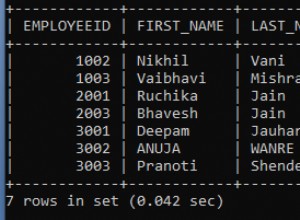
Има много причини средният размер на реда да е висок.
-
Това е приблизително. (Открих, че обикновено е висок 2x-3x.) В един краен случай - един ред в таблицата - ще изисква 16384 байта на ред. Това е един блок InnoDB. Броят на редовете в таблицата е приблизителен . Дисковото пространство, използвано за редовете, е точно, но вижте допълнителните разходи по-долу. Средният размер на реда е частното от тези две.
-
Заглавие на колона -- 1 или 2 байта
-
Разходите на ред -- 20-30 байта -- за обработка на транзакции, намиране на редове в блок и т.н.
-
Изложни разходи на блок -- известен брой байтове на блок от 16 KB
-
Разходите за разбиване в BTree -- мин. е около 1/16 от блока, максимумът е около половината от блока, средният е около 30% след много изтривания и/или произволни вмъквания.
-
Режични разходи за предварително разпределяне на части от дисково пространство (1MB? 8MB?)
-
Тъй като таблицата нараства от поместване в един блок, алгоритъмът на оформлението се измества и процентът на режийните временно нараства.
-
Изтритите редове не връщат мястото си в операционната система, така че размерът на файла остава постоянен, като по този начин увеличава очевидния размер на реда.
-
Ако нямате изричен
PRIMARY KEYилиUNIQUEключ, който може да бъде повишен в PK, тогава има недостъпно 6-байтово поле (на ред) за PK. -
Голям
TEXT/BLOBи дориVARCHARсе съхраняват "извън запис". Това много усложнява изчисленията. И зависи от това кой от 4-теROW_FORMATsизползвате. В някои случаи има 20-байтов "указател" за всяка такава клетка. -
FOREIGN KEYограниченията не добавят към необходимото пространство, освен че могат принудително създаване на индекс. -
INDEXes, различен отPRIMARY KEYне са включени в avg_row_length. -
PRIMARY KEYобикновено включва много малко излишни разходи в данните BTree. Простото правило на палеца е 1% режийни разходи (върху самата колона). Тези режийни разходи са нелистовите възли на BTree. -
Докато транзакцията на InnoDB е заета, всички модифицирани редове се задържат в "списъка на историята". Това води до повече разходи.
-
(Не е напълно свързан).
COMPRESSEDна InnoDB има проблеми - дава само около 2x компресия, за разлика от типичната компресия на текст от 3x. Това струва малко RAM, тъй като трябва да има едновременно компресирани и некомпресирани данни в buffer_pool (поне за някои блокове).
SHOW TABLE STATUS и извличане от information_schema.TABLES дава същите данни. Има начини да получите някои вникване в дълбочината на B+Tree за данните и за всяка таблица.