Какви са уникалните ключови ограничения?
Уникалното ограничение е правило, което ограничава вписванията в колони до уникални. С други думи, този тип ограничения предотвратяват вмъкването на дубликати в колона. Уникалното ограничение е един от инструментите за налагане на целостта на данните в база данни на SQL Server. Тъй като таблицата може да има само един първичен ключ, можете да използвате уникално ограничение, за да наложите уникалността на колона или комбинация от колони, които не представляват първичен ключ.
Създаването на уникално ограничение върху колона автоматично създава уникален индекс. По този начин SQL Server изпълнява изискването за цялост на уникалното ограничение. Следователно, когато се опитва да вмъкне дублирана стойност в колона, за която е дефинирано уникално ограничение, Database Engine ще открие нарушението на уникалното ограничение и ще издаде съответна грешка. В резултат на това редът с дублираните стойности няма да бъде добавен към таблица.
Създаване на уникално ограничение
Следната примерна заявка създава Студенти таблица и уникално ограничение за Вход колона, така че да няма студенти със същото потребителско име.
СЪЗДАВАЙТЕ ТАБЛИЦА Студенти (СНАК за вход НЕ НУЛЕН, ОГРАНИЧЕНИЕ AK_Student_Login УНИКАЛНО (Вход));GO
Ако Студентите таблицата вече съществува, тогава можете да използвате следната примерна заявка, за да създадете уникалното ограничение.
ПРОМЕНЯ ТАБЛИЦА Студенти ДОБАВЕТЕ ОГРАНИЧЕНИЕ AK_Student_Login УНИКАЛНО (Вход);GO
Имайте предвид, че когато добавите уникално ограничение към съществуваща таблица, Database Engine проверява дали колоната, към която е добавено ограничението, включва дублирани стойности. Ако има такива стойности, ограничението няма да бъде добавено, връщайки грешка.
Сега, за да проверите дали уникалното ограничение действително е добавено, изпълнете следните оператори:
EXEC sp_helpindex StudentsEXEC sp_helpconstraint Студенти
Ето ограничението, което създадохме:
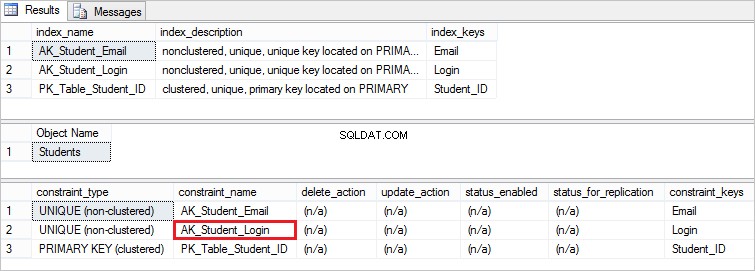
Създаване на уникално ограничение в SQL Server Management Studio
Да кажем, че трябва да дефинираме уникално ограничение за Вход колона в него Студенти таблица.
1. В Object Explorer , щракнете с десния бутон върху Ученици таблица и щракнете върху Дизайн .
2. Щракнете с десния бутон върху Дизайнер на таблици и изберете Индекси/Ключове...
3. В Индекси/Ключове прозорец, щракнете върху Добавяне .
4. Под Общи щракнете върху Колони и след това щракнете върху бутона с многоточие. В Индексните колони прозорец, изберете колоната(ите), които искате да включите в уникалното ограничение.
5. Под Общи раздел, щракнете върху Тип и изберете Уникален ключ от падащия списък.
6. Под Идентичност раздел, посочете името на ограничението (в нашия случай, AK_Student_Login ) и щракнете върху Затваряне за да запазите новосъздаденото ограничение.
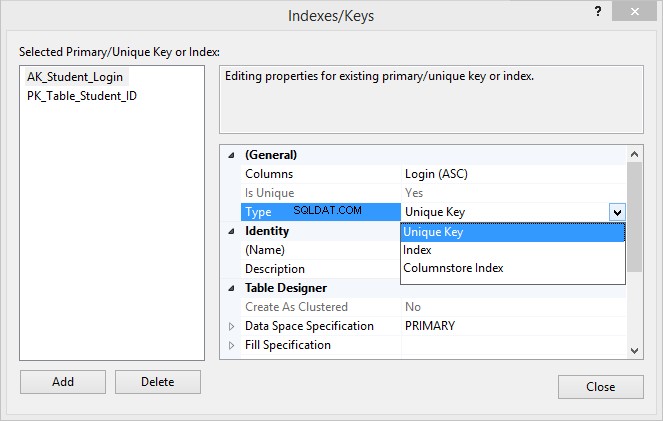
Сега, ако отидете в Студенти таблица в Object Explorer и щракнете върху Индекси папка, ще видите, че таблицата съдържа първичен ключ и уникално ограничение AK_Student_Login .
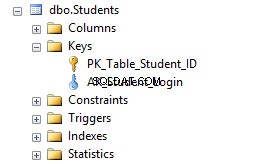
По какво се различават уникалните ограничения от първичните ключове?
Подобно на уникално ограничение, първичният ключ също се използва за налагане на целостта на данните в таблица. Но основната цел на първичния ключ е да идентифицира уникално всеки запис в таблица и да реализира правилни връзки между таблиците в база данни. В 99% от таблиците се изисква първичен ключ, за да се позволи правилен достъп до редовете на таблицата. Може да има само един първичен ключ за таблица, дефинирана в една или повече от една колони.
Уникалните ограничения се използват специално за предотвратяване на вмъкване на дублирани стойности в колона. Може да има няколко колони с уникални ограничения или изобщо да няма уникални ограничения, дефинирани в таблица. Те не са задължителни за таблица, за разлика от първичните ключове.
Да кажем, че имаме Студентите таблица, съдържаща лична информация за всеки студент в университет. Таблицата включва ID на ученик колона, която е първичен ключ и съхранява уникален идентификатор на всеки конкретен ученик. Тази колона с първичен ключ се използва за уникална идентификация на всеки студент в университет.
В същото време Студентите таблицата има такива колони като Имейл , Номер за социално осигуряване и Вход и всяка от тези колони трябва да съхранява уникални стойности. Тъй като вече има един първичен ключ в таблицата, вместо това ще използваме уникални ограничения, за да наложим уникалност на тези колони. По този начин една таблица може да има много уникални ограничения и само един първичен ключ.
Друго нещо, което различава уникалното ограничение от първичния ключ, е, че първичният ключ не позволява NULL стойности в колона, докато колона с уникално ограничение може да включва NULL стойност, но само една, тъй като SQL Server интерпретира две стойности NULL като едни и същи стойности.
Да предположим, че в Имейл е създадено уникално ограничение колона на Студенти маса. Нека се опитаме да вмъкнем два реда и двата с NULL s в Имейл полета:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login)VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555')GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login)VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17')GO
Получаваме следното съобщение за грешка:

Е, това е предвидимо поведение, защото дублиращи се стойности, дори и да са NULL, не са разрешени от уникалното ограничение.
Уникално ограничение срещу уникален индекс
Въпреки че и уникалното ограничение, и уникалният индекс са две напълно различни несвързани обекта на база данни, те имат една и съща цел и едно и също въздействие върху производителността на SQL Server. И двете осигуряват уникалност на данните в колона.
Въпреки това, за разлика от уникалния индекс, не можете да посочите опциите IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX и STATISTICS_NORECOMPUTE за уникалното ограничение в операторите ALTER TABLE.
Когато създадете уникално ограничение за колона, SQL Server автоматично създава уникален индекс за колоната, точно по този начин се реализира тази функция в SQL Server.
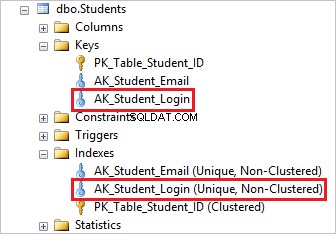
За да изтриете уникалния индекс, първо трябва да премахнете съответното уникално ограничение и това автоматично ще изтрие основния уникален индекс.
Следното изявление ще премахне AK_Student_Login ограничение:
ALTER TABLE Студентите ОТПУСКАТ ОГРАНИЧЕНИЕТО AK_Student_Login; ОТПРАВИ
Можете да видите, че премахването на AK_Student_Login уникалното ограничение изтрива съответния индекс.
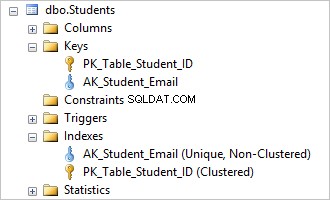
Това беше лесно, сега можете да вмъкнете идентични стойности в Вход колона.
Деактивиране на уникалното ограничение
Има опция, която деактивира уникално ограничение. Следната заявка трябва да деактивира всички ограничения на таблицата:
ИЗМЕНЯТЕ ТАБЛИЦА СтудентиNOCHECK ОГРАНИЧЕНИЕ ALLGO
След като изпълнихме заявката, нека сега се опитаме да вмъкнем дублиран запис:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login)VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555')GO
Това, което получаваме, е уникалното съобщение за нарушение на ограничението:

По този начин изглежда, че ALTER TABLE <име на таблица> NOCHECK CONSTRAINT ALL GO не работи за уникални ограничения в SQL Server.
Не забравяйте обаче, че има уникален индекс под капака на всяко уникално ограничение и трябва да можем да деактивираме уникален индекс. В нашия случай AK_Student_Email уникалното ограничение създаде съответния AK_Student_Email уникален индекс на Имейл колона. Нека използваме следната заявка, за да деактивираме AK_Student_Email първо уникален индекс.
ПРОМЕНЯ ИНДЕКС AK_Student_Email ON StudentsDISABLE;
Заявката приключи успешно, така че сега нека вмъкнем два записа с дублиран Имейл полета в Студенти таблица.
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login)VALUES (3, 'John White', 19, 'example@sqldat.com', 123-45-6789, 'John555')GOINSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login)VALUES (4, 'James Marvin', 21, 'example@sqldat.com', 987-65-4321, 'Marvin_J17')GO
Работи! Записите са вмъкнати в таблицата! Сега знаем как да заобиколим този проблем с „деактивирането“ с уникално ограничение.
За да активирате индекса, използвайте следната заявка:
ПРОМЕНИ ИНДЕКС AK_Student_Email ON StudentsREBUILD;Заключение
Уникалните ключови ограничения позволяват на разработчиците на DBA и SQL да налагат и запазват уникалността на данните в колоните на таблицата, както и да прилагат определени бизнес изисквания за целостта на данните. По принцип няма съществена разлика в поведението между уникално ограничение и уникален индекс, с изключение на факта, че уникалното ограничение не може да бъде директно деактивирано и определени опции за създаване на индекс не са налични за уникални ограничения в оператора ALTER TABLE.
Надявам се тази статия да е била интересна. Можете да задавате въпроси, да оставяте коментари и предложения относно тази статия.
Вижте също: ПРОВЕРЯТЕ Ограниченията в SQL Server