Въведение
Този урок включва информация за SQL (DDL, DML), която съм събрал през професионалния си живот. Това е минимумът, който трябва да знаете, докато работите с бази данни. Ако има нужда от използване на сложни SQL конструкции, тогава обикновено сърфирам в библиотеката MSDN, която може лесно да бъде намерена в интернет. Според мен е много трудно да държиш всичко в главата си и, между другото, няма нужда от това. Препоръчвам ви да знаете всички основни конструкции, използвани в повечето релационни бази данни като Oracle, MySQL и Firebird. Все пак те могат да се различават по типове данни. Например, за да създавате обекти (таблици, ограничения, индекси и т.н.), можете просто да използвате интегрирана среда за разработка (IDE) за работа с бази данни и няма нужда да изучавате визуални инструменти за определен тип база данни (MS SQL, Oracle , MySQL, Firebird и др.). Това е удобно, защото можете да видите целия текст и не е необходимо да преглеждате множество раздели, за да създадете например индекс или ограничение. Ако постоянно работите с бази данни, създаването, модифицирането и особено възстановяването на обект с помощта на скриптове е много по-бързо, отколкото във визуален режим. Освен това според мен в режима на скрипт (с необходимата прецизност) е по-лесно да се определят и контролират правилата за именуване на обекти. Освен това е удобно да използвате скриптове, когато трябва да прехвърлите промени в базата данни от тестова база данни в производствена база данни.
SQL е разделен на няколко части. В моята статия ще прегледам най-важните:
DDL – Език за дефиниране на данни
DML – Език за манипулиране на данни, който включва следните конструкции:
- SELECT – избор на данни
- INSERT – вмъкване на нови данни
- АКТУАЛИЗИРАНЕ – актуализиране на данните
- ИЗТРИВАНЕ – изтриване на данни
- MERGE – обединяване на данни
Ще обясня всички конструкции в учебните случаи. Освен това смятам, че езикът за програмиране, особено SQL, трябва да се изучава на практика за по-добро разбиране.
Това е стъпка по стъпка урок, където трябва да изпълнявате примери, докато го четете. Ако обаче трябва да знаете командата в подробности, тогава сърфирайте в интернет, например MSDN.
Когато създавах този урок, използвах базата данни MS SQL Server, версия 2014, и MS SQL Server Management Studio (SSMS) за изпълнение на скриптове.
Накратко за Студио за управление на MS SQL Server (SSMS)
SQL Server Management Studio (SSMS) е помощната програма на Microsoft SQL Server за конфигуриране, управление и администриране на компоненти на базата данни. Той включва редактор на скриптове и графична програма, която работи със сървърни обекти и настройки. Основният инструмент на SQL Server Management Studio е Object Explorer, който позволява на потребителя да преглежда, извлича и управлява сървърни обекти. Този текст е частично взет от Wikipedia.
За да създадете нов редактор на скриптове, използвайте бутона Нова заявка:
За да превключите от текущата база данни, можете да използвате падащото меню:
За да изпълните определена команда или набор от команди, маркирайте я и натиснете бутона Изпълнение или F5. Ако има само една команда в редактора или трябва да изпълните всички команди, тогава не маркирайте нищо.
След като сте изпълнили скриптове, които създават обекти (таблици, колони, индекси), изберете съответния обект (например таблици или колони) и след това щракнете върху Обнови в контекстното меню, за да видите промените.
Всъщност това е всичко, което трябва да знаете, за да изпълните примерите, предоставени тук.
Теория
Релационната база данни е набор от таблици, свързани помежду си. Като цяло базата данни е файл, който съхранява структурирани данни.
Системата за управление на база данни (DBMS) е набор от инструменти за работа с определени типове бази данни (MS SQL, Oracle, MySQL, Firebird и др.).
Забележка: Тъй като в ежедневието си казваме „Oracle DB“ или просто „Oracle“, което всъщност означава „Oracle DBMS“, тогава в този урок ще използвам термина „база данни“.
Таблицата е набор от колони. Много често можете да чуете следните дефиниции на тези термини:полета, редове и записи, които означават едно и също.
Таблицата е основният обект на релационната база данни. Всички данни се съхраняват ред по ред в колоните на таблицата.
За всяка таблица, както и за нейните колони, трябва да посочите име, според което да намерите необходим елемент.
Името на обекта, таблицата, колоната и индекса може да има минимална дължина – 128 символа.
Забележка: В базите данни на Oracle името на обект може да има минимална дължина – 30 символа. По този начин в конкретна база данни е необходимо да се създадат персонализирани правила за имена на обекти.
SQL е език, който позволява изпълнение на заявки в бази данни чрез СУБД. В конкретна СУБД SQL езикът може да има свой собствен диалект.
DDL и DML – SQL подезик:
- Езикът DDL служи за създаване и модифициране на структура на база данни (изтриване на таблица и връзка);
- Езикът DML позволява манипулиране на данни от таблицата, нейните редове. Също така служи за избор на данни от таблици, добавяне на нови данни, както и за актуализиране и изтриване на текущи данни.
Възможно е да се използват два типа коментари в SQL (едноредови и разделени):
-- едноредов коментар
и
/* коментар с разделители */
Това е всичко за теорията.
DDL – език за дефиниране на данни
Нека разгледаме примерна таблица с данни за служителите, представени по начин, познат на човек, който не е програмист.
| Идент. № на служител | Пълно име | Дата на раждане | Имейл | Позиция | Отдел |
| 1000 | Джон | 19.02.1955 | example@sqldat.com | Изпълнителен директор | Администриране |
| 1001 | Даниел | 03.12.1983 | example@sqldat.com | програмист | ИТ |
| 1002 | Майк | 07.06.1976 г. | example@sqldat.com | Счетоводител | Отдел по сметки |
| 1003 | Йордания | 17.04.1982 г. | example@sqldat.com | Старши програмист | ИТ |
В този случай колоните имат следните заглавия:идентификатор на служител, пълно име, рождена дата, имейл, длъжност и отдел.
Можем да опишем всяка колона от тази таблица по нейния тип данни:
- ИД на служител – цяло число
- Пълно име – низ
- Дата на раждане – дата
- Имейл – низ
- Позиция – низ
- Отдел – низ
Типът колона е свойство, което определя какъв тип данни може да съхранява всяка колона.
За начало трябва да запомните основните типове данни, използвани в MS SQL:
| Определение | Обозначение в MS SQL | Описание |
| Низ с променлива дължина | varchar(N) и nvarchar(N) | Използвайки N числото, можем да посочим максималната възможна дължина на низа за конкретна колона. Например, ако искаме да кажем, че стойността на колоната Пълно име може да съдържа 30 символа (най-много), тогава е необходимо да посочим типа на nvarchar(30).
Разликата между varchar от nvarchar е, че varchar позволява съхраняване на низове във формат ASCII, докато nvarchar съхранява низове във формат Unicode, където всеки символ отнема 2 байта. |
| Низ с фиксирана дължина | char(N) и nchar(N) | Този тип се различава от низа с променлива дължина по следното:ако дължината на низа е по-малка от N символа, тогава към дължината N отдясно винаги се добавят интервали. Така в база данни той отнема точно N символа, като един символ отнема 1 байт за char и 2 байта за nchar. В моята практика този вид не се използва много. Все пак, ако някой го използва, обикновено този тип има формат char(1), т.е. когато полето е дефинирано с 1 символ. |
| Цяло число | int | Този тип ни позволява да използваме само цяло число (както положително, така и отрицателно) в колона. Забележка:диапазонът на числата за този тип е както следва:от 2 147 483 648 до 2 147 483 647. Обикновено това е основният тип, използван за вуащу идентификатори. |
| Число с плаваща запетая | float | Числа с десетична запетая. |
| Дата | дата | Използва се за съхраняване само на дата (дата, месец и година) в колона. Например 15.02.2014 г. Този тип може да се използва за следните колони:дата на разписка, рождена дата и т.н., когато трябва да посочите само дата или когато времето не е важно за нас и можем да го премахнем. |
| Време | време | Можете да използвате този тип, ако е необходимо да съхранявате време:часове, минути, секунди и милисекунди. Например имате 17:38:31.3231603 или трябва да добавите часа на излитане на полета. |
| Дата и час | дата и час | Този тип позволява на потребителите да съхраняват както дата, така и час. Например имате събитието на 15.02.2014 г. 17:38:31.323. |
| Индикатор | бит | Можете да използвате този тип, за да съхранявате стойности като „Да“/„Не“, където „Да“ е 1, а „Не“ е 0. |
Освен това не е необходимо да се посочва стойността на полето, освен ако не е забранено. В този случай можете да използвате NULL.
За да изпълним примери, ще създадем тестова база данни, наречена „Тест“.
За да създадете проста база данни без допълнителни свойства, изпълнете следната команда:
СЪЗДАВАНЕ НА БАЗА ДАННИ Тест
За да изтриете база данни, изпълнете тази команда:
Тест за ИЗПУСКАНЕ НА БАЗА ДАННИ
За да превключите към нашата база данни, използвайте командата:
ИЗПОЛЗВАЙТЕ тест
Като алтернатива можете да изберете тестовата база данни от падащото меню в областта на менюто SSMS.
Сега можем да създадем таблица в нашата база данни, използвайки описания, интервали и кирилски символи:
СЪЗДАВАНЕ НА ТАБЛИЦА [Служители]( [EmployeeID] int, [Пълно име] nvarchar(30), [Дата на раждане] дата, [E-mail] nvarchar(30), [Позиция] nvarchar(30), [Отдел] nvarchar( 30) )
В този случай трябва да увием имената в квадратни скоби […].
Все пак е по-добре да посочите всички имена на обекти на латиница и да не използвате интервали в имената. В този случай всяка дума започва с главна буква. Например, за полето „EmployeeID“ можем да посочим името на PersonnelNumber. Можете също да използвате числа в името, например PhoneNumber1.
Забележка: В някои СУБД е по-удобно да се използва следния формат на името «PHONE_NUMBER». Например, можете да видите този формат в базите данни на ORACLE. Освен това името на полето не трябва да съвпада с ключовите думи, използвани в СУБД.
Поради тази причина можете да забравите за синтаксиса на квадратните скоби и да изтриете таблицата на служителите:
ПРОСТАЙТЕ ТАБЛИЦА [Служители]
Например можете да назовете таблицата със служители като „Служители“ и да зададете следните имена за нейните полета:
- ИД
- Име
- Рожден ден
- Имейл
- Позиция
- Отдел
Много често използваме „ID“ за полето за идентификатор.
Сега нека създадем таблица:
СЪЗДАВАНЕ НА ТАБЛИЦА Служители( ID int, Име nvarchar(30), Дата на рожден ден, Имейл nvarchar(30), Позиция nvarchar(30), Отдел nvarchar(30) )
За да зададете задължителните колони, можете да използвате опцията NOT NULL.
За текущата таблица можете да предефинирате полетата, като използвате следните команди:
-- ID поле updateALTER TABLE Служители ALTER COLUMN ID int NOT NULL-- поле за име updateALTER TABLE Служители ALTER COLUMN Име nvarchar(30) NOT NULL
Забележка: Общата концепция на SQL езика за повечето СУБД е една и съща (от моя собствен опит). Разликата между DDL в различните СУБД е основно в типовете данни (те могат да се различават не само по имената си, но и по специфичната им реализация). Освен това специфичната SQL реализация (команди) е една и съща, но може да има леки разлики в диалекта. Познавайки основите на SQL, можете лесно да превключвате от една СУБД към друга. В този случай ще трябва само да разберете спецификата на внедряването на команди в нова СУБД.
Сравнете същите команди в СУБД ORACLE:
-- създайте таблица CREATE TABLE Employees( ID int, -- В ORACLE типът int е стойност за число(38) Име nvarchar2(30), -- в ORACLE nvarchar2 е идентичен с nvarchar в MS SQL Рожден ден, Имейл nvarchar2(30), Позиция nvarchar2(30), Отдел nvarchar2(30) ); -- Актуализация на полето за идентификатор и име (тук използваме MODIFY(…) вместо ALTER COLUMNALTER TABLE Служители MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавете PK (в този случай конструкцията е същата както в MS SQL) ALTER TABLE Служители ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ PK_Служители ПЪРВЕН КЛЮЧ(ИД);
ORACLE се различава в прилагането на типа varchar2. Форматът му зависи от настройките на DB и можете да запишете текст, например, в UTF-8. Освен това можете да посочите дължината на полето както в байтове, така и в символи. За да направите това, трябва да използвате стойностите BYTE и CHAR, последвани от полето за дължина. Например:
ИМЕ varchar2(30 BYTE) – капацитетът на полето е равен на 30 байта ИМЕ varchar2(30 CHAR) – капацитетът на полето е равен на 30 символа
Стойността (BYTE или CHAR), която трябва да се използва по подразбиране, когато просто посочите varchar2(30) в ORACLE, ще зависи от настройките на DB. Често можете лесно да бъдете объркани. Затова препоръчвам изрично да посочите CHAR, когато използвате типа varchar2 (например с UTF-8) в ORACLE (тъй като е по-удобно да четете дължината на низа в символи).
В този случай обаче, ако има някакви данни в таблицата, тогава за успешно изпълнение на командите е необходимо да се попълнят полетата ID и Name във всички редове на таблицата.
Ще го покажа в конкретен пример.
Нека вмъкнем данни в полетата ID, Позиция и Отдел, като използваме следния скрипт:
ВЪВЕДЕТЕ СЛУЖИТЕЛИ (ИД, Позиция, Отдел) СТОЙНОСТИ (1000,'CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Старши програмист',N'IT')
В този случай командата INSERT също връща грешка. Това се случва, защото не сме посочили стойността за задължителното поле Име.
Ако имаше някои данни в оригиналната таблица, тогава командата „ALTER TABLE Employees ALTER COLUMN ID int NOT NULL“ ще работи, докато командата „ALTER TABLE Employees ALTER COLUMN Name int NOT NULL“ ще върне грешка, която има полето Name NULL стойности.
Нека добавим стойности в полето Име:
ВЪВЕТЕ СЛУЖИТЕЛИ (ИД, позиция, отдел, име) СТОЙНОСТИ (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan')
Освен това можете да използвате NOT NULL, когато създавате нова таблица с израза CREATE TABLE.
Първо, нека изтрием таблица:
ПРОСТАНЕ СЛУЖИТЕЛИ МАСА
Сега ще създадем таблица със задължителни полета за ID и Name:
СЪЗДАВАНЕ НА ТАБЛИЦА Служители( ID int NOT NULL, Име nvarchar(30) NOT NULL, Дата на рожден ден, Имейл nvarchar(30), Позиция nvarchar(30), Отдел nvarchar(30) )
Също така можете да посочите NULL след име на колона, което означава, че са разрешени стойности NULL. Това не е задължително, тъй като тази опция е зададена по подразбиране.
Ако трябва да направите текущата колона незадължителна, използвайте следния синтаксис:
ALTER TABLE Служители ALTER COLUMN Име nvarchar(30) NULL
Като алтернатива можете да използвате тази команда:
ALTER TABLE Служители ALTER COLUMN Име nvarchar(30)
В допълнение, с тази команда можем или да променим типа поле на друго съвместимо, или да променим неговата дължина. Например, нека разширим полето Име до 50 символа:
ALTER TABLE Служители ALTER COLUMN Име nvarchar(50)
Първичен ключ
Когато създавате таблица, трябва да посочите колона или набор от колони, уникални за всеки ред. Използвайки тази уникална стойност, можете да идентифицирате запис. Тази стойност се нарича първичен ключ. Колоната ID (която съдържа «личен номер на служител» – в нашия случай това е уникалната стойност за всеки служител и не може да бъде дублирана) може да бъде основният ключ за нашата таблица за служители.
Можете да използвате следната команда, за да създадете първичен ключ за таблицата:
ПРОМЕНЯ ТАБЛИЦА Служители ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ PK_Служители ПРАВИЛЕН КЛЮЧ(ИД)
„PK_Employees“ е име на ограничение, определящо първичния ключ. Обикновено името на първичен ключ се състои от префикса „PK_“ и името на таблицата.
Ако първичният ключ съдържа няколко полета, тогава трябва да посочите тези полета в скоби, разделени със запетая:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(поле1,поле2,…)
Имайте предвид, че в MS SQL всички полета на първичния ключ НЕ трябва да са NULL.
Освен това можете да дефинирате първичен ключ при създаване на таблица. Нека изтрием таблицата:
ПРОСТАНЕ СЛУЖИТЕЛИ МАСА
След това създайте таблица, като използвате следния синтаксис:
СЪЗДАВАНЕ НА ТАБЛИЦА Служители( ID int NOT NULL, Име nvarchar(30) NOT NULL, Дата на рожден ден, Email nvarchar(30), Позиция nvarchar(30), Отдел nvarchar(30), ОГРАНИЧЕНИЕ PK_Employees ОСНОВЕН КЛЮЧ(ID) – опишете PK след всички полета като ограничение )
Добавете данни към таблицата:
ВЪВЕТЕ СЛУЖИТЕЛИ (ИД, позиция, отдел, име) СТОЙНОСТИ (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Старши програмист',N'IT',N'Jordan')
Всъщност не е необходимо да указвате името на ограничението. В този случай ще бъде присвоено име на системата. Например «PK__Employee__3214EC278DA42077»:
СЪЗДАВАНЕ НА ТАБЛИЦА Служители( ID int NOT NULL, Име nvarchar(30) NOT NULL, Дата на рожден ден, Имейл nvarchar(30), Позиция nvarchar(30), Отдел nvarchar(30), ОСНОВЕН КЛЮЧ(ID) )
или
СЪЗДАВАНЕ НА ТАБЛИЦА Служители( ID int NOT NULL PRIMARY KEY, Име nvarchar(30) NOT NULL, Дата на рожден ден, Имейл nvarchar(30), Позиция nvarchar(30), Отдел nvarchar(30) )
Лично аз бих препоръчал изрично да посочите името на ограничението за постоянни таблици, тъй като е по-лесно да се работи или изтрива изрично дефинирана и ясна стойност в бъдеще. Например:
ALTER TABLE Служители ОТПУСКАНЕ ОГРАНИЧЕНИЕТО PK_Служители
Все пак е по-удобно да приложите този кратък синтаксис, без имена на ограничения, когато създавате временни таблици на база данни (името на временна таблица започва с # или ##.
Резюме:
Вече анализирахме следните команди:
- СЪЗДАВАНЕ НА ТАБЛИЦА table_name (списък на полета и техните типове, както и ограничения) – служи за създаване на нова таблица в текущата база данни;
- ПРОСТЪПНА ТАБЛИЦА table_name – служи за изтриване на таблица от текущата база данни;
- ТАБЛИЦА ЗА ПРОМЕНИ table_name ALTER COLUMN column_name … – служи за актуализиране на типа колона или за промяна на нейните настройки (например, когато трябва да зададете NULL или NOT NULL);
- ТАБЛИЦА ЗА ПРОМЕНИ table_name ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ constraint_name PRIMARY KEY (поле1, поле2,…) – използва се за добавяне на първичен ключ към текущата таблица;
- ТАБЛИЦА ЗА ПРОМЕНИ table_name DROP CONSTRAINT constraint_name – използва се за изтриване на ограничение от таблицата.
Временни таблици
Резюме от MSDN. Има два типа временни таблици в MS SQL Server:локални (#) и глобални (##). Локалните временни таблици са видими само за техните създатели, преди екземплярът на SQL Server да бъде прекъснат. Те се изтриват автоматично, след като потребителят бъде прекъснат от екземпляра на SQL Server. Глобалните временни таблици са видими за всички потребители по време на всякакви сесии на свързване след създаването на тези таблици. Тези таблици се изтриват, след като потребителите бъдат прекъснати от екземпляра на SQL Server.
Временните таблици се създават в системната база данни tempdb, което означава, че не наводняваме основната база данни. Освен това можете да ги изтриете с помощта на командата DROP TABLE. Много често се използват локални (#) временни таблици.
За да създадете временна таблица, можете да използвате командата CREATE TABLE:
СЪЗДАВАНЕ НА ТАБЛИЦА #Temp( ID int, Име nvarchar(30) )
Можете да изтриете временната таблица с командата DROP TABLE:
ПУСНЕТЕ ТАБЛИЦА #Temp
Освен това можете да създадете временна таблица и да я попълните с данните, като използвате синтаксиса SELECT ... INTO:
ИЗБЕРЕТЕ ИД,ИМЕ INTO #Temp FROM Employees
Забележка: В различните СУБД реализацията на временни бази данни може да варира. Например в СУБД ORACLE и Firebird структурата на временните таблици трябва да се дефинира предварително чрез командата CREATE GLOBAL TEMPORARY TABLE. Освен това трябва да посочите начина за съхранение на данни. След това потребителят го вижда сред общи таблици и работи с него като с конвенционална таблица.
Нормализиране на базата данни:разделяне на подтаблици (референтни таблици) и дефиниране на връзки между таблици
Нашата текуща таблица за служители има недостатък:потребителят може да въведе произволен текст в полетата Позиция и Отдел, който може да връща грешки, тъй като за един служител може да посочи „ИТ“ като отдел, докато за друг служител може да посочи „ИТ отдел“. В резултат на това ще бъде неясно какво е имал предвид потребителят, дали тези служители работят за един и същи отдел или има правописна грешка и има 2 различни отдела. Освен това в този случай няма да можем правилно да групираме данните за отчет, където трябва да покажем броя на служителите за всеки отдел.
Друг недостатък е обемът на съхранение и неговото дублиране, т.е. трябва да посочите пълно име на отдела за всеки служител, което изисква място в базите данни за съхраняване на всеки символ от името на отдела.
Третият недостатък е сложността на актуализиране на полеви данни, когато трябва да промените име на която и да е позиция – от програмист до младши програмист. В този случай ще трябва да добавите нови данни във всеки ред на таблицата, където позицията е „Програмист“.
За да се избегнат подобни ситуации, се препоръчва да се използва нормализиране на базата данни – разделяне на подтаблици – справочни таблици.
Нека създадем 2 референтни таблици „Позиции“ и „Отдели“:
СЪЗДАВАНЕ НА ТАБЛИЦА Позиции( ID int IDENTITY(1,1) NOT NULL ОГРАНИЧЕНИЕ PK_Positions PRIMARY KEY, Име nvarchar(30) NOT NULL ) СЪЗДАВАНЕ НА ТАБЛИЦА Отдели( ID int IDENTITY(1,1) NOT NULL ОГРАНИЧЕНИЕ PK_Departments, Име на PRIMARY KEY, nvarchar(30) НЕ NULL )
Имайте предвид, че тук сме използвали ново свойство IDENTITY. Това означава, че данните в колоната ID ще бъдат изброени автоматично, започвайки с 1. Така при добавяне на нови записи стойностите 1, 2, 3 и т.н. ще бъдат присвоени последователно. Обикновено тези полета се наричат автоинкрементни полета. Само едно поле със свойството IDENTITY може да бъде дефинирано като първичен ключ в таблица. Обикновено, но не винаги, това поле е първичният ключ на таблицата.
Забележка: В различните СУБД реализацията на полета с инкрементатор може да се различава. В MySQL, например, такова поле се дефинира от свойството AUTO_INCREMENT. В ORACLE и Firebird можете да емулирате тази функционалност чрез последователности (SEQUENCE). Но доколкото знам, свойството GENERATED AS IDENTITY е добавено в ORACLE.
Нека попълним тези таблици автоматично въз основа на текущите данни в полетата "Позиция" и "Отдел" на таблицата "Служители":
-- попълнете полето Име на таблицата Позиции с уникални стойности от полето Позиция на таблицата Employees INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – пуснете записи, където позицията не е посоченаТрябва да направите същите стъпки за таблицата на отделите:
ВМЪКНЕТЕ отдели(име) ИЗБЕРЕТЕ РАЗЛИЧЕН отдел ОТ служители, КЪДЕТО Отдел НЕ Е NULLСега, ако отворим таблиците позиции и отдели, ще видим номериран списък със стойности в полето ID:
ИЗБЕРЕТЕ * ОТ позиции
| ID | Име |
| 1 | Счетоводител |
| 2 | Изпълнителен директор |
| 3 | Програмист |
| 4 | Старши програмист |
ИЗБЕРЕТЕ * ОТ отдели
| ID | Име |
| 1 | Администриране |
| 2 | Отдел по сметки |
| 3 | ИТ |
Тези таблици ще бъдат референтните таблици за дефиниране на позиции и отдели. Сега ще се позоваваме на идентификатори на позиции и отдели. Първо, нека създадем нови полета в таблицата на служителите, за да съхраняваме идентификаторите:
-- добавете поле за ID позиция ALTER TABLE Служители ДОБАВЕТЕ PositionID int -- добавете поле за ID отдел ALTER TABLE Служители ДОБАВЕТЕ DepartmentID int
Типът на референтните полета трябва да е същият като в справочните таблици, в този случай е int.
Освен това можете да добавите няколко полета, като използвате една команда, като изброите полетата, разделени със запетаи:
ALTER TABLE Служители ДОБАВЕТЕ PositionID int, DepartmentID int
Сега ще добавим референтни ограничения (ЧУЖЕН КЛЮЧ) към тези полета, така че потребителят да не може да добавя стойности, които не са стойностите на идентификатора на референтните таблици.
ПРОМЕНЯ ТАБЛИЦА Служители ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ FK_Employees_PositionID ВЪНШЕН КЛЮЧ(ПозицияID) СПРАВКИ Позиции(ID)
Същите стъпки трябва да се направят за второто поле:
ПРОМЕНЯ ТАБЛИЦА Служители ДОБАВЯНЕ НА ОГРАНИЧЕНИЕ FK_Employees_DepartmentID ВЪНШЕН КЛЮЧ(DepartmentID) СПРАВКИ Отдели(ID)
Сега потребителите могат да вмъкват в тези полета само идентификационните стойности от съответната референтна таблица. По този начин, за да използва нов отдел или позиция, потребителят трябва да добави нов запис в съответната референтна таблица. Тъй като позициите и отделите се съхраняват в референтни таблици в едно копие, тогава за да промените името им, трябва да го промените само в справочната таблица.
Името на референтното ограничение обикновено е сложно. Състои се от префикс «FK», последван от име на таблица и име на поле, което се отнася до идентификатора на референтната таблица.
Идентификаторът (ID) обикновено е вътрешна стойност, използвана само за връзки. Няма значение каква стойност има. По този начин не се опитвайте да се отървете от пропуски в последователността от стойности, които се появяват, когато работите с таблицата, например когато изтривате записи от референтната таблица.
В някои случаи е възможно да се изгради препратка от няколко полета:
ALTER TABLE таблица ADD CONSTRAINT име на ограничение ВЪНШЕН КЛЮЧ(поле1,поле2,…) РЕФЕРЕНЦИИ справочна таблица(поле1,поле2,…)
В този случай първичният ключ е представен от набор от няколко полета (поле1, поле2, …) в таблица „референтна_таблица“.
Сега нека актуализираме полетата PositionID и DepartmentID със стойностите на ID от референтните таблици.
За да направим това, ще използваме командата UPDATE:
АКТУАЛИЗИРАНЕ e SET PositionID=(ИЗБЕРЕТЕ ИД ОТ позиции, КЪДЕТО Име=е.Позиция), DepartmentID=(ИЗБЕРЕТЕ ИД ОТ отдели, КЪДЕТО Име=e.Отдел) ОТ Служители e
Изпълнете следната заявка:
ИЗБЕРЕТЕ * ОТ служители
| ID | Име | Рожден ден | Имейл | Позиция | Отдел | PositionID | Идент. № на отдел |
| 1000 | Джон | NULL | NULL | Изпълнителен директор | Администриране | 2 | 1 |
| 1001 | Даниел | NULL | NULL | Програмист | ИТ | 3 | 3 |
| 1002 | Майк | NULL | NULL | Счетоводител | Отдел по сметки | 1 | 2 |
| 1003 | Йордания | NULL | NULL | Старши програмист | ИТ | 4 | 3 |
Както можете да видите, полетата PositionID и DepartmentID съответстват на позиции и отдели. По този начин можете да изтриете полетата "Позиция" и "Отдел" в таблицата "Служители", като изпълните следната команда:
ПРОМЕНЯ ТАБЛИЦА Служители ОТПУСКАНЕ КОЛОНА Позиция, отдел
Сега изпълнете това изявление:
ИЗБЕРЕТЕ * ОТ служители
| ID | Име | Рожден ден | Имейл | PositionID | Идент. № на отдел |
| 1000 | Джон | NULL | NULL | 2 | 1 |
| 1001 | Даниел | NULL | NULL | 3 | 3 |
| 1002 | Майк | NULL | NULL | 1 | 2 |
| 1003 | Йордания | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
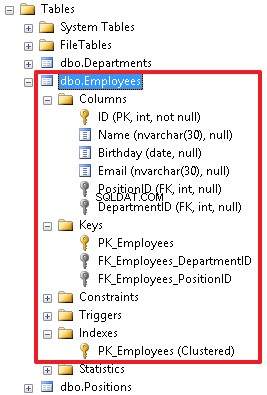
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Then create a diagram and check how our tables are linked:
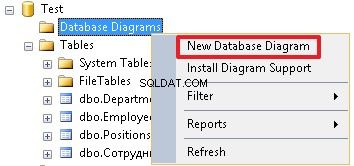
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Резюме:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
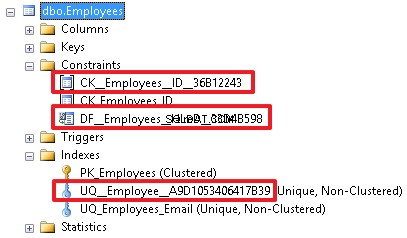
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Резюме
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.



