Вашият въпрос е наистина неточен. Моля, следвайте предложенията на @RiggsFolly и прочетете препратките за това как да зададете добър въпрос.
Освен това, както предлага @DuduMarkovitz, трябва да започнете с опростяване на проблема и почистване на вашите данни. Няколко ресурса, за да започнете:
- Урок за основна обработка на текст от Мат Дени
- Обработка и обработка на низове в R от Гастон Санчес
След като сте доволни от резултатите, можете да продължите да идентифицирате група за всяка Var1 запис (това ще ви помогне по-нататък да извършите по-нататъшен анализ/манипулации на подобни записи) Това може да се направи по много различни начини, но както е споменато от @GordonLinoff, единият вероятно е разстоянието на Levenshtein.
Забележка :за 50K записи резултатът няма да е 100% точен, тъй като няма винаги категоризирайте термините в подходящата група, но това трябва значително да намали ръчните усилия.
В R можете да направите това с помощта на adist()
Използвайки вашите примерни данни:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
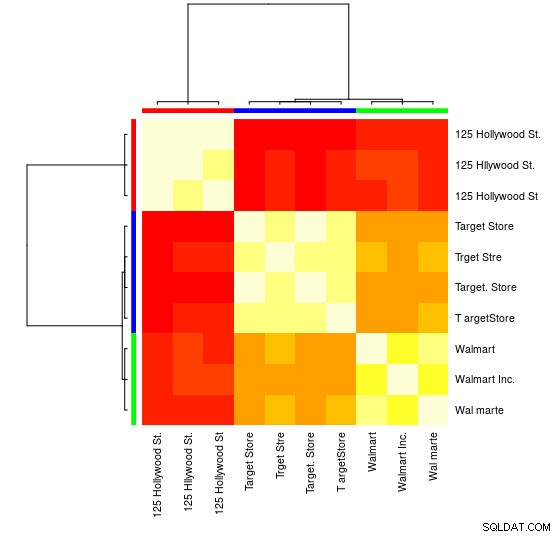
За тази малка извадка можете да видите 3-те отделни групи (клъстерите с ниски стойности на разстоянието на Левенщайн) и можете лесно да ги присвоите ръчно, но за по-големи групи вероятно ще ви е необходим алгоритъм за групиране.
Вече ви посочих в коментарите към един от моите предишен отговор
показва как да направите това с помощта на hclust() и метода на минималната вариация на Ward, но мисля, че тук ще е по-добре да използвате други техники (един от любимите ми ресурси по темата за бърз преглед на някои от най-широко използваните методи в R е този подробен отговор
)
Ето пример за използване на клъстериране на афинитетно разпространение:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Ще намерите в обекта APResult d_ap елементите, свързани с всеки клъстер и оптималния брой клъстери, в този случай:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Можете също да видите визуално представяне:
> heatmap(d_ap, margins = c(10, 10))
След това можете да извършите допълнителни манипулации за всяка група. Като пример тук използвам hunspell за търсене на всяка отделна дума от Var1 в en_US речник за правописни грешки и се опитайте да намерите във всяка group , който id няма правописни грешки (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Което дава:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Забележка :Тук, тъй като не сме извършили обработка на текст, резултатите не са много убедителни, но схващате идеята.
Данни
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)