Въведение
Колкото и усилено да се опитваме да проектираме и разработваме приложения, грешки винаги ще се случват. Има две основни категории – синтаксичните или логическите грешки могат да бъдат или програмни грешки, или последствия от неправилен дизайн на базата данни. В противен случай може да получите грешка поради неправилно въведено от потребителя.
T-SQL (език за програмиране на SQL Server) позволява обработка и на двата типа грешки. Можете да отстраните грешки в приложението и да решите какво трябва да направите, за да избегнете грешки в бъдеще.
Повечето приложения изискват да регистрирате грешки, да прилагате лесно отчитане на грешки и, когато е възможно, да обработвате грешки и да продължите изпълнението на приложението.
Потребителите обработват грешки на ниво изявление. Това означава, че когато стартирате партида от SQL команди и проблемът се случи в последния израз, всичко, което предхожда този проблем, ще бъде ангажирано в базата данни като имплицитни транзакции. Това може да не е това, което желаете.
Релационните бази данни са оптимизирани за изпълнение на пакетни оператори. По този начин трябва да изпълните партида от оператори като една единица и да провалите всички оператори, ако един израз се провали. Можете да постигнете това с помощта на транзакции. Тази статия ще се фокусира както върху обработката на грешки, така и върху транзакциите, тъй като тези теми са силно свързани.
Обработка на SQL грешки
За да симулираме изключения, трябва да ги произведем по повторяем начин. Нека започнем с най-простия пример – деление на нула:
SELECT 1/0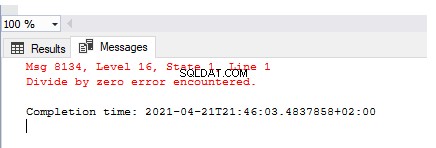
Резултатът описва изхвърлената грешка – Открита е грешка при разделяне на нула . Но тази грешка не беше обработена, регистрирана или персонализирана за създаване на удобно за потребителя съобщение.
Обработката на изключения започва с поставяне на изрази, които искате да изпълните, в блок BEGIN TRY…END TRY.
SQL Server обработва (улавя) грешки в блока BEGIN CATCH…END CATCH, където можете да въведете персонализирана логика за регистриране или обработка на грешки.
Инструкцията BEGIN CATCH трябва да следва непосредствено след оператора END TRY. След това изпълнението се предава от блока TRY към блока CATCH при първата поява на грешка.
Тук можете да решите как да се справите с грешките, дали искате да регистрирате данните за повдигнати изключения или да създадете удобно за потребителя съобщение.
SQL Server има вградени функции, които могат да ви помогнат да извлечете подробности за грешка:
- ERROR_NUMBER():Връща броя на SQL грешките.
- ERROR_SEVERITY():Връща нивото на сериозност, което показва вида на срещания проблем и неговото ниво. Нива от 11 до 16 могат да се управляват от потребителя.
- ERROR_STATE():Връща номера на състоянието на грешката и дава повече подробности за изхвърленото изключение. Използвате номера на грешката, за да търсите в базата знания на Microsoft за конкретни подробности за грешката.
- ERROR_PROCEDURE():Връща името на процедурата или тригера, в който е възникнала грешката, или NULL, ако грешката не е възникнала в процедурата или тригера.
- ERROR_LINE():Връща номера на реда, на който е възникнала грешката. Това може да бъде номерът на реда на процедурите или тригерите или номерът на реда в партидата.
- ERROR_MESSAGE():Връща текста на съобщението за грешка.
Следващият пример показва как да се справят с грешките. Първият пример съдържа Деление на нула грешка, докато второто твърдение е правилно.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Ако вторият израз се изпълни без обработка на грешки (SELECT „Правилен текст“), той ще успее.
Тъй като ние внедряваме персонализираната обработка на грешки в блока TRY-CATCH, изпълнението на програмата се предава на блока CATCH след грешката в първия израз, а вторият оператор никога не е бил изпълнен.
По този начин можете да промените текста, даден на потребителя, и да контролирате какво ще се случи, ако грешката се случи по-добре. Например регистрираме грешките в регистрационна таблица за по-нататъшен анализ.
Използване на транзакции
Бизнес логиката може да определи, че вмъкването на първия израз е неуспешно, когато вторият оператор е неуспешен, или че може да се наложи да повторите промените на първия израз при неуспех на втория израз. Използването на транзакции ви позволява да изпълнявате партида от оператори като една единица, която или се проваля, или е успешна.
Следващият пример демонстрира използването на транзакции.
Първо, създаваме таблица, за да тестваме съхранените данни. След това използваме две транзакции в блока TRY-CATCH, за да симулираме нещата, които се случват, ако част от транзакцията се провали.
Ще използваме оператора CATCH с оператора XACT_STATE(). Функцията XACT_STATE() се използва за проверка дали транзакцията все още съществува. В случай, че транзакцията се отмени автоматично, ТРАНЗАКЦИЯТА ЗА ВРЪЩАНЕ ще доведе до ново изключение.
Насладете се на следния код:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
Изображението показва стойностите в таблицата TEST_TRAN и съобщенията за грешка:
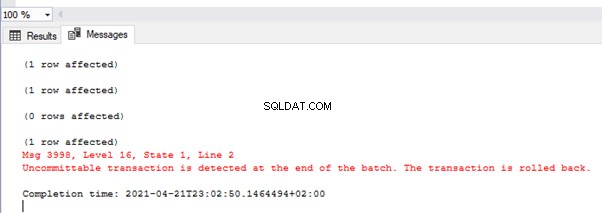
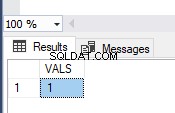
Както виждате, само първата стойност е била ангажирана. При втората транзакция имахме грешка при преобразуване на типа във втория ред. Така цялата партида се върна назад.
По този начин можете да контролирате какви данни влизат в базата данни и как се обработват партидите.
Генериране на персонализирано съобщение за грешка в SQL
Понякога искаме да създадем персонализирани съобщения за грешки. Обикновено те са предназначени за сценарии, когато знаем, че може да възникне проблем. Можем да създадем свои собствени персонализирани съобщения, казващи, че нещо не е наред, без да показваме технически подробности. За това използваме ключовата дума THROW.
BEGIN TRY
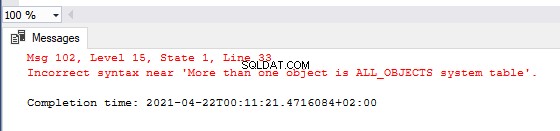
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
Или бихме искали да имаме каталог с персонализирани съобщения за грешки за категоризиране и последователност на наблюдението и отчитането на грешки. SQL Server ни позволява да дефинираме предварително кода на съобщението за грешка, сериозността и състоянието.
Съхранена процедура, наречена „sys.sp_addmessage“, се използва за добавяне на персонализирани съобщения за грешки. Можем да го използваме, за да извикаме съобщението за грешка на няколко места.
Можем да извикаме RAISERROR и да изпратим номера на съобщението като параметър, вместо да кодираме едни и същи подробности за грешката на множество места в кода.
Като изпълним избрания код отдолу, ние добавяме персонализираната грешка в SQL Server, повдигаме я и след това използваме sys.sp_dropmessage за да премахнете определеното потребителско съобщение за грешка:
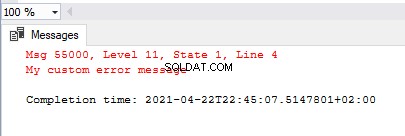
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
Също така можем да видим всички съобщения в SQL Server, като изпълним формуляра за заявка по-долу. Нашето персонализирано съобщение за грешка се вижда като първи елемент в набора от резултати:
SELECT * FROM master.dbo.sysmessages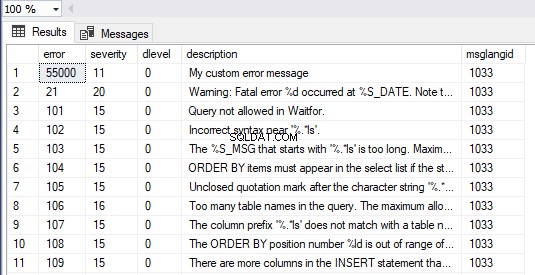
Създайте система за регистриране на грешки
Винаги е полезно да регистрирате грешки за по-късно отстраняване на грешки и обработка. Можете също да поставите тригери в тези регистрирани таблици и дори да настроите имейл акаунт и да станете малко креативни в начина, по който уведомявате хората, когато възникне грешка.
За да регистрираме грешки, създаваме таблица, наречена DBError_Log , който може да се използва за съхраняване на подробни данни от дневника:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
За да симулираме механизма за регистриране, създаваме GenError съхранена процедура, която генерира Деление на нула грешка и записва грешката в DBError_Log таблица:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
DBError_Log таблицата съдържа цялата информация, която ни е необходима, за да отстраним грешката. Освен това предоставя допълнителна информация за процедурата, която е причинила грешката. Въпреки че това може да изглежда като тривиален пример, можете да разширите тази таблица с допълнителни полета или да я използвате, за да я попълните с персонализирани изключения.
Заключение
Ако искаме да поддържаме и да отстраняваме грешки в приложенията, най-малкото искаме да съобщим, че нещо се е объркало и също да го регистрираме под капака. Когато имаме приложение на производствено ниво, използвано от милиони потребители, последователната и отчетлива обработка на грешки е ключът към отстраняването на проблеми по време на изпълнение.
Въпреки че бихме могли да регистрираме оригиналната грешка в регистъра за грешки в базата данни, потребителите трябва да виждат по-приятелско съобщение. По този начин би било добра идея да внедрите персонализирани съобщения за грешка, които се изпращат към извикващи приложения.
Какъвто и дизайн да приложите, трябва да регистрирате и обработвате потребителски и системни изключения. Тази задача не е трудна със SQL Server, но трябва да я планирате от самото начало.
Добавянето на операции за обработка на грешки в бази данни, които вече се изпълняват в производство, може да включва сериозно преработване на код и трудно откриваеми проблеми с производителността.