Фокусът на тази статия ще бъде върху използването на JOIN. Ще започнем, като поговорим малко за това как ще се случат JOIN и защо трябва да JOIN данните. След това ще разгледаме типовете JOIN, които имаме на разположение и как да ги използваме.
ОСНОВИ НА ПРИСЪЕДИНЯВАНЕТО
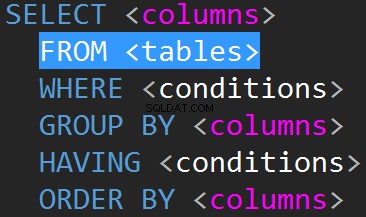
JOIN в TSQL обикновено се извършват на реда FROM.
Преди да стигнем до нещо друго, истинският голям въпрос става – „Защо трябва да правим JOIN и как всъщност ще изпълняваме нашите JOIN?“
Както се оказва, всяка база данни, с която някога работим, ще има своите данни, разделени на множество таблици. Има много различни причини за това:
- Поддържане на целостта на данните
- Спестяване на съхранено място
- По-бързо редактиране на данни
- Направете заявките по-гъвкави
По този начин всяка база данни, с която ще работите, ще се нуждае от тези данни да бъдат обединени, за да има смисъл.
Например имате отделни таблици за поръчки и за клиенти. Въпросът, който става - "Как всъщност да свържем всички данни заедно?" Точно това ще направят JOIN.
КАК РАБОТЯТ ПРИСЪЕДИНЕНИЯТА
Представете си случая, когато имаме две отделни маси и тези маси ще бъдат събрани заедно чрез създаване на шев.
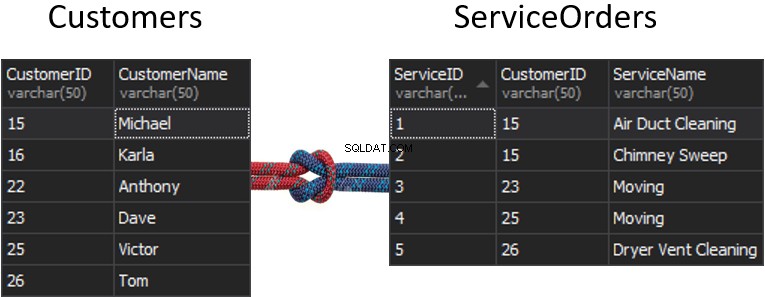
Какво ще се случи със шева, ако получим една колона от всяка таблица, която ще се използва за съпоставяне и това ще определи кои редове ще бъдат върнати или не? Например, имаме Клиенти отляво и ServiceOrders отдясно. Ако искаме да получим всички клиенти и техните поръчки, трябва да обединим тези две маси заедно. За целта трябва да изберем една колона, която ще действа като шев и очевидно, разбира се, колоната, която ще използваме, е CustomerID.
Между другото, CustomerID е известен като Primary Key за лявата таблица, която уникално идентифицира всеки отделен ред в таблицата Клиенти.
В таблицата ServiceOrders имаме също колоната CustomerID, която е известна като Външен ключ . Външният ключ е просто колона, която е предназначена да сочи към друга таблица. В нашия случай сочи обратно към таблицата на клиентите. Следователно, така ще обединим всички тези данни, като предоставим този шев.
В тези таблици имаме следните съвпадения:2 поръчки за 15 и 1 поръчка за 23, 25 и 26. 16 и 22 са изпуснати.
Едно голямо нещо, което трябва да се отбележи тук, е, че можем да СЪЕДИНИМ няколко таблици . Всъщност е доста обичайно да се СЪЕДИНЕТЕ няколко таблици заедно, за да получите каквато и да е форма на информация. Ако погледнете най-често срещаната база данни, може да се наложи да обедините четири, пет, шест и повече таблици, само за да получите информацията, която търсите. Наличието на диаграма на база данни ще бъде полезно.
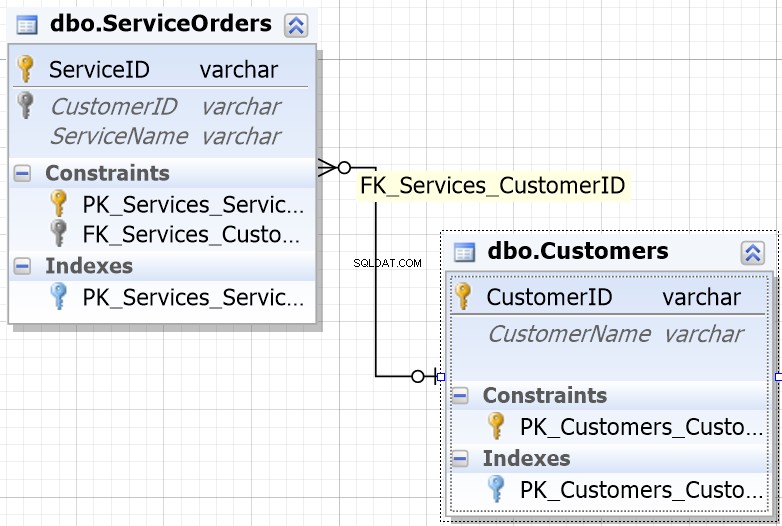
За да ви помогнем в повечето среди на бази данни, ще забележите, че колоните, предназначени да бъдат JOININ, имат едно и също име.
СИНТАКСИС НА ПРИСЪЕДИНЯВАНЕ
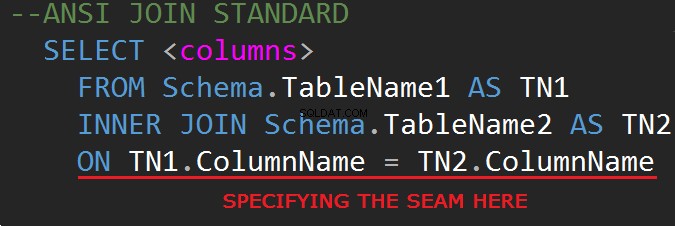
Третата ревизия на езика за заявки на SQL база данни (SQL-92) регулира синтаксиса на JOIN:
Възможно е да правите JOIN на реда WHERE:
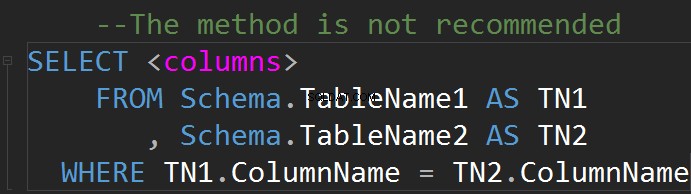
Връзката обикновено има проста графична интерпретация под формата на таблица.
Най-добри практики и конвенции
- Имена на таблици с псевдоними.
- Използвайте именуване от две части за колони
- Поставете всяко JOIN на отделен ред
- Поставете таблиците в логически ред
ТИПОВЕ ПРИСЪЕДИНЕНИЯ
SQL Server предоставя следните типове JOIN:
- INNER JOIN
- ВЪНШНО ПРИСЪЕДИНЕНИЕ
- САМО ПРИСЪЕДИНЕНЕ
- Кръстосано присъединяване
За повече информация по темата, не се колебайте да проверите тази статия за типовете обединения в SQL Server и да научите колко лесно е да се пишат такива заявки с помощта на SQL Complete.
INNER JOIN
Първият тип JOIN, който може да искаме да изпълним, е INNER JOIN. Обикновено авторите наричат този тип JOIN на SQL Server като обикновен или обикновен JOIN. Те просто пропускат префикса INNER. Този тип JOIN комбинира две таблици заедно и връща само редове от двете страни, които съвпадат .
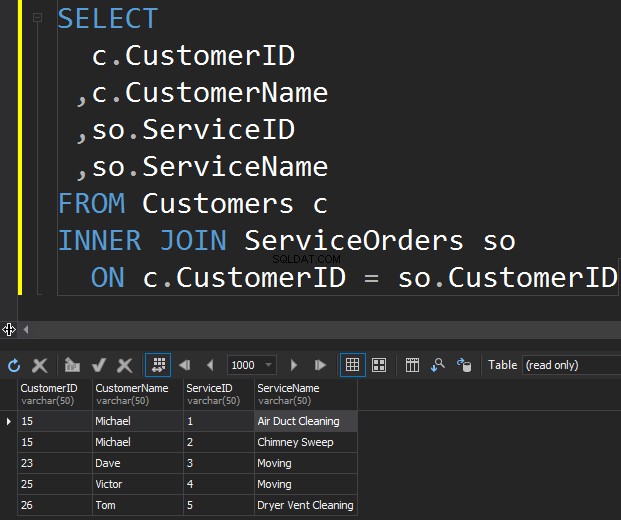
Тук не виждаме Клара и Антъни, защото техният CustomerID не съвпада и в двете таблици. Искам също така да подчертая факта, че операцията JOINвръща клиент всеки път, когато съответства на поръчката . Има две поръчки за Майкъл и по една за Дейв, Виктор и Том.
Резюме:
- INNER JOIN връща редове само когато има поне един ред и в двете таблици, който отговаря на условието JOIN.
- INNER JOIN елиминира редовете, които не съвпадат с ред от другата таблица
ВЪНШНО ПРИСЪЕДИНЕНИЕ
Външните JOIN са различни, защото връщат редове от таблици или изгледи, дори и да не съвпадат. Този тип JOIN е полезен, ако трябва да извлечете всички клиенти, които никога не са направили поръчка. Или, например, ако търсите продукт, който никога не е бил поръчван.
Начинът, по който правим нашите OUTER JOIN е чрез посочване НАЛЯВО или НАДЯСНО, или ПЪЛНО.
Няма разлики между следните клаузи:
- LEFT OUTER JOIN =LEFT JOIN
- ДЯСНО ВЪНШНО ПРИЕДИНЕНИЕ =ДЯСНО ПРИЕДИНЕНИЕ
- ПЪЛНО ВЪНШНО ПРИСЪЕДИНЕНИЕ =ПЪЛНО ПРИЕДИНЕНИЕ
Въпреки това бих препоръчал да напишете пълната клауза, защото това прави кода по-четлив.
Използване на LEFT OUTER JOIN
Няма разлика между НАЛЯВО или ДЯСНО, освен факта, че просто сочим таблицата, от която искаме да получим допълнителните редове. В следващия пример изброихме клиентите и техните поръчки. Ние използваме ЛЯВОТО, за да получим всички клиенти, които никога не са правили поръчки. Молим SQL Server да ни осигури допълнителни редове от лявата таблица.
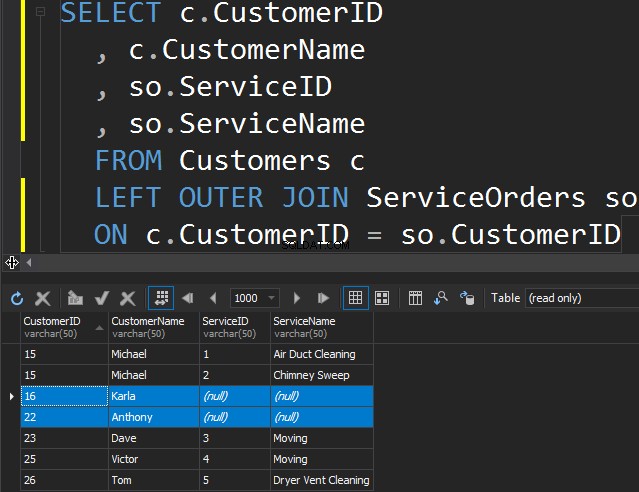
Имайте предвид, че Карла и Антъни не са направили никакви поръчки и в резултат получаваме NULL стойности за ServiceName и ServiceID. SQL Server не знае какво да постави там и поставя NULL.
Използване на RIGHT OUTER JOIN
За да получим по-малко популярната услуга от таблицата ServiceOrders, трябва да използваме ДЯСНАТА посока.
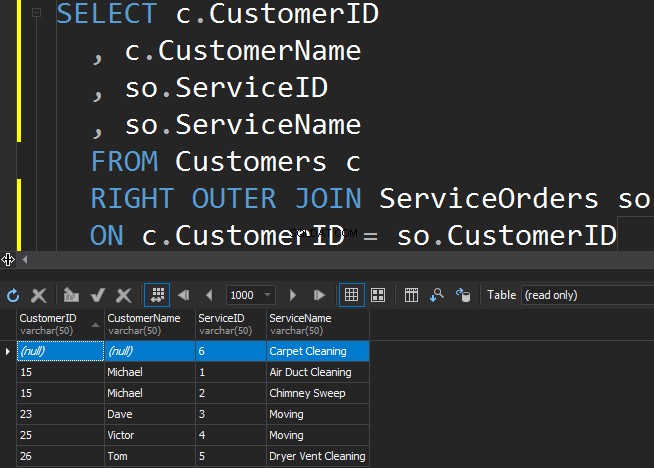
Виждаме, че в този случай SQL Server върна допълнителни редове от дясната таблица, а услугата за почистване на килими никога не е била поръчана.
Използване на FULL OUTER JOIN
Този тип JOIN ви позволява да получите несъответстващата информация, като включите несъответстващи редове от двете таблици.
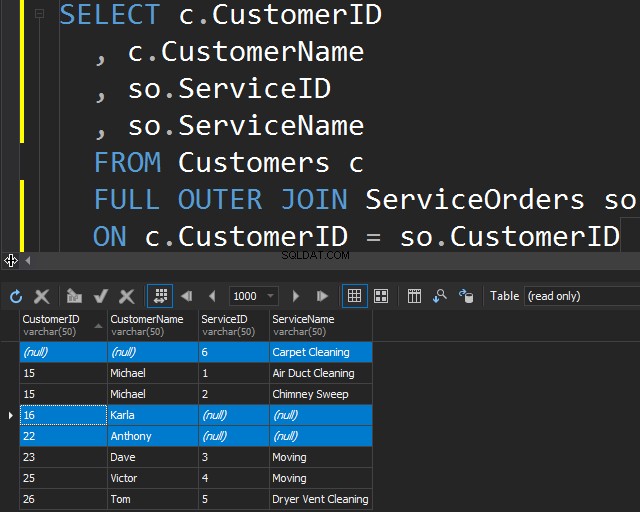
Това също може да е полезно, ако трябва да изчистите данните.
Резюме:
ПЪЛНО ВЪНШНО ПРИСЪЕДИНЕНИЕ
- Връща редове от двете таблици, дори ако не съвпадат с оператора JOIN
НАЛЯВО или ДЯСНО
- Няма разлика, освен в реда на таблиците в клаузата FROM
- Посока сочи към таблица за извличане на несъответстващи редове от
САМО ПРИСЪЕДИНЯВАНЕ
Следващият тип JOIN, който имаме, е SELF JOIN. Това вероятно е вторият най-рядко разпространен тип JOIN, който някога ще изпълните. САМО ПРИСЪЕДИНЯВАНЕ е, когато присъединявате маса към себе си. Най-общо казано, това е знак за лош дизайн. За да използвате една и съща таблица два пъти в една заявка, таблицата трябва да има псевдоним. Псевдонимът помага на процесора на заявки да идентифицира дали колоните трябва да представят данни от дясната или лявата страна. Освен това трябва да премахнете редовете, които маршируват сами. Това обикновено се прави с неравностойно присъединяване.
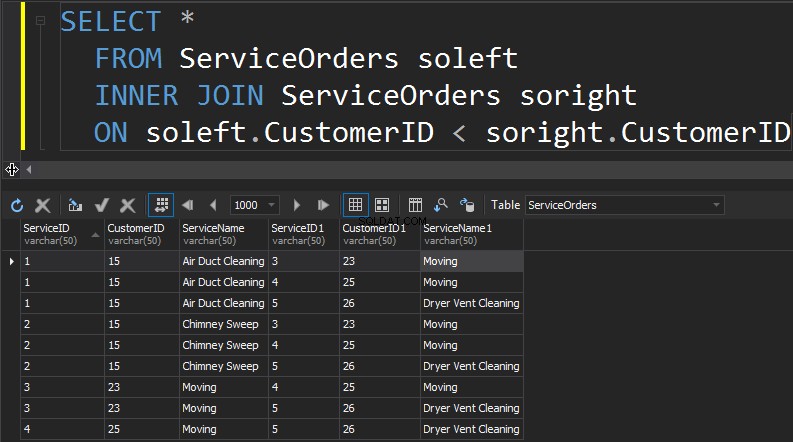
Резюме:
- Присъединява таблица към себе си
- Общо взето знак за лош дизайн и нормализиране
- Таблиците трябва да имат псевдоним
- Трябва да се филтрират редове, които съвпадат сами
КРЪСТО СЪЕДИНЯВАНЕ
Този тип JOIN няма ON изявление. Всеки ред от всяка таблица ще съвпада. Това е известно още като декартов продукт (в случай, че CROSS JOIN няма клауза WHERE). Едва ли ще използвате този тип JOIN в реални сценарии, но това е добър начин за генериране на тестови данни.
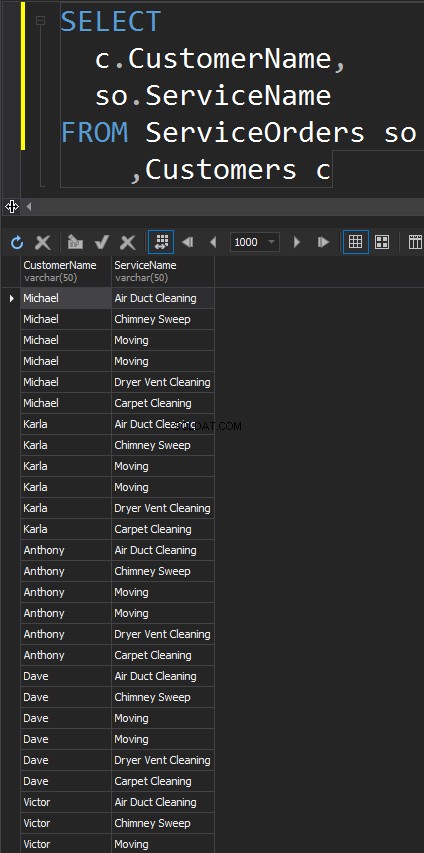
Резултатът е набор от данни, където броят на редовете в лявата таблица се умножава по броя на редовете в дясната таблица. В крайна сметка виждаме, че всеки отделен клиент отговаря на всяка отделна услуга.
Получаваме същия резултат, когато използваме изрично клаузата CROSS JOIN.
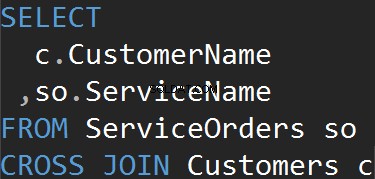
Резюме:
- Всички редове съвпадат от всяка таблица
- Няма изявление ON
- Може да се използва за генериране на тестови данни
АЛГОРИТМИ ЗА ПРИСЪЕДИНЕНЕ
В първата част на статията сме обсъдилилогично JOIN оператори, които SQL Server използва при анализиране и обвързване на заявки. Те са:
- INNER JOIN
- ВЪНШНО ПРИСЪЕДИНЕНИЕ
- Кръстосано присъединяване
Логическите оператори са концептуални и се различават отфизическите JOINs. Иначе казано, логическите JOINвсъщност не се присъединяват конкретни колони на таблицата. Едно логическо JOIN може да съответства на много физически JOIN. SQL Server замества логическите JOIN с физически JOIN по време на оптимизация. SQL Server има следните физически JOIN оператори:
- ВГЛАЖЕН LOOP
- СЛИВАНЕ
- ХАШ
Потребител не пише и не използва тези типове JOINS. Те са част от двигателя на SQL Server и SQL Server ги използва вътрешно за прилагане на логически JOIN. Когато изследвате плана за изпълнение, може да забележите, че SQL Server замества логическите JOIN оператори с един от трите физически оператора.
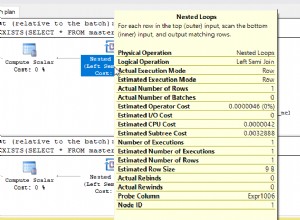
Присъединяване на вложен цикъл
Нека започнем от най-простия оператор, който е Nested Loop. Алгоритъмът сравнява всеки отделен ред от една таблица (външна таблица) с всеки ред от другата таблица (вътрешна таблица), търсейки редове, които отговарят на предиката JOIN.
Следният псевдокод описва вътрешния вложен алгоритъм за свързване:

Следният псевдокод описва външния вложен алгоритъм за свързване:
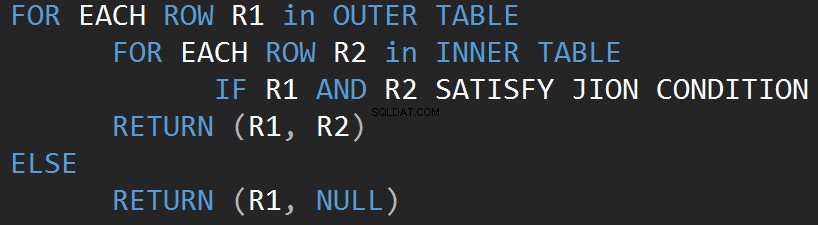
Размерът на входа пряко влияе върху цената на алгоритъма. Входът расте, цената също расте. Този тип JOIN алгоритъм е ефективен в случай на малък вход. SQL Server оценява JOIN предикат за всеки ред и в двата входа.
Разгледайте следната заявка като пример, която получава клиенти и техните поръчки.
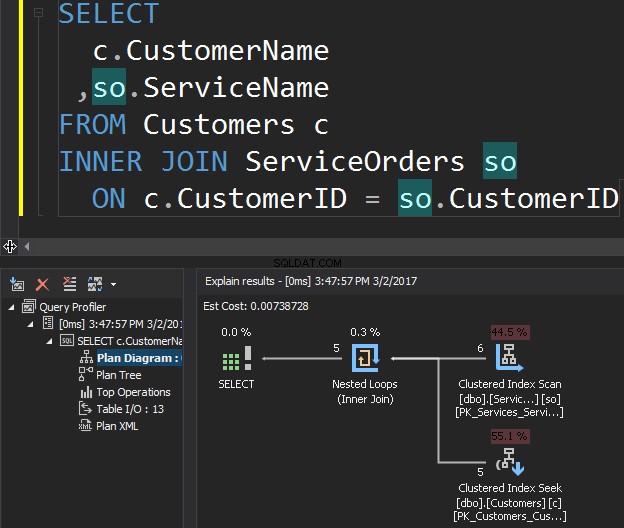
Операторът Clustered Index Scan е външният вход и Clustered Index Seek е вътрешният вход . Операторът Nested Loop всъщност намира съвпадение. Операторът търси всеки запис във външния вход и намира съвпадащи редове във вътрешния вход. SQL Server изпълнява операцията Clustered Index Scan (външен вход) само веднъж, за да получи всички съответни записи. Клъстеризираното търсене на индекс се изпълнява за всеки запис от външния вход. За да потвърдите това, придвижете курсора до иконата на оператор и разгледайте подсказката.
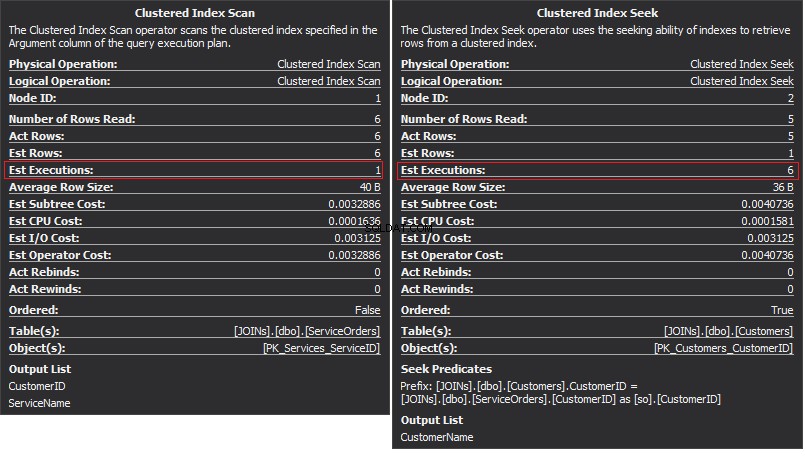
Нека поговорим за сложността. Да предположим, че N е номерът на реда за външния изход. М е общият номер на ред в Поръчки за продажба маса. Следователно, сложността на заявката е O(NLogM) където LogM е сложността на всяко търсене във вътрешния вход. Оптимизаторът ще избира този оператор всеки път, когато външният вход е малък и вътрешният вход съдържа индекс в колоната, който действа като шев. Следователно индексите и статистическите данни са от съществено значение за този тип JOIN, в противен случай SQL Server може случайно да си помисли, че няма толкова много редове в един от входните данни. По-добре е да извършите едно сканиране на таблица, вместо да извършвате търсене на индекс 100K пъти. Особено когато вътрешният входен размер е повече от 100K.
Резюме:
Вложени цикли
- Сложност:O(NlogM)
- Прилага се обикновено, когато една маса е малка
- По-голямата таблица съдържа индекс, който позволява търсенето й с помощта на ключа за присъединяване
Сливане на присъединяване
Някои разработчици не разбират напълно хеш и сливане JOIN и често ги свързват с неефективни заявки.
За разлика от вложен цикъл, който приема всеки предикат JOIN, Merge Join изисква поне едно equi присъединяване. Освен това и двата входа трябва да бъдат сортирани по клавишите JOIN.
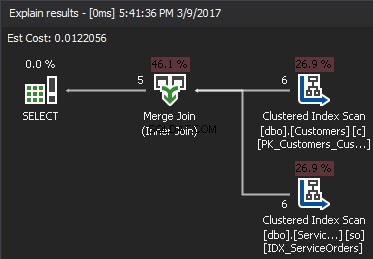
Псевдокодът за алгоритъма MERGE JOIN:
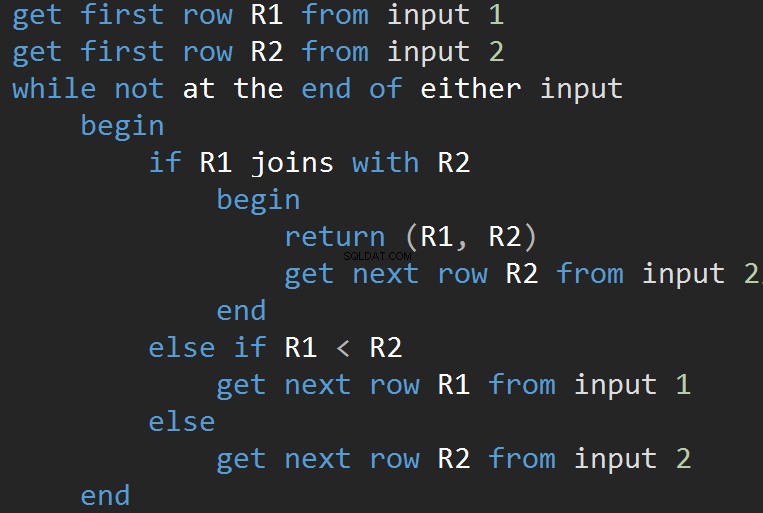
Алгоритъмът сравнява два сортирани входа. Един ред наведнъж. В случай, че има равенство между два реда, алгоритъмът извежда обединяване на редове и продължава. Ако не, алгоритъмът отхвърля по-малкия от двата входа и продължава. За разлика от вложения цикъл, цената тук е пропорционална на сумата от броя на входните редове. По отношение на сложността –O(N+M). Следователно този тип JOIN често е по-добър за големи входове.
Следващата анимация демонстрира как алгоритъмът MERGE JOIN всъщност свързва редовете на таблицата.
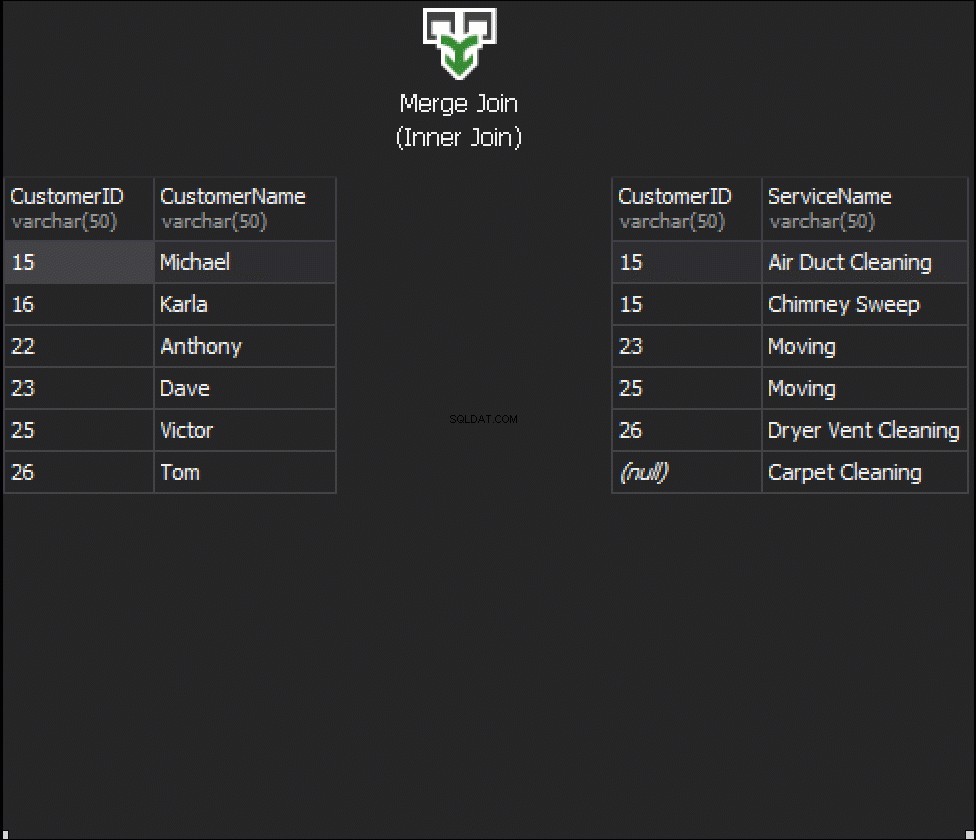
Резюме
- Сложност:O(N+M)
- И двата входа трябва да бъдат сортирани по ключа за присъединяване
- Използва се оператор за равенство
- Отличен за големи маси
Присъединяване към хеш
Hash Join е много подходящ за големи таблици без използваем индекс. На първата стъпка – фаза на изграждане алгоритъмът създава хеш индекс в паметта на входа отляво. Втората стъпка се наричафаза на сонда . Алгоритъмът преминава през десния вход и намира съвпадения, използвайки индекса, създаден по време на фазата на изграждане. Ако кажете истината, не е добър знак, когато оптимизаторът избере този тип JOIN алгоритъм.
Има две важни концепции, залегнали в основата на този тип JOIN:хеш функция и хеш таблица.
хеш функция е всяка функция, която може да се използва за картографиране на данни с променлив размер към данни с фиксиран размер.
Хеш таблица е структура от данни, използвана за реализиране на асоциативен масив, структура, която може да съпоставя ключове със стойности. Хеш таблицата използва хеш функция, за да изчисли индекс в масив от сегменти или слотове, от които може да се намери желаната стойност.
Въз основа на наличните статистически данни SQL Server избира най-малкия вход като вход за изграждане и го използва за изграждане на хеш таблица в паметта. Ако няма достатъчно памет, SQL Server използва физическо дисково пространство в TempDB. След като хеш таблицата е създадена, SQL Server получава данните от входа на сондата (по-голяма таблица) и ги сравнява с хеш таблицата с помощта на функция за съвпадение на хеш. В резултат на това връща съвпадащи редове.
Ако погледнем плана за изпълнение, десният горен елемент е входът за изграждане , а десният долен елемент е входът на сондата . В случай, че и двата входа са изключително големи, цената е твърде висока.
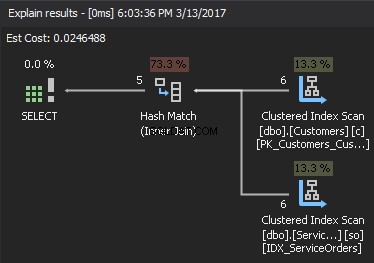
За да оцените сложността, приемете следното:
hc – сложност на създаването на хеш таблица
чm – сложност на хеш функцията за съвпадение
N – по-малка маса
М – по-голяма маса
J – добавяне на сложност за динамично изчисление и създаване на хеш функция
Сложността ще бъде:O(N*hc). + M*hm + J)
Оптимизаторът използва статистически данни, за да определи кардиналността на стойността. След това динамично създава хеш функция, която разделя данните на много кофи с еднакви размери. Често е трудно да се оцени сложността на процеса на създаване на хеш таблицата, както и сложността на всяко съвпадение на хеш поради динамичен характер. Планът за изпълнение може дори да показва неправилни оценки, тъй като оптимизаторът изпълнява всички тези динамични операции по време на времето за изпълнение. В някои случаи планът за изпълнение може да покаже, че Nested Loop е по-скъп от Hash Join, но всъщност Hash Join се изпълнява по-бавно поради неправилната оценка на разходите.
Резюме
- Сложност:O(N*hc). +М*чm +J)
- Тип на присъединяване от последна инстанция
- Използва хеш таблица и динамична хеш функция за съпоставяне на редове
Полезни продукти:
SQL Complete – пишете, разкрасявайте, преобразувайте кода си лесно и увеличете производителността си.