Ето какво се случва.
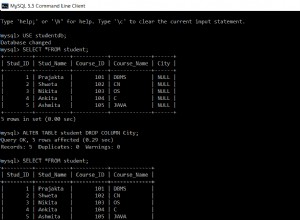
The SELECT COUNT (...) icd_index where icd='25000'
ще използва индекса, който е BTree, отделен от данните. Но го сканира по следния начин:
- Намерете първия запис с icd='25000'. Това става почти мигновено.
- Сканиране напред, докато ако намери промяна в icd. Това ще сканира само в индекса, без да докосва данните. Според EXPLAIN ще има около 910 104 индексни записа за сканиране.
Сега нека да разгледаме BTree за този индекс. Въз основа на полетата в индекса, всеки ред ще бъде точно 22 байта, плюс ще има някои допълнителни разходи (приблизително 40%). Индексният блок на MyISAM е 1KB (вж. 16KB на InnoDB). Бих оценил 33 реда на блок. 910,104/33 казва, че трябва да се прочетат около 27K блока, за да се направи БРОЯ. (Забележка COUNT(core_id) трябва да провери core_id за нула, COUNT(*) не; това е незначителна разлика.) Четенето на 27K блокове на обикновен твърд диск отнема около 270 секунди. Имахте късмета да го направите за 60 секунди.
Второто изпълнение намери всички тези блокове в key_buffer (ако приемем, че key_buffer_size е поне 27MB), така че не трябваше да чака диска. Следователно беше много по-бързо. (Това игнорира кеша на заявките, който имахте мъдростта да изчистите или да използвате SQL_NO_CACHE.)
5.6 случайно е без значение (но благодаря, че го споменахте), тъй като този процес не се е променил от 4.0 или преди (с изключение на това, че utf8 не съществува; повече за това по-долу).
Преминаването към InnoDB би помогнало по няколко начина. ПЪРВИЧНИЯТ КЛЮЧ ще бъде „групиран“ с данните, а не да се съхранява като отделно BTree. Следователно, след като данните или PK бъдат кеширани, другият е незабавно достъпен. Броят на блоковете ще бъде по-скоро 5K, но те ще бъдат 16KB блокове. Те може да се зареждат по-бързо, ако кешът е студен.
Питате „Имам ли нужда от индекс само на icd?“ -- Е, това ще намали размера на MyISAM BTree до около 21 байта на ред, така че BTree ще бъде около 21/27 от размера, без много подобрение (поне за ситуация на студен кеш).
Друга мисъл е, ако icd винаги е цифрово и винаги числово, за да използвате MEDIUMINT UNSIGNED и закрепете ZEROFILL ако може да има водещи нули.
Ами сега, не успях да забележа НАБОРА ЗНАЦИ. (Поправих числата по-горе, но позволете ми да поясня.)
- CHAR(5) позволява 5 знака .
- ascii отнема 1 байт на символ .
- utf8 отнема до 3 байта на знаци .
- И така, CHAR(5) CHARACTER SET utf8 отнема 15 байта винаги .
Промяна на колоната на CHAR(5) CHARACTER SET ascii ще го свие до 5 байта.
Промяната му на MEDIUMINT UNSIGNED ZEROFILL ще го свие до 3 байта.
Свиването на данните би ускорило I/O с приблизително пропорционална сума (след като позволи още 6 байта за другите две полета.