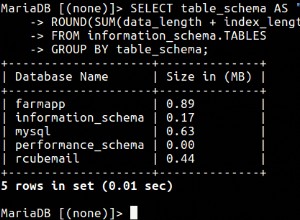
entity-attribute-value модел, който предлагате, може да се побере в този сценарий.
По отношение на заявката за филтриране, трябва да разберете, че с модела EAV ще пожертвате много мощност на заявката, така че това може да стане доста сложно. Това обаче един от начините да се справите с проблема си:
SELECT stuff.id
FROM stuff
JOIN (SELECT COUNT(*) matches
FROM table
WHERE (`key` = X1 AND `value` = V1) OR
(`key` = X2 AND `value` = V2)
GROUP BY id
) sub_t ON (sub_t.matches = 2 AND sub_t.id = stuff.id)
GROUP BY stuff.id;
Една неелегантна характеристика на този подход е, че трябва да посочите броя на двойките атрибут/стойност, които очаквате да съвпадат в sub_t.matches = 2 . Ако имахме три условия, щяхме да трябва да посочим sub_t.matches = 3 , и така нататък.
Нека изградим тестов случай:
CREATE TABLE stuff (`id` varchar(20), `key` varchar(20), `value` varchar(20));
INSERT INTO stuff VALUES ('apple', 'color', 'red');
INSERT INTO stuff VALUES ('mango', 'color', 'yellow');
INSERT INTO stuff VALUES ('banana', 'color', 'yellow');
INSERT INTO stuff VALUES ('apple', 'taste', 'sweet');
INSERT INTO stuff VALUES ('mango', 'taste', 'sweet');
INSERT INTO stuff VALUES ('banana', 'taste', 'bitter-sweet');
INSERT INTO stuff VALUES ('apple', 'origin', 'US');
INSERT INTO stuff VALUES ('mango', 'origin', 'MEXICO');
INSERT INTO stuff VALUES ('banana', 'origin', 'US');
Запитване:
SELECT stuff.id
FROM stuff
JOIN (SELECT COUNT(*) matches, id
FROM stuff
WHERE (`key` = 'color' AND `value` = 'yellow') OR
(`key` = 'taste' AND `value` = 'sweet')
GROUP BY id
) sub_t ON (sub_t.matches = 2 AND sub_t.id = stuff.id)
GROUP BY stuff.id;
Резултат:
+-------+
| id |
+-------+
| mango |
+-------+
1 row in set (0.02 sec)
Сега нека вмъкнем друг плод с color=yellow и taste=sweet :
INSERT INTO stuff VALUES ('pear', 'color', 'yellow');
INSERT INTO stuff VALUES ('pear', 'taste', 'sweet');
INSERT INTO stuff VALUES ('pear', 'origin', 'somewhere');
Същата заявка ще върне:
+-------+
| id |
+-------+
| mango |
| pear |
+-------+
2 rows in set (0.00 sec)
Ако искаме да ограничим този резултат до обекти с origin=MEXICO , ще трябва да добавим още един OR условие и проверете за sub_t.matches = 3 вместо 2 .
SELECT stuff.id
FROM stuff
JOIN (SELECT COUNT(*) matches, id
FROM stuff
WHERE (`key` = 'color' AND `value` = 'yellow') OR
(`key` = 'taste' AND `value` = 'sweet') OR
(`key` = 'origin' AND `value` = 'MEXICO')
GROUP BY id
) sub_t ON (sub_t.matches = 3 AND sub_t.id = stuff.id)
GROUP BY stuff.id;
Резултат:
+-------+
| id |
+-------+
| mango |
+-------+
1 row in set (0.00 sec)
Както при всеки подход, има определени предимства и недостатъци при използването на модела EAV. Уверете се, че проучвате подробно темата в контекста на вашето приложение. Може дори да помислите за алтернативни релационни бази данни, като Cassandra , CouchDB , MongoDB , Voldemort , HBase , SimpleDB или други магазини за ключ-стойност.