерирания индекс. Обърнете внимание, че този клъстериран индекс има същата дефиниция като клъстерирания индекс в таблицата post_tran_tab и също се намира в същата файлова група като post_tran_tab_hist таблица.
-- Листинг 5:Създайте отново таблицата с историята -- Създайте отново таблицата с историята --ИЗПОЛЗВАЙТЕ [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tab_hist].[post_tran_tab_hist].[post_tran_tab_hist] post_tran_tab_hist]( [tran_nr] [bigint] НЕ NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [тип_съобщение] [char](4 ) NULL, [име_изходен_възел] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [име_на_възел] [varchar](30) NULL, [currency_code_] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70 ) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_req] [float] [tran_cash_t, p. ] [char](10) NULL, [тип_търговец] [char](4) NULL, [pos_entry_mode] [char] (3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [ rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_code_reason_ ] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approv ] [float] NOT NULL, [tran_completed] [char](2) NULL) НА [NOV] GOSET ANSI_PADDING OFFGO-- Създайте отново клъстерирания индекс --ИЗПОЛЗВАЙТЕ [post_office_history]GO СЪЗДАЙТЕ КЛУСТРИРАН ИНДЕКС [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) С (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, IMPGNDBORE_D OFF, SORTGNDBOP_IN OFF, SORTGNDBORE_IN_D OFF =OFF, SORTGNDBOP_IN_D , ALLOW_ROW_LOCKS =ВКЛ., ALLOW_PAGE_LOCKS =ВКЛ.) НА [NOV]GO
Изключването на последния дял вече е команда от един ред. Преброяването на двете таблици преди и след изпълнението на тази едноредова команда ще даде уверение, че имаме всички желани данни.
Фиг. 3 Таблица post_tran_tab_hist се намира във файловата група NOV
-- Листинг 6:Изключване на последния дял SELECT COUNT(*) ОТ 'POST_TRAN_TAB';SELECT COUNT(*) ОТ 'POST_TRAN_TAB_HIST'; ИЗПОЛЗВАЙТЕ [POST_OFFICE_HISTORY]GOALTER TABLE POST_TRAN_TAB ПРЕВЪКЛЮЧВАНЕ НА POST_TRAN_TAB ОТ 'POST_TRAN_TAB' ОТ 'POST_TRAN_TAB' ИЗБИРАНЕ НА PARTITION'H ИЗБИРАТЕ PARTITION* POST_TRAN_TAB';ИЗБЕРЕТЕ COUNT(*) ОТ 'POST_TRAN_TAB_HIST';
Тъй като сме изключили последния дял, вече не се нуждаем от границата. Обединяваме двата диапазона, които преди това са били разделени от тази граница, използвайки командата в листинг 7. По-нататък съкращаваме таблицата на историята, както е показано в листинг 8. Правим това, защото това е целият смисъл:премахване на стари данни, които вече не ни трябват.
-- Списък 7:Обединяване на диапазони на дялове-- Обединяване на диапазонUSE [POST_OFFICE_HISTORY]GOALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');-- Потвърдете, че диапазонът е обединенUSE [POST_OFFICE_SELECT_HISTORY]>
Фиг. 4 Обединена граница
-- Листинг 8:Съкращаване на таблицата с историяUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO
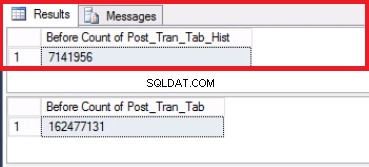
Фиг. 5 Брой на редовете за двете таблици преди отрязване
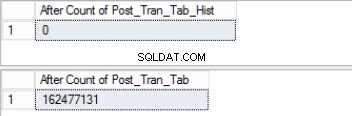
Обърнете внимание, че броят на редовете в таблицата с хронологията е точно същият като броя на редовете преди това в дял 2, както е показано на фиг. 1. Можете също така да продължите повече, като възстановите празното пространство във файловата група, принадлежаща на последната дял. Това ще бъде полезно, ако имате нужда от това пространство за новите данни, които ще се намират на предишния дял. Тази стъпка може да не е необходима, ако смятате, че имате достатъчно място във вашата среда.
-- Листинг 9:Възстановяване на място в операционната система-- Определете, че файлът е изпразнен.USE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC ОТ SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;
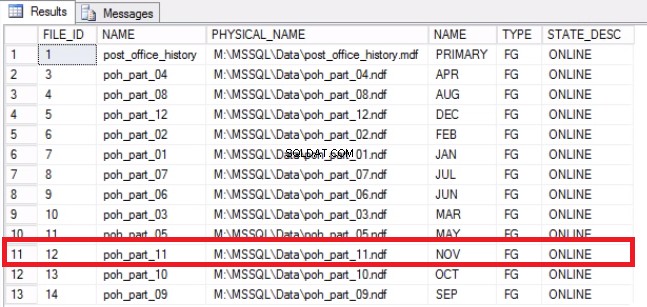
Фиг. 7 Преобразуване на файл във файлова група
-- Свийте файла до 2GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- От операционната система потвърдете свободното място на дисковете SELECT DISTINCT DB_NAME (S.DATABASE_ID) КАТО DATABASE_NAME, SID.DATABASE_NAME VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 КАТО [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/1024/1024 AS (1024/1024) НАЛЯВО ((КРЪГЛО (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) КАТО PERCENT_FREEFROM SYS.MASTER_FILES КАТО FCROSS ПРИЛОЖИ SYS.DM_OS_VOLUME_STATS (F.DATABASELEWIDE_ID) (S.DATABASE_ID) ='POST_OFFICE_HISTORY';

Фиг. 8 Свободно място в операционната система
Заключение
В тази статия направихме преглед на процеса за изключване на дялове от разделена таблица. Това е много ефективен начин за управление на растежа на данните в SQL Server. По-модерни технологии като Stretch Database са налични в текущите версии на SQL Server.
Препратки
Исаков, В. (2018). Изпит Ref 70-764 Администриране на SQL инфраструктура на база данни. Pearson Education
Разделени таблици и индекси в SQL Server