В PostgreSQL точно това, което ще получите тук, зависи от основната таблица, така че трябва да използвате EXPLAIN ANALYZE за някои примерни заявки срещу полезен подмножество от вашите данни, за да разберете какво точно ще направи оптимизаторът (уверете се, че таблиците, които сте са АНАЛИЗИРАНИ също). IN може да бъде обработен по няколко различни начина и затова трябва да разгледате някои проби, за да разберете коя алтернатива се използва за вашите данни. Няма прост общ отговор на вашия въпрос.
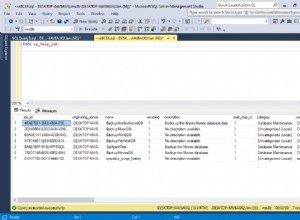
Що се отнася до конкретния въпрос, който добавихте във вашата ревизия, срещу тривиален набор от данни без включени индекси, ето пример за двата плана за заявки, които ще получите:
postgres=# explain analyze select * from x where s in ('123','456');
Seq Scan on x (cost=0.00..84994.69 rows=263271 width=181) (actual time=0.015..1819.702 rows=247823 loops=1)
Filter: (s = ANY ('{123,456}'::bpchar[]))
Total runtime: 1931.370 ms
postgres=# explain analyze select * from x where s='123' or s='456';
Seq Scan on x (cost=0.00..90163.62 rows=263271 width=181) (actual time=0.014..1835.944 rows=247823 loops=1)
Filter: ((s = '123'::bpchar) OR (s = '456'::bpchar))
Total runtime: 1949.478 ms
Тези две времена на изпълнение са по същество идентични, тъй като реалното време за обработка е доминирано от последователното сканиране в таблицата; извършване на няколко пъти показва разликата между двете е под границата на грешка при стартиране за изпълнение. Както можете да видите, PostgreSQL трансформира случая IN в използване на своя ВСЯК филтър, който винаги трябва да се изпълнява по-бързо от серия от ИЛИ. Отново, този тривиален случай не е непременно представителен за това, което ще видите при сериозна заявка, в която участват индекси и други подобни. Независимо от това, ръчната замяна на INs с поредица от оператори OR никога не трябва да бъде по-бърза, защото оптимизаторът знае най-доброто нещо, което трябва да направи тук, ако има добри данни, с които да работи.
Като цяло PostgreSQL знае повече трикове за оптимизиране на сложни заявки, отколкото MySQL оптимизатора, но също така разчита в голяма степен на това, че сте предоставили на оптимизатора достатъчно данни, с които да работи. Първите връзки в секцията „Оптимизация на производителността“ на уикито на PostgreSQL обхващат най-важните неща, необходими за получаване на добри резултати от оптимизатора.