Въведение
В тази статия ще обсъдим как различните типове индекси в оптимизирани за памет на SQL Server таблици влияят на производителността. Ще разгледаме примери за това как различните типове индекси могат да повлияят на производителността на оптимизирани за памет таблици.
За да улесним дискусията по темата, ще използваме доста голям пример. За опростяване този пример ще включва различни реплики на една таблица, срещу която ще изпълняваме различни заявки. Тези реплики ще използват различни индекси или изобщо нямат индекси (с изключение, разбира се, първичните ключове – PK).
Имайте предвид, че действителната цел на тази статия не е да сравнява производителността между базирани на диск и оптимизирани за памет таблици в SQL Server per se. Целта му е да проучи как индексите влияят на производителността в оптимизирани за памет таблици. Въпреки това, за да се получи пълна картина на експериментите, се предоставят и времеви интервали за съответните заявки на базирани на дискове таблици и ускоренията се изчисляват, като се използва най-оптималната конфигурация на базирани на диск таблици като базови линии.
Сценарий
Примерни данни за нашия сценарий се основават на една таблица, дефинирана по следния начин:
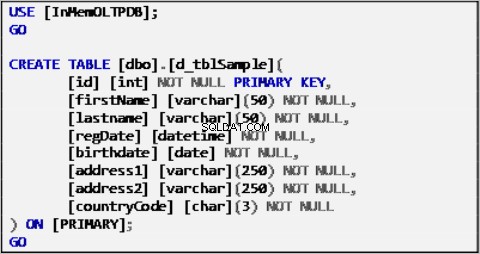
Списък 1:Примерна таблица с източници на данни.
Таблицата по-горе беше попълнена с примерни данни и ще действа като източник на данни за останалите таблици.
И така, въз основа на горната таблица, ние създаваме следните 9 варианта на таблицата и ги попълваме със същите примерни данни:
- 3 дискови таблици:
- d_tblSample1
- Клъстериран индекс в колоната „id“ – първичен ключ (PK)
- d_tblSample2
- Клъстериран индекс на колоната „id“ (PK)
- Неклъстериран индекс в колоната „countryCode“
- d_tblSample3
- Клъстериран индекс на колоната „id“ (PK)
- Неклъстерни индекси в колоната „regDate“
- Неклъстерни индекси в колоната „countryCode“
- d_tblSample1
- 3 оптимизирани за памет таблици (набор 1:хеш индекси):
- m1_tblSample1
- Неклъстериран хеш индекс в колоната „id“ – първичен ключ (PK)
- m1_tblSample2
- Неклъстериран хеш индекс в колоната „id“ (PK)
- Хеш индекс в колоната „countryCode“
- m1_tblSample3
- Неклъстериран хеш индекс в колоната „id“ (PK)
- Хеш индекс в колоната „regDate“
- Хеш индекс в колоната „countryCode“
- 3 оптимизирани за памет таблици (набор 2:Неклъстерирани индекси):
- m2_tblSample1
- Неклъстериран индекс в колоната „id“ – първичен ключ (PK)
- m2_tblSample2
- Неклъстериран индекс в колоната „id“ (PK)
- Неклъстериран индекс в колоната „countryCode“
- m2_tblSample3
- Неклъстериран индекс в колоната „id“ (PK)
- Неклъстериран индекс в колоната „regDate“
- Неклъстериран индекс в колоната „countryCode“
- m2_tblSample1
- m1_tblSample1
В списъците по-долу можете да намерите дефинициите за горните таблици.
Логиката на сценария е, че изпълняваме различни операции с база данни срещу вариации на една и съща таблица (но с различни индекси) и наблюдаваме как се влияе на производителността във всеки отделен случай.
Дефиниции
Дискови таблици
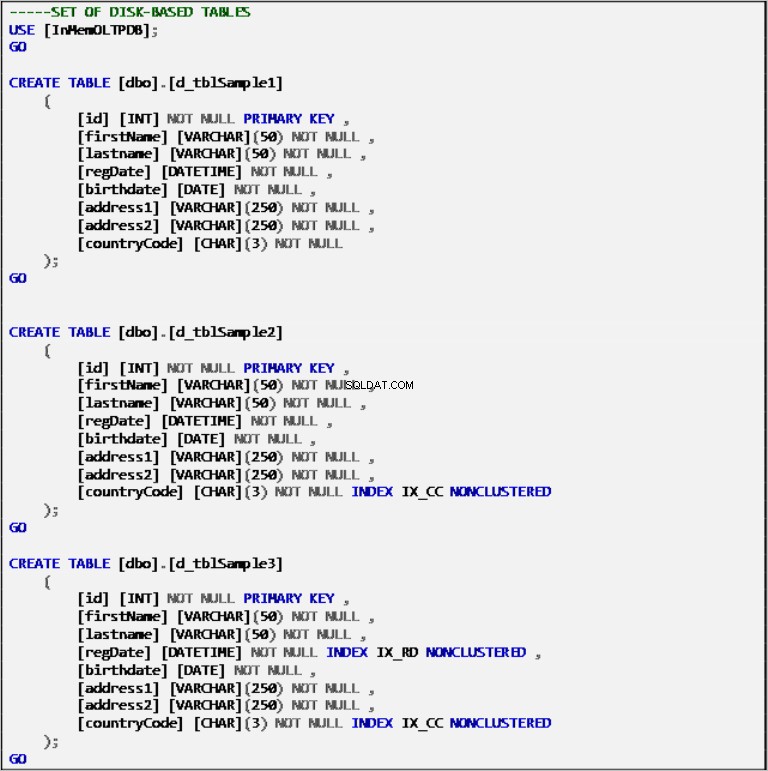
Списък 2:Дефиниция на дискови таблици.
Оптимизирани за памет таблици (набор 1:хеш индекси)

Списък 3:Оптимизирани за памет таблици – набор 1 (хеш индекси).
Оптимизирани за памет таблици (набор 2:неклъстерирани индекси)

Списък 4:Оптимизирани за памет таблици – набор 2 (неклъстерирани индекси).
След това попълваме всички горни таблици с едни и същи примерни данни, които са общо 5 милиона записа във всяка таблица.
Ето изхода на командата count за всеки набор от таблици:
Фигура 1:Общ брой записи за първи набор от таблици.
Фигура 2:Общ брой записи за втори набор от таблици.
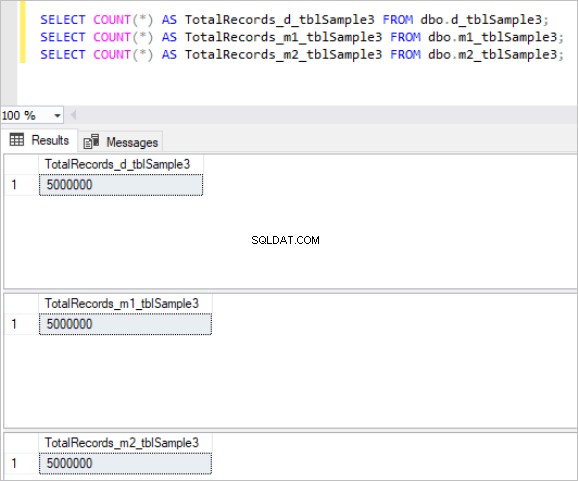
Фигура 3:Общ брой записи за трети набор от таблици.
Заявки и изпълнения на сценарии
Сега ще изпълним набор от заявки към горните таблици и ще видим как се представя всяка таблица.
Тези заявки изпълняват следните операции:
- Заявка 1:Агрегация (GROUP BY)
- Запит 2:Търсене на индекс на предикатите за равенство
- Запит 3:Индексно търсене на предикати за равенство и неравенство
Планът е да изпълните заявките, както е показано по-долу:
Заявка 1 – Изпълнение спрямо следните таблици:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (няма индекс на целевите колони)
- m2_tblSample1 (няма индекс на целевите колони)
Заявка 2 – Изпълнение спрямо следните таблици:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (няма индекс на целевите колони)
- m2_tblSample1 (няма индекс на целевите колони)
Заявка 3 – Изпълнение спрямо следните таблици:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (няма индекс на целевите колони)
- m2_tblSample1 (няма индекс на целевите колони)
Забележка :Въпреки че дефиницията за d_tblSample1 базираната на диск таблица е включена в горните дефиниции на таблицата, тя не се използва в заявките, предоставени в тази статия. Причината е, че във всеки сценарий се използва най-оптималната възможна конфигурация за базираната на диск таблица, тъй като искаме нашата базова линия да бъде възможно най-бърза, когато я сравним с производителността на оптимизирани с памет таблици. За тази цел d_tblSample1 таблицата е представена само за информационни цели.
По-долу можете да намерите T-SQL скриптовете за трите заявки, заедно с механизмите за измерване на времето за изпълнение.

Списък 5:Заявка 1 – Агрегация (с индекси).
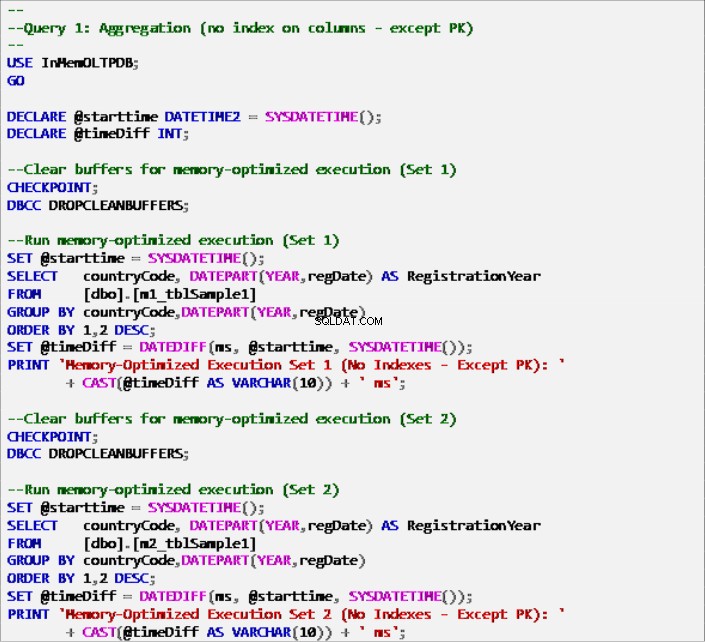
Списък 6:Заявка 1 – Агрегация (без индекси – с изключение на първичния ключ).
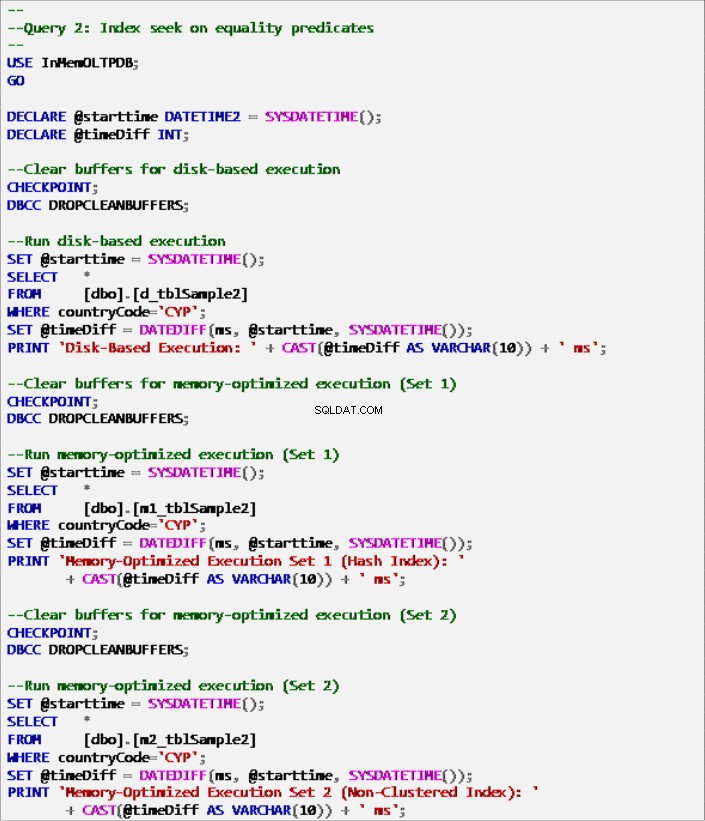
Списък 7:Заявка 2 – Търсене в индекс на предикати за равенство (с индекси).

Списък 8:Заявка 2 – Търсене в индекс на предикати за равенство (без индекси – освен първичен ключ).
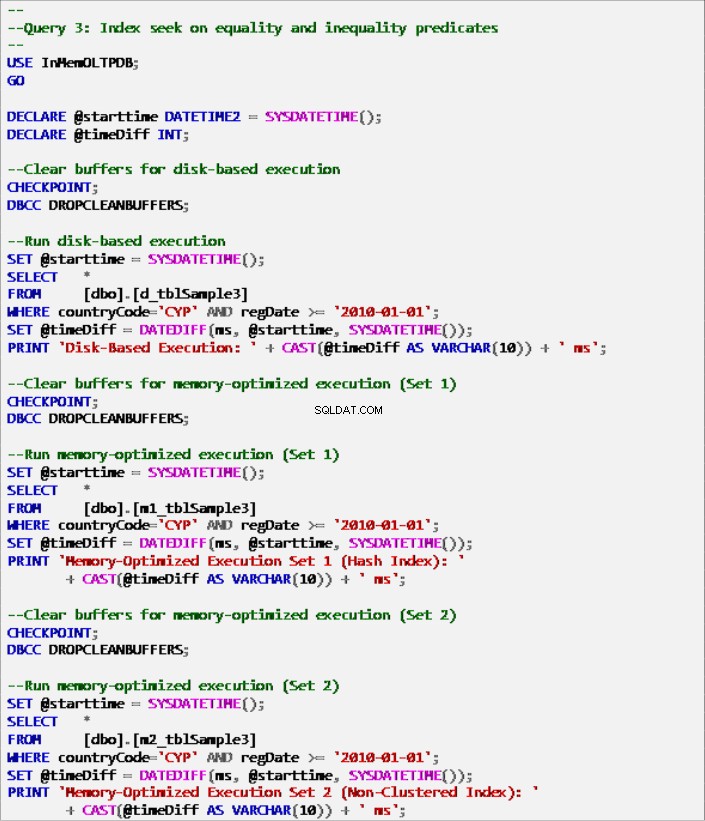
Списък 9:Заявка 3 – Търсене в индекс на предикати за равенство и неравенство (с индекси).

Списък 10:Заявка 3 – Търсене в индекс на предикати за равенство и неравенство (без индекси – с изключение на първичния ключ).
Екранните снимки по-долу показват изхода от всяко изпълнение на заявка:
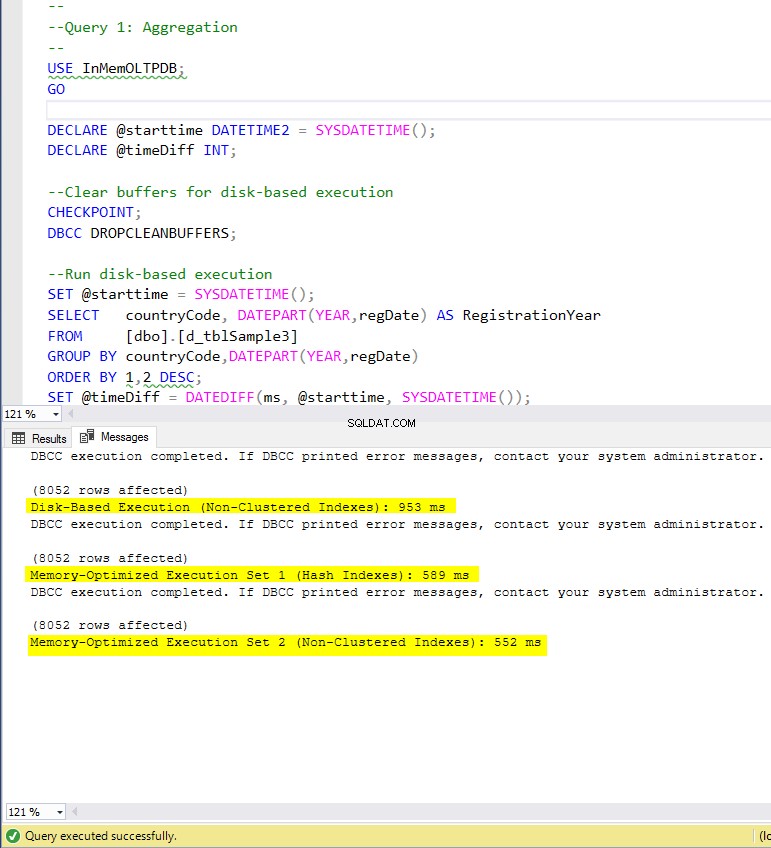
Фигура 4:Време за изпълнение на заявка 1 (с индекси).
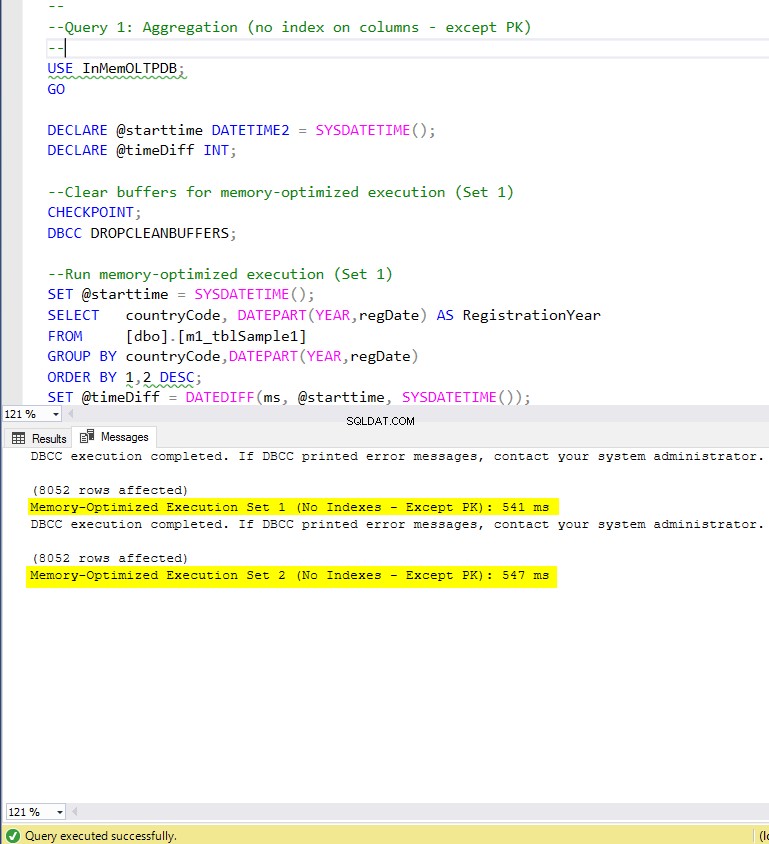
Фигура 5:Време за изпълнение на заявка 1 (без индекси – освен PK).
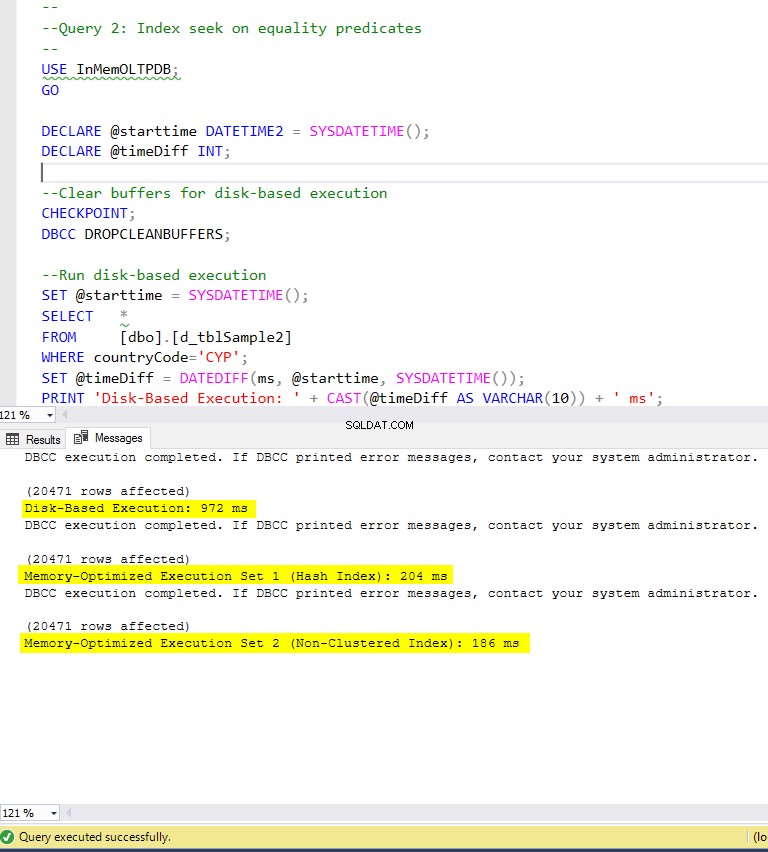
Фигура 6:Време за изпълнение на заявка 2 (с индекси).
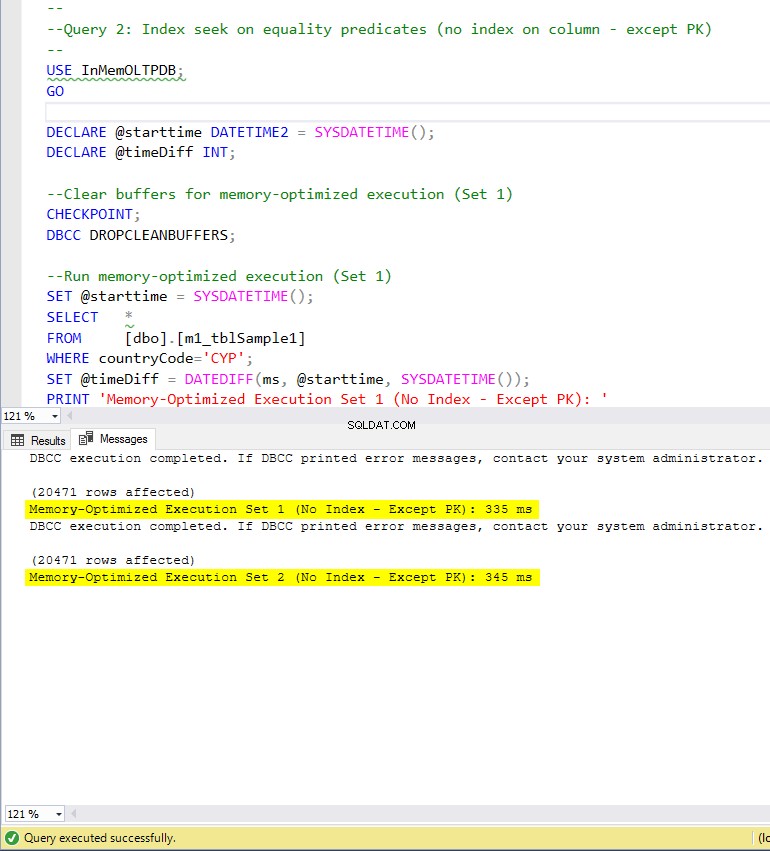
Фигура 7:Време за изпълнение на заявка 2 (без индекси – освен PK).
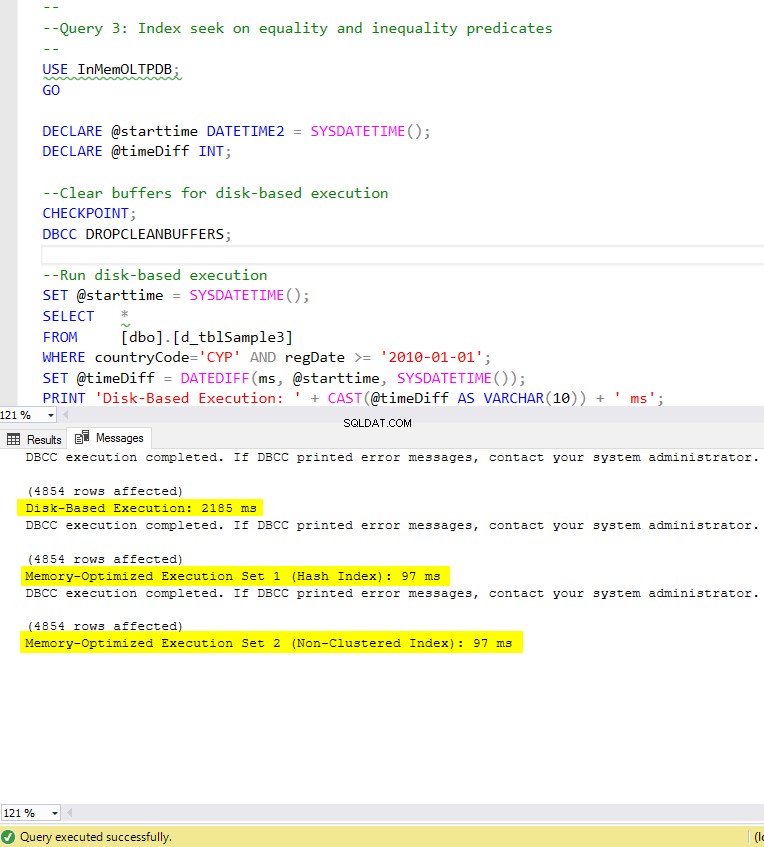
Фигура 8:Време за изпълнение на заявка 3 (с индекси).
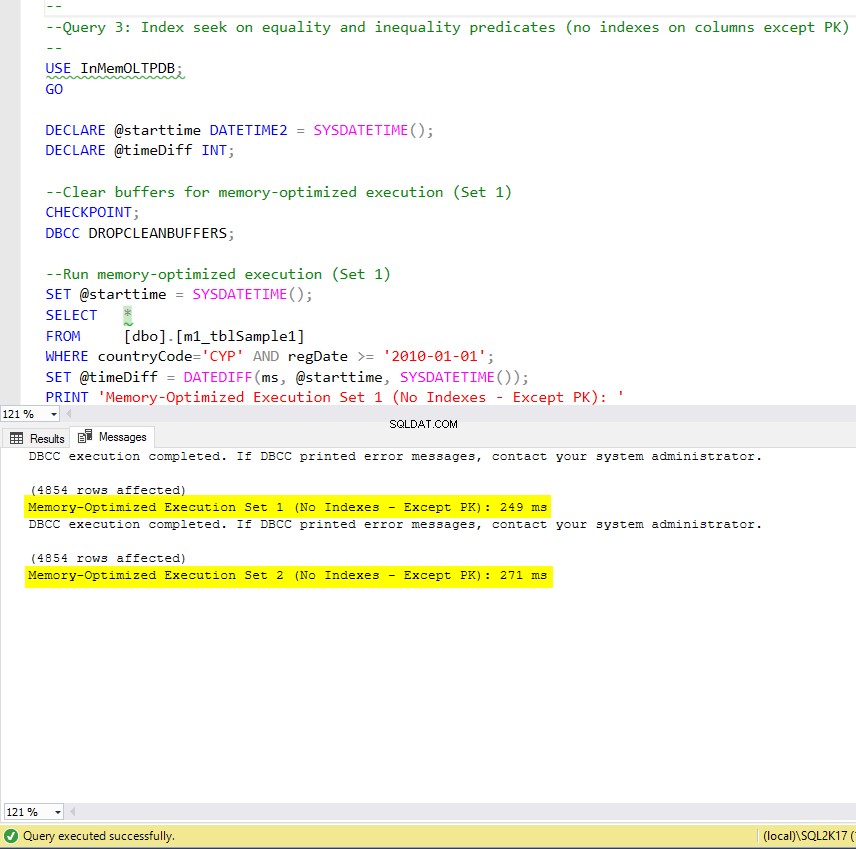
Фигура 9:Време за изпълнение на заявка 3 (без индекси – освен PK).
Сега нека обобщим резултатите, получени по-горе. Следващата таблица показва измерените времена на изпълнение за всички горепосочени заявки и комбинации таблица/индекс.
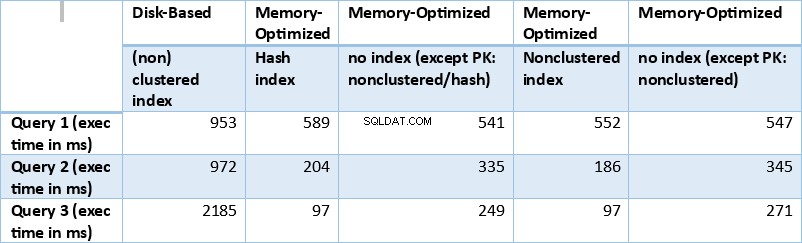
Таблица 1:Обобщена информация за времената на изпълнение (ms) за всички заявки.
Дискусия
Ако разгледаме резултатите от изпълнението, обобщени в таблицата по-горе, можем да стигнем до определени заключения. Нека начертаем всеки резултат от заявката в графика. Графиките по-долу илюстрират времената за изпълнение, както и ускоряването на оптимизираните за памет таблици спрямо таблиците, базирани на диск.
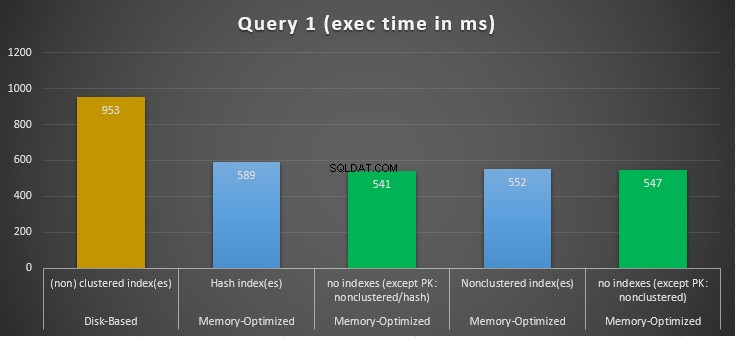
Фигура 10:Сравнение на времената за изпълнение на заявка 1.
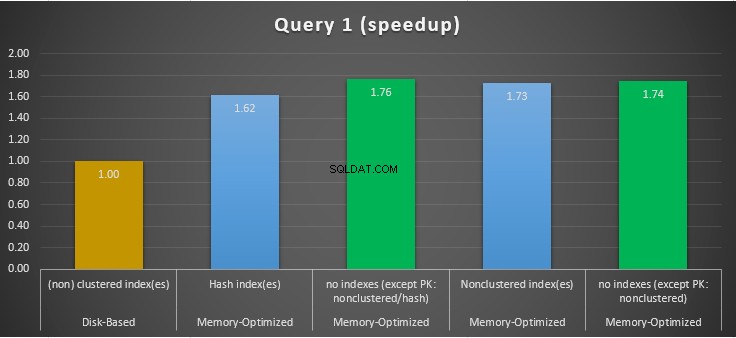
Фигура 11:Сравнение на ускоряване на заявка 1.
По отношение на заявка 1, която беше GROUP BY агрегиране, можем да видим, че и двете версии (индекси срещу никакви индекси) на оптимизирани за памет таблици изпълняват почти същото, като имат ускорение спрямо базираната на диск таблица (активирана с индекси) между 1,62 и 1,76 пъти по-бързо.
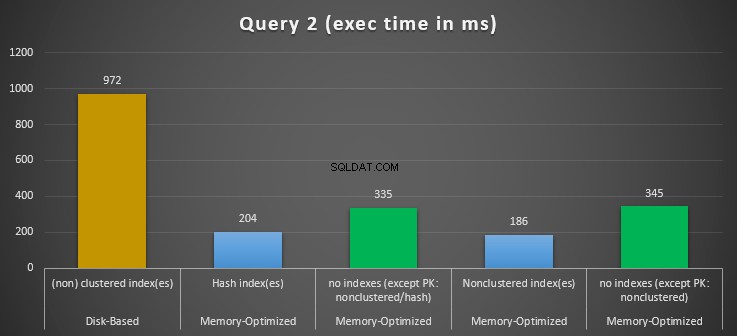
Фигура 12:Сравнение на времената за изпълнение на заявка 2.
Фигура 13:Сравнение на ускоряване на заявка 2.
По отношение на заявка 2, която включва търсене на индекс на предикатите за равенство, можем да видим, че оптимизираните за памет таблици с индекси се представят много по-добре от оптимизираните за памет таблици без индекси. Освен това забелязваме, че оптимизираната за памет таблица с неклъстериран индекс в колоната, използвана като предикат, се представя по-добре от тази с хеш индекса.
Така че, за заявка 2, победител е оптимизираната за памет таблица с неклъстерирания индекс, с общо ускорение от 5.23 пъти по-бързо в сравнение с изпълнение на диск.
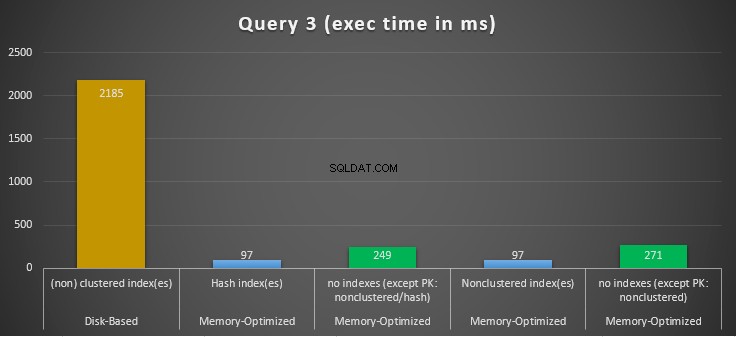
Фигура 14:Сравнение на времената за изпълнение на заявка 3.
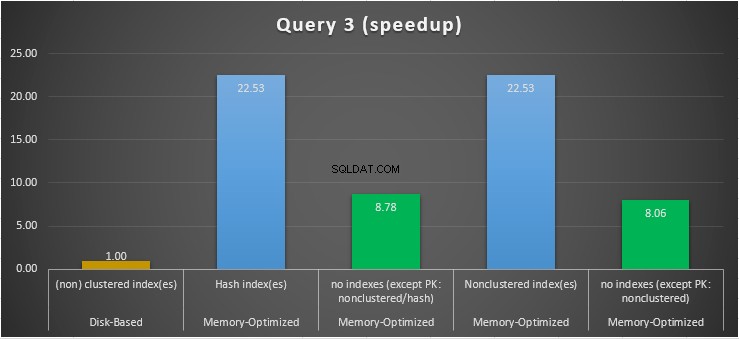
Фигура 15:Сравнение на ускоряване на заявка 3.
По отношение на заявка 3, която включва търсене на индекс на предикати за равенство и неравенство, комбинирани, можем да видим, че оптимизираните за памет таблици с индекси се представят значително по-добре от оптимизираните за памет таблици без индекси. Освен това, ние наблюдаваме, че оптимизираната за памет таблица с неклъстериран индекс в колоната, използвана като предикат, изпълнява същото като тази с хеш индекса.
За тази цел можем да видим, че и двете оптимизирани за паметта таблици, които използват индекси в колоните, използвани като предикати, се изпълняват по-бързо от тези без индекси и са постигнали ускорение от 22,53 пъти по-бързо изпълнение на базата на диск.
Заключение
В тази статия разгледахме използването на индекси в оптимизирани за памет таблици в SQL Server. Използвахме като базова линия за всяка заявка най-добрата възможна конфигурация на дисково базирана таблица и след това сравнихме производителността на три заявки с базираните на диск таблици и 4 варианта на оптимизирани за памет таблици. Две от четири оптимизирани за памет таблици използваха индекси (хеш/неклъстерирани), а другите две не използваха индекси, освен тези, използвани за първичните ключове.
Общото заключение е, че винаги трябва да проучвате как индексите влияят на производителността, не само за оптимизирани за паметта таблици, но и за базирани на дискове, и винаги когато установите, че подобряват производителността, да ги използвате. Резултатите от примерите в тази статия показват, че ако използвате правилните индекси в оптимизирани за памет таблици, можете да постигнете много по-добра производителност за заявки, подобни на използваните в тази статия, в сравнение с просто използване на оптимизирани за памет таблици без индекси .
Справки и допълнителна литература:
- Документи на Microsoft:оптимизирани за паметта таблици
- Microsoft Docs:Указания за използване на индекси в оптимизирани за памет таблици
- Microsoft Docs:Индекси на оптимизирани за памет таблици
Полезен инструмент:
dbForge Index Manager – удобна добавка за SSMS за анализиране на състоянието на SQL индексите и отстраняване на проблеми с фрагментацията на индекса.



