Тази статия се занимава с основите на семантичното търсене, включително пълен преглед на семантичното търсене:като се започне от нулата и завърши с готова за използване функция.
Освен това читателите ще научат за някои от много полезните, но не общоизвестни функции за търсене, налични в SQL Server, като семантично търсене, което ще демонстрираме с някои основни примери.
Тази статия също така подчертава важността на семантичното търсене за специфична форма на анализ, която не може да се извърши с обикновено търсене.
Какво е семантично търсене
Нека първо разберем какво точно представлява семантичното търсене и как се различава от пълнотекстово търсене.
Определение на Microsoft
Според документацията на Microsoft, Semantic Search предоставя задълбочена представа за неструктурирани документи.
Алтернативна дефиниция
Семантичното търсене е специална технология или функция за търсене, използвана за извършване на цялостно търсене или сравнителен анализ главно в неструктурирани данни или документи, като документи на MS Word, при условие че неструктурираните данни се съхраняват в базата данни на SQL Server.
Съвместимост
Семантичното търсене е съвместимо само със SQL Server 2012 и по-нови версии.
Моля, не забравяйте, че семантичното търсене не е съвместимо с Azure SQL база данни или облачни решения на Azure за съхранение на данни.
Това означава, че трябва да работите или с VM в Azure, или с локален екземпляр на SQL Server, за да използвате тази мощна функция.
Семантично търсене срещу пълнотекстово търсене
Според документацията на Microsoft, пълнотекстово търсене ви позволява да заявявате думите в документ; семантичното търсене ви позволява да потърсите значението на документа.
Семантичното търсене заедно с пълнотекстово търсене представлява една обща функция, предлагана от Microsoft SQL Server и можете да изберете да ги инсталирате по време на инсталирането на вашия екземпляр на SQL Server или по-късно, като добавите нови функции към съществуващия си SQL екземпляр.
Предварителни условия
Нека да преминем през предпоставките за общото използване на семантично търсене заедно с някои от нещата, необходими за следване на инструкциите в тази статия.
Инсталирано е пълнотекстово търсене
Задължително е да знаете как да настроите пълнотекстово търсене, тъй като търсенето в пълен текст и семантичното търсене се предлагат като съвместна функция.
Моля, вижте статията Внедряване на пълнотекстово търсене в SQL Server 2016 за начинаещи да настроят пълнотекстово търсене, което е предпоставка за инсталиране на семантично търсене в SQL Server.
Тази статия очаква да сте инсталирали пълнотекстово търсене на вашия екземпляр на SQL Server.
dbForge Studio за SQL Server
Използването на семантично търсене (в описанието на тази статия) изисква неструктурирани данни да се съхраняват в базата данни на SQL Server и в тази статия направихме това с помощта на dbForge Studio за SQL Server, вместо да записваме директно неструктурирани данни в SQL Server.
SQL Server 2016
В тази статия използваме SQL Server 2016, но стъпките трябва да са почти същите за всяка друга съвместима версия.
Настройте семантично търсене
За да използвате семантично търсене или статистическо семантично търсене, можете да го инсталирате по време на инсталирането на пълнотекстово търсене или след това, като добавите пълнотекстово търсене и семантично търсене като нова функция.
Проверка за пълнотекстово търсене
Моля, проверете състоянието на инсталиране на пълнотекстово търсене и семантично търсене, като изпълните следния скрипт срещу основната база данни:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO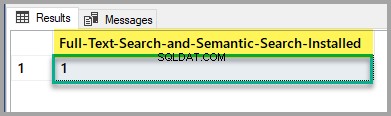
Ако изходът е 1, тогава можете да започнете, но ако е 0, моля, вижте статията, спомената по-горе, за да инсталирате функцията за пълнотекстово търсене и семантично търсене с помощта на настройката на SQL Server.
Инсталиране на база данни със статистически данни за семантичен език
Инсталирайте базата данни със статистически данни за семантичен език, като потърсите Microsoft® SQL Server® 2016 Semantic Language Statistics в интернет или щракнете върху следната връзка.
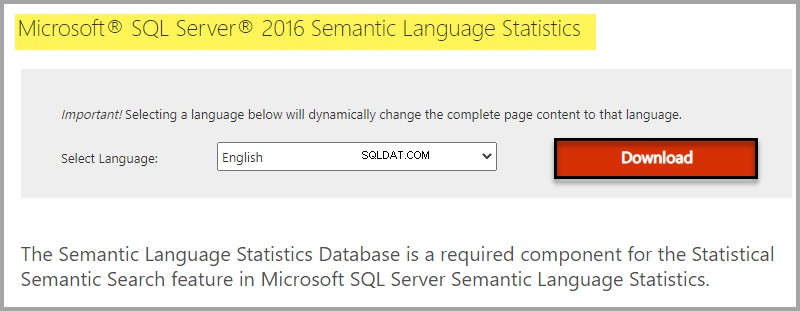
Избиране на изтегляне въз основа на вашето издание на Windows:
Инсталирайте езиковата база данни:
Кликнете върху Напред за да продължите, ако сте добре с условията в лицензионното споразумение:
Оставете опциите по подразбиране такива, каквито са, но се препоръчва да проверите цената на диска, както е показано по-долу:
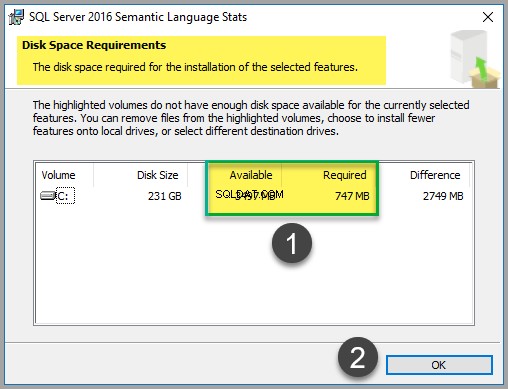
Въпреки че файлът заема само около 747 MB пространство (към момента на писане на тази статия), проверете цената на диска, за да сте сигурни, че имате достатъчно свободно пространство:
След като приключите с проверката на цената на диска, щракнете върху OK и след това щракнете върху Напред .
Ще бъдете помолени да инсталирате файла, моля, щракнете върху Инсталиране (ако се интересувате да го направите):
Кликнете върху Край след като инсталацията приключи успешно, което трябва да изглежда като екранната снимка по-долу:
Намерете папката, където е инсталирана базата данни за семантичен език по подразбиране (C:\Program Files\Microsoft Semantic Language Database):
Всичко изглежда добре, така че копирайте файла с данни и регистрационен файл в папката с данни на вашия SQL екземпляр, както е показано по-долу:
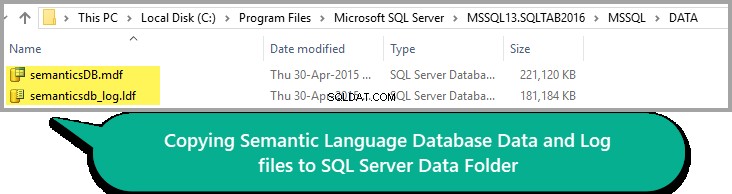
Моля, не забравяйте, че пътят на папката DATA може да варира в зависимост от версията на SQL Server.
Прикачете семантична езикова база данни към SQL екземпляр
Щракнете с десния бутон върху Бази данни възел под Object Explorer в SSMS (SQL Server Management Studio) и щракнете върху Прикачване :
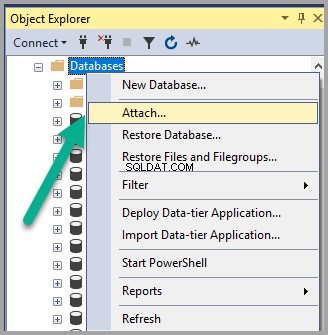
Добавете Semanticsdb.mdf и щракнете върху OK :
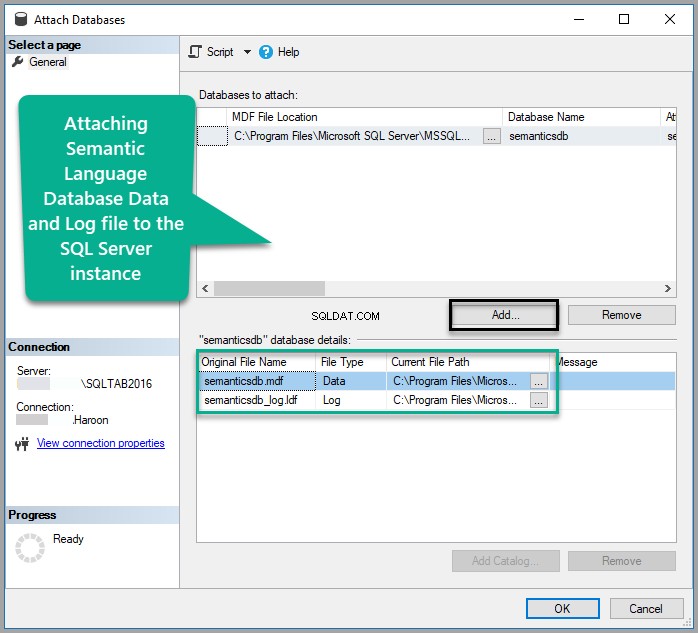
Вижте базата данни:
Регистрирайте семантична база данни
Въведете следния скрипт срещу главната база данни, за да регистрирате базата данни за семантична езикова статистика:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOПроверете състоянието на семантичната база данни
Проверете състоянието на базата данни със статистика на семантичния език, като изпълните следния скрипт срещу основната база данни:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GOРезултатът не трябва да е празен и ще бъде както следва:

Моля, не забравяйте, че стойностите по-горе може да се различават на вашата машина, което е нормално, стига да виждате ред, тогава това означава, че базата данни със статистика на семантичния език е била успешно инсталирана на вашия SQL екземпляр.
Използване на семантично търсене
След като семантичното търсене е настроено, ние сме готови да го използваме в SQL Server.
Сценарий за семантично търсене
Ще съхраняваме документите на служителите (образци) в формат на богат текст в базата данни на SQL Server, за да бъдат търсени и сравнявани по-късно с помощта на семантично търсене.
Настройте база данни EmployeesSample
Създайте примерна база данни с една таблица, като изпълните T-SQL скрипта срещу главната база данни, както следва:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOПроверете примерната база данни
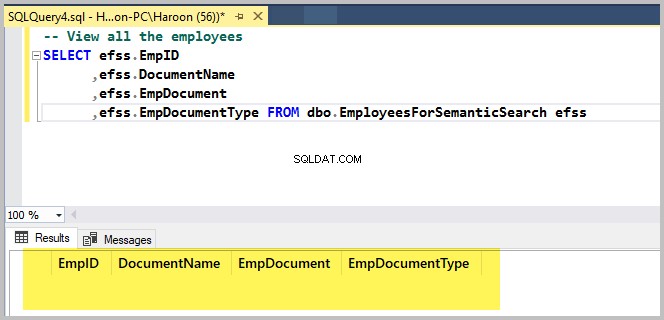
Изпълнете следния скрипт, само за да проверите примерната таблица на базата данни:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssРезултатът е както следва:
Добавете първия богат текстов файл с помощта на dbForge Studio за SQL Server
Ще добавим двоични данни към таблиците, които са представени от богати текстови файлове, използвайки dbForge Studio за SQL Server .
Отворете примерната база данни EmployeesSample в dbForge Studio за SQL Server.
Щракнете с десния бутон върху EmployeesForSemanticSearch таблица и щракнете върху Извличане на данни:
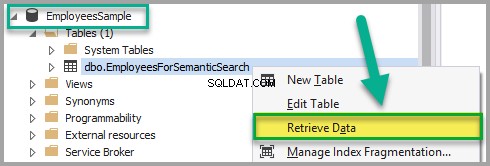
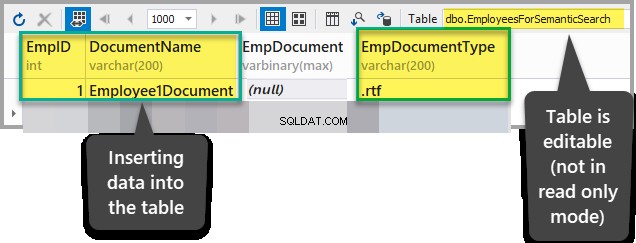
Добавете следните данни към EmployeesForSemanticSearch таблица с изключение на EmpDocument колона, след като се уверите, че таблицата не е в режим само за четене:
EmpID:1
Име на документа:Employee1Document
EmpDocument:(null)
EmpDocumentType:.rtf
Вмъкнете документ във формат на богат текст в EmpDocument колона, като добавите следния текст в таблицата (щракнете върху многоточия и добавите данните):
This is a research based article and it is a new research which is in process but this is superb in the field of research.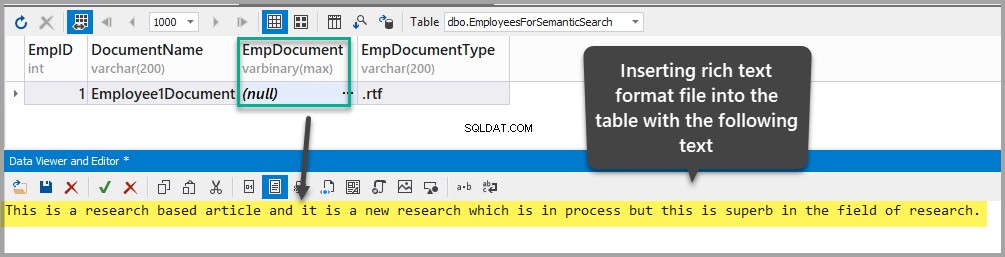
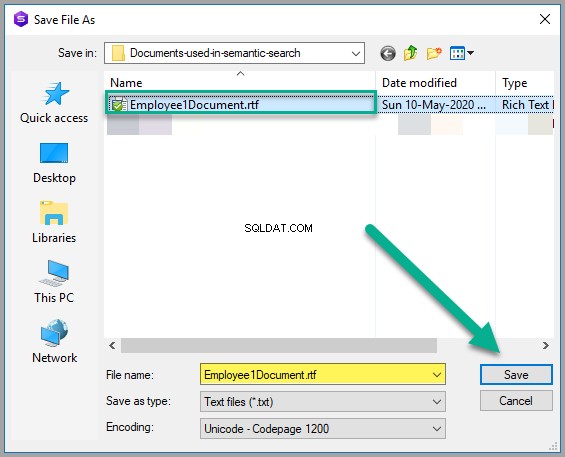
Запазете документа като Employee1Document.rtf във всяка подходяща папка на Windows:
Моля, приложете промените, за да видите, че успешно сте съхранили богат текстов файл в таблицата:
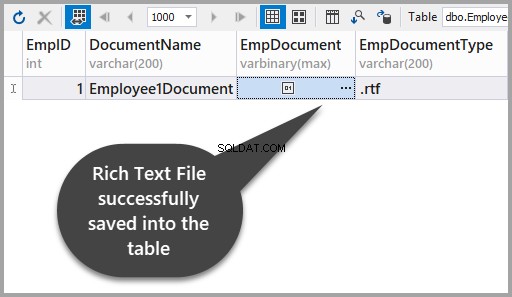
Добавете втория богат текстов файл с помощта на dbForge Studio за SQL Server
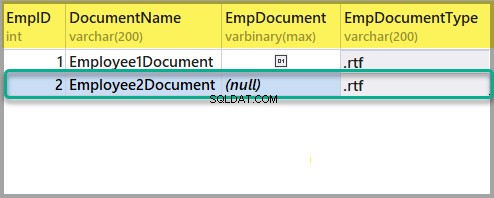
След това добавете още един файл с богат текст към EmployeesForSemanticSearch таблица по същия начин, както по-горе, като се използва следната информация:
EmpID:2
Име на документ:Employee2Document
EmpDocument:(null)
EmpDocumentType:.rtf
Добавете друг богат текстов файл със следния текст:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.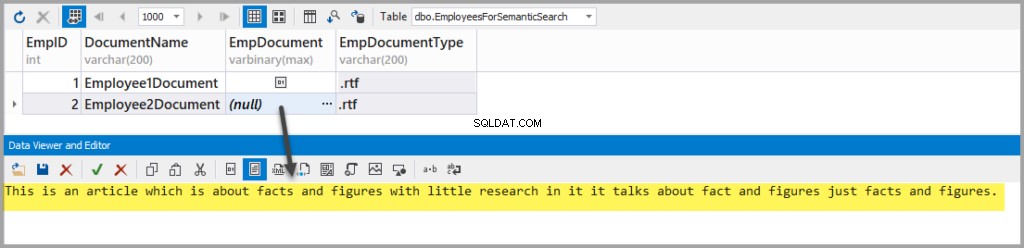
Запазете документа в същата папка, както следва:
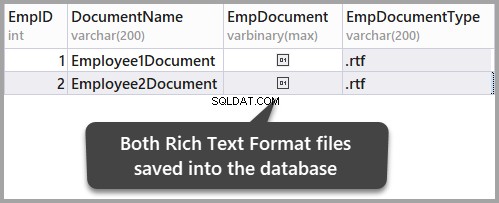
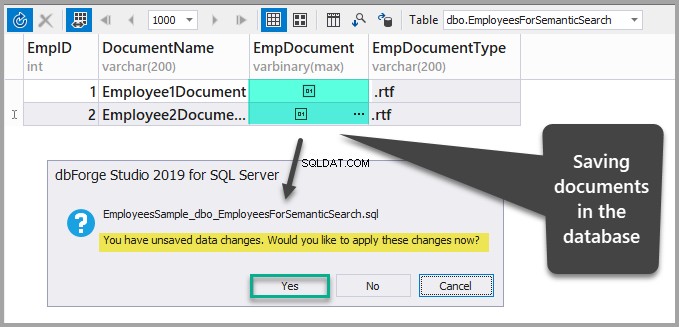
Запазете данните, като опресните таблицата и след това потвърдите промените, които току-що направихте, като щракнете върху да:
Създайте уникален индекс, индекс на пълен текст и семантичен индекс с помощта на съветника
Обратно в SSMS (SQL Server Management Studio), щракнете с десния бутон върху таблицата и щракнете върху Пълен текстов индекс и след това щракнете върху Дефиниране на пълен текстов индекс... както е показано по-долу:
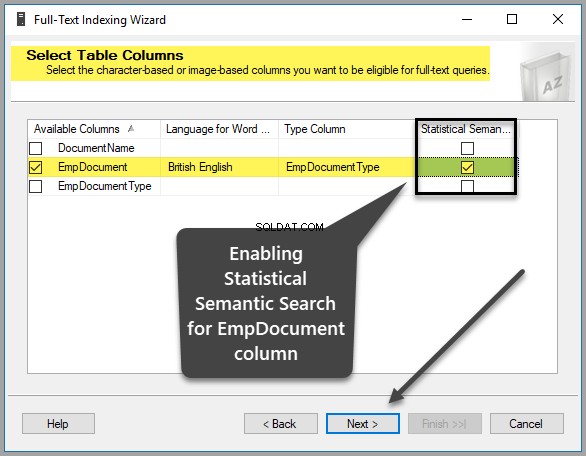
След това трябва да изберете уникален индекс, който всъщност е избран по подразбиране, тъй като създадохме EmpID колона първичен ключ по-рано, както е показано по-долу, затова кликнете върху Напред за да продължите:
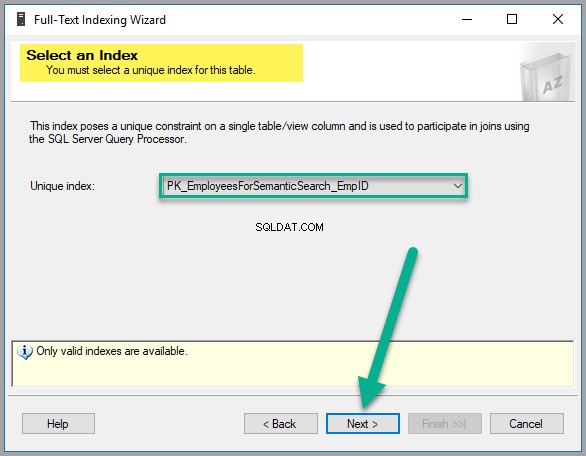
Моля, изберете EmpDocument от Налични колони , британски английски като език за Word Breaker , EmpDocumentType като тип колона и проверете статистическото семантично търсене поле в същия ред, както следва:
Изберете опцията за проследяване на промените, като я оставите като настройки по подразбиране, освен ако нямате основателна причина да промените тези настройки:
Създайте нов каталог като EmployeeCatalog :
Кликнете върху Напред отново:
Накрая, след още няколко щраквания (Щракнете върху Напред ), необходимата таблица е готова за запитване от семантично търсене:
Проверете дали семантичното търсене е активирано за таблица
Моля, проверете дали семантичното търсене остава непокътнато за таблицата от интерес, като изпълните следния скрипт срещу примерната база данни:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOРезултатът трябва да показва, че е активиран за третата колона, както го настроихме в началото на ръководството:
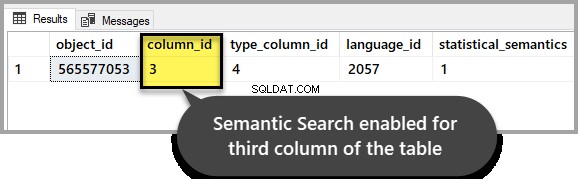
Пример 1:Използване на оценка за семантично търсене за намиране на подходящ документ
Вече можем да използваме семантично търсене, за да сравним два документа, за да намерим ключова дума, която ни интересува, и нейния относителен резултат, което ни помага да ни насочи към по-подходящи документи.
Ако ни е интересно да разгледаме документа, където е изписана думата „изследване ” се споменава по-често в сравнение с другия документ, тогава трябва да следим резултата за всеки от документите, когато стартираме следния T-SQL скрипт:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;Резултатът от заявката по-горе е както следва:
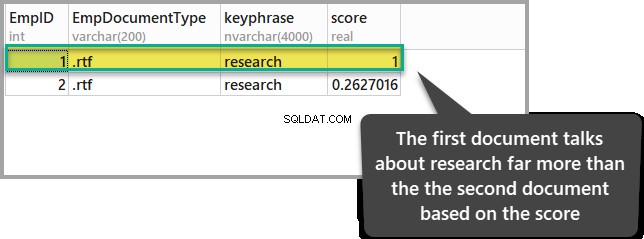
Документът с най-висок резултат показва, че има по-голяма уместност в сравнение с другия документ, що се отнася до нашата точка на интерес (изследване).
Пример 2:Използване на семантичен резултат от търсене за намиране на подходящ документ
Можем също да намерим документа, където думата „факт“ доминира в сравнение с всеки друг документ, като изпълним скрипта по-долу:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;Резултатите са както следва:
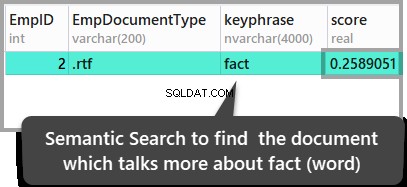
Резултатите по-горе водят до заключението, че вторият съхранен документ е единственият документ, където думата факт се споменава, но ако искате да проверите тези резултати, отворете съхранените документи, за да ги разгледате.
Честито! Успешно се научихте не само да настройвате семантично търсене в SQL Server, но и придобихте известен практически опит в използването на семантично търсене.
Неща за правене
Сега, когато можете да настроите и напишете някои основни заявки за семантично търсене, опитайте следното, за да подобрите допълнително уменията си:
- Опитайте да добавите друг документ, който разказва за изследвания и след това стартирайте скрипта в първия пример, за да видите кой документ е най-подходящият документ, като сравните техните резултати.
- Имайки предвид тази статия, добавете друг документ, където думата факт се споменава няколко пъти и след това стартирайте T-SQL в пример 2 от тази статия, за да видите дали резултатите остават същите или се променят.
- Опитайте да използвате семантично търсене, като добавите още документи и повече текст към съществуващи и нови документи и след това намерите документите, които отговарят на думите ви, които ви интересуват.
- Разгледайте примерите по-нататък, за да разберете сами дали семантичното търсене е чувствително или без значение (Съвет:Можете леко да промените примерите).