Това е първата статия от поредица от статии за In-Memory OLTP. Помага ви да разберете как новият двигател на Hekaton работи вътрешно. Ще се съсредоточим върху подробностите за оптимизирани в паметта таблици и индекси. Това е статията от начално ниво, което означава, че не е необходимо да сте експерт по SQL Server, но трябва да имате някои основни познания за традиционния двигател на SQL Server.
Въведение
Двигателят на SQL Server 2014 In-Memory OLTP (проект Hekaton) е създаден от самото начало, за да използва терабайти налична памет и огромен брой ядра за обработка. In-Memory OLTP позволява на потребителите да работят с оптимизирани за паметта таблици и индекси и собствено компилирани съхранени процедури. Можете да го използвате заедно с базираните на диск таблици и индекси и T-SQL съхранените процедури, които SQL Server винаги е предоставял.
Вътрешността и възможностите на OLTP двигателя в паметта се различават значително от стандартния релационен двигател. Трябва да преразгледате почти всичко, което знаехте за това как се обработват множество едновременни процеси.
Двигателят на SQL Server е оптимизиран за дисково съхранение. Той чете 8KB страници с данни в паметта за обработка и записва 8KB страници с данни обратно на диска след модификации. Разбира се, SQL Server най-вече коригира промените на диска в дневника на транзакциите. Четенето на 8 KB страници с данни от диска и записването им обратно може да генерира много I/O и води до по-висока цена на латентност. Дори когато данните са в буферния кеш, SQL сървърът е проектиран да приеме, че не е, което води до неефективно използване на процесора.
Имайки предвид ограниченията на традиционните дисково-базирани структури за съхранение, екипът на SQL Server започна изграждането на база данни, оптимизирана за голяма основна памет и многоядрени процесори. Отборът си постави следните цели:
- Оптимизиран за данни, които се съхраняват изцяло в паметта, но също така са издръжливи при рестартиране на SQL Server
- Напълно интегриран в съществуващия двигател на SQL Server
- Много висока производителност за OLTP операции
- Проектиран за съвременни процесори
OLTP в паметта на SQL Server отговаря на всички тези цели.
Относно OLTP в паметта
SQL Server 2014 In-Memory OLTP предоставя редица технологии за работа с оптимизирани за памет таблици, заедно с таблици, базирани на диск. Например, той ви позволява да получите достъп до данни в паметта, като използвате стандартни интерфейси като T-SQL и SSMS. Следващата илюстрация демонстрира оптимизирани за паметта таблици и индекси, като част от In-Memory OLTP (отляво) и дисково-базирани таблици (вляво), които изискват четене и запис на 8KB страници с данни. In-Memory OLTP също така поддържа компилирани в оригинал съхранени процедури и предоставя нов OLTP компилатор в паметта.
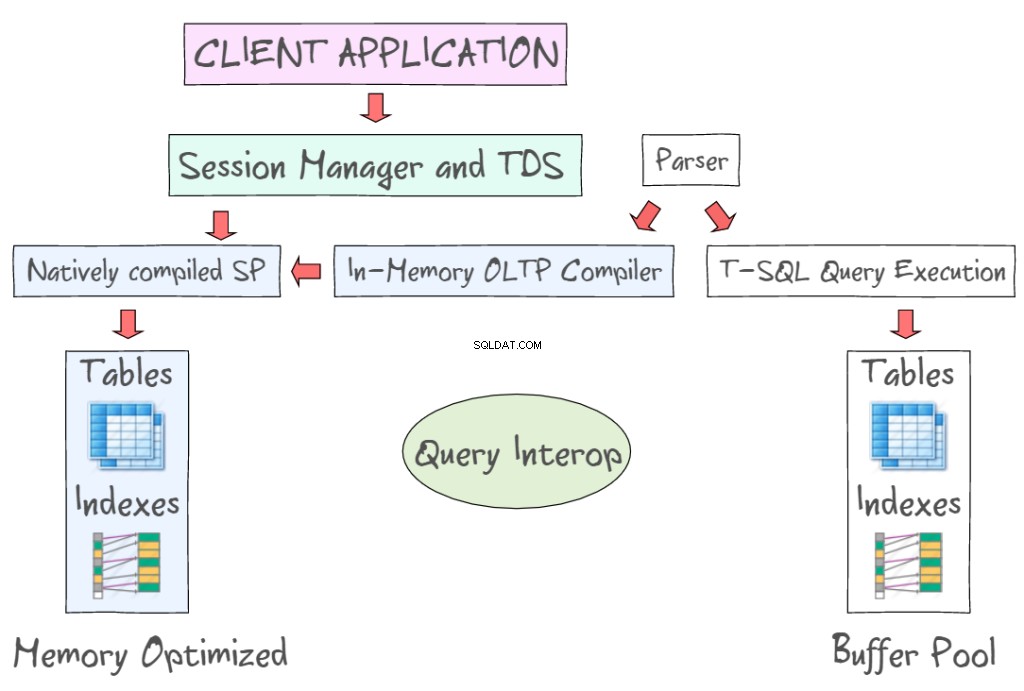
Query Interop позволява интерпретирането на T-SQL за справка с оптимизирани за памет таблици. Ако транзакция се позовава както на оптимизирани за памет, така и на базирани на диск таблици, тя може да се посочи като транзакция между контейнери. Клиентското приложение използва табличен поток от данни – протокол на приложния слой, използван за прехвърляне на данни между сървър на база данни и клиент. Първоначално е проектиран и разработен от Sybase Inc. за техния двигател за релационна база данни Sybase SQL Server през 1984 г., а по-късно от Microsoft в Microsoft SQL Server.
Таблици, оптимизирани за памет
Докато осъществявате достъп до базирани на диск таблици, необходимите данни може вече да са в паметта, въпреки че може да не са. Ако данните не са в паметта, SQL Server трябва да ги прочете от диска. Най-основната разлика при използването на оптимизирани за памет таблици е, че цялата таблица и нейните индекси се съхраняват в паметта през цялото време . Едновременните операции с данни не изискват заключване или заключване.
Докато потребителят променя данните в паметта, SQL Server извършва някои дискови I/O за всяка таблица, която трябва да бъде издръжлива, иначе казано, където се нуждаем от таблица, за да запазим данните в паметта по време на срив на сървъра или рестартиране.
Структура за съхранение, базирана на редове
Друга съществена разлика е основната структура за съхранение. Базираните на диск таблици са оптимизирани за блоково адресиране дисково съхранение, докато оптимизираните в паметта таблици са оптимизирани за адресиране с байтове памет.
SQL Server поддържа редове с данни в 8K страници с данни, с разпределение на пространство от екстенти за базирани на диск таблици. Страницата с данни е основната единица за съхранение на диск и памет. Докато чете и записва данни от диск, SQL Server чете и записва само съответните страници с данни. Страница с данни ще съдържа само данни от една таблица или индекс. Приложните процеси променят редове на различни страници с данни според изискванията. По-късно, по време на операцията CHECKPOINT, SQL Server първо коригира регистрационните записи на диск и след това записва всички мръсни страници на диска. Тази операция често причинява много произволни физически I/O.
За оптимизирани за паметта таблици няма страници с данни, както и екстенти. Има само редове с данни, записани в паметта последователно, в реда на извършване на транзакциите. Всеки ред съдържа индекс указател към следващия ред. Всички I/O са сканиране в паметта на тези структури. Няма представа за записване на редове с данни на определено място, което принадлежи на конкретен обект. Въпреки това, не е нужно да мислите, че оптимизираните за памет таблици се съхраняват като неорганизиран набор от редове с данни (подобно на дисково-базирани купчини). Всеки израз CREATE TABLE за оптимизирана за памет таблица създава поне един индекс, който SQL Server използва за свързване на всички редове с данни в тази таблица.
Всеки отделен ред с данни се състои от заглавката на реда и полезния товар, който е действителните данни на колоната. Заглавката съхранява информация за израза, създал реда, указатели за всеки индекс в целевата таблица и стойности на времеви отпечатъци. Timestamp показва времето, в което транзакцията е вмъкнала и изтрила ред. Записите на SQL Server се актуализират чрез вмъкване на нова версия на ред и маркиране на старата версия като изтрита. Няколко версии на един и същи ред могат да съществуват по всяко време. Това позволява едновременен достъп до един и същи ред по време на промяната на данните. SQL Server показва версията на реда, свързана с всяка транзакция, според момента, в който транзакцията е започнала, спрямо времевите отпечатъци на версията на реда. Това е ядрото на новия контрол на едновременното използване на няколко версии механизъм за таблици в паметта.
Между другото, Oracle има отлична система за управление с няколко версии. По принцип работи по следния начин:
- Потребител A стартира транзакция и актуализира 1000 реда с някаква стойност в момент T1.
- Потребител Б чете същите 1000 реда в момент T2.
- Потребител А актуализира ред 565 със стойност Y (първоначалната стойност беше X).
- Потребител Б достига ред 565 и открива, че транзакцията е в действие от времето Т1.
- Базата данни връща немодифицирания запис от регистрационните файлове. Върнатата стойност е стойността, която е била записана в момента, по-малка или равна на T2.
- Ако записът не може да бъде извлечен от регистрационните файлове за повторно изпълнение, това означава, че базата данни не е настроена по подходящ начин. Трябва да се отдели повече място за регистрационните файлове.
- Върнатите резултати винаги са едни и същи по отношение на началния час на транзакцията. Така че в рамките на транзакцията се постига последователност на четене.
Собствено компилирани таблици
Последната основна разлика е, че оптимизираните в паметта таблици са нативно компилирани . Когато потребителят създаде оптимизирана за памет таблица или индекс, SQL Server съхранява структурата на всяка таблица (заедно с всички индекси) в метаданните. По-късно SQL Server използва тези метаданни, за да компилира в DDL набор от рутинни програми на роден език за достъп до таблицата. Такива DDL са свързани с базата данни, но всъщност не са част от нея.
С други думи, SQL Server съхранява в паметта не само таблици и индекси, но и DDL за достъп и промяна на тези структури. След като таблицата е променена, SQL Server трябва да пресъздаде всички DDL за операции с таблица. Ето защо не можете да променяте таблица, веднъж създадена. Тези операции са невидими за потребителите.
Нативно компилирани съхранени процедури
Най-добрата производителност се постига, като се използват естествено компилирани съхранени процедури за достъп до собствено компилирани таблици. Такива процедури съдържат инструкции на процесора и могат да се изпълняват директно от процесора без допълнителна компилация. Въпреки това, има някои ограничения върху T-SQL конструкциите за нативно компилираните съхранени процедури (в сравнение с традиционно интерпретирания код). Друг важен момент е, че нативно компилираните съхранени процедури могат да имат достъп само до оптимизирани за паметта таблици.
Без ключалки
In-Memory OLTP е система без заключване. Това е възможно, защото SQL Server никога не променя нито един съществуващ ред. Операцията UPDATE създава новата версия и маркира предишната версия като изтрита. След това вмъква нова версия на ред с нови данни вътре.
Индекси
Както може би се досещате, индексите са много различни от традиционните. Оптимизираните в паметта таблици нямат страници. SQL Server използва индекси, за да свърже всички редове, които принадлежат на таблица, в една структура. Не можем да използваме израза CREATE INDEX, за да създадем индекс за оптимизираната в паметта таблица. След като създадете ПЪРВИЧНИЯ КЛЮЧ в колона, SQL Server автоматично създава уникален индекс за тази колона. Всъщност това е единственият разрешен уникален индекс. Можете да създадете максимум осем индекса в оптимизирана за памет таблица.
По аналогия с таблиците, SQL Server поддържа оптимизирани за памет индекси в паметта. Въпреки това, SQL Server никога не регистрира операции върху индекси. SQL Server поддържа индекси автоматично по време на модификации на таблици.
Оптимизираните за памет таблици поддържат два типа индекси:хеш индекс и индекс на диапазон . И двете са неклъстерирани структури.
хеш индексът е нов тип индекс, създаден специално за оптимизирани за памет таблици. Той е изключително полезен за извършване на справки на конкретни стойности. Самият индекс се съхранява като хеш таблица. Това е масив от хеш кофи, където всяка кофа е указател към един ред.
Индексът на диапазона (неклъстериран) е полезен за извличане на диапазони от стойности.
Възстановяване
Основният механизъм за възстановяване на база данни с оптимизирани за памет таблици е същият като механизма за възстановяване на бази данни с дискови таблици. Въпреки това, възстановяването на оптимизирани с памет таблици включва стъпката на зареждане на оптимизираните за памет таблици в паметта, преди базата данни да е налична за потребителски достъп.
Когато SQL Server се рестартира, всяка база данни преминава през следните фази на процеса на възстановяване:анализ ,повтори , и отмяна .
На фазата на анализ OLTP машината в паметта идентифицира инвентара на контролните точки за зареждане и предварително зарежда записите в регистрационния файл на системната таблица. Той също така ще обработи някои записи в дневника за разпределение на файлове.
На фазата на повторно изпълнение данните от двойките данни и делта файлове се зареждат в паметта. След това данните се актуализират от активния регистър на транзакциите въз основа на последната трайна контролна точка и таблиците в паметта се попълват и индексите се изграждат отново. По време на тази фаза възстановяването на таблици, базирано на диск и оптимизирана за памет, се изпълняват едновременно.
Фазата на отмяна не е необходима за оптимизирани с памет таблици, тъй като OLTP в паметта не записва никакви незаети транзакции за оптимизирани с памет таблици.
Когато всички операции са завършени, базата данни е достъпна за достъп.
Резюме
В тази статия разгледахме набързо OLTP двигателя на SQL Server в паметта. Научихме, че оптимизираните за памет структури се съхраняват в паметта. Приложните процеси могат да намерят необходимите данни чрез достъп до тези структури в паметта, без да е необходим дисков вход/изход. В следващите статии ще разгледаме как да създавате и осъществявате достъп до OLTP бази данни и таблици в паметта.
Допълнително четене
OLTP в паметта:Какво е новото в SQL Server 2016
Използване на индекси в оптимизирани за паметта таблици на SQL Server