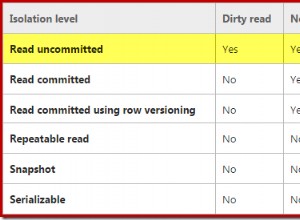
Данните ви са лошо клъстерирани .
InnoDB ще съхранява редове с "близки" PK физически близо един до друг. Тъй като вашите дъщерни таблици използват сурогатни PK, техните редове ще се съхраняват на случаен принцип. Когато дойде време да се направят изчисления за дадения ред в "главната" таблица, СУБД трябва да прескача навсякъде, за да събере свързаните редове от дъщерните таблици.
Вместо сурогатни ключове, опитайте да използвате по-„естествени“ ключове с PK на родителя в предния край, подобно на това:
score_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
created: DATETIME
amount: INT(4)
PRIMARY KEY (entry_id, created)
rating_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
rating_no: INT(11)
rating: DOUBLE
PRIMARY KEY (entry_id, rating_no)
ЗАБЕЛЕЖКА:Това предполага created Резолюцията на 's е достатъчно добра и rating_no беше добавен, за да позволи множество оценки за entry_id . Това е само пример - можете да променяте PK според вашите нужди.
Това ще "принуди" редове, принадлежащи на същия entry_id да се съхраняват физически близо един до друг, така че SUM или AVG могат да бъдат изчислени само чрез сканиране на диапазон на PK/кластерния ключ и с много малко I/Os.
Като алтернатива (напр. ако използвате MyISAM, който не поддържа клъстериране), корица заявката с индекси, така че дъщерните таблици изобщо да не се докосват по време на заявката.
На всичкото отгоре можете да денормализирате своя дизайн и да кеширате текущите резултати в родителската таблица:
- Съхранявайте SUM(score_adjustments.amount) като физическо поле и го коригирайте чрез тригери всеки път, когато се вмъкне, актуализира или изтрие ред от
score_adjustments. - Запазете SUM(rating_adjustments.rating) като "S" и COUNT(rating_adjustments.rating) като "C". Когато се добави ред към
rating_adjustments, добавете го към S и увеличете C. Изчислете S/C по време на изпълнение, за да получите средната стойност. Обработвайте актуализациите и изтриванията по подобен начин.