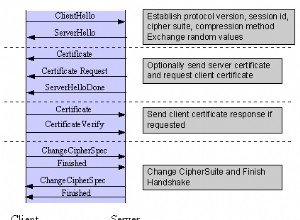
Ако търсите СУБД с много висока производителност и не се нуждаете от нея да е релационна, може да помислите за Cassandra – въпреки че предимствата й влизат в игра само ако имате клъстер от база данни вместо един възел.
Не казахте какви ограничения има за физическата архитектура. Споменахте разделяне, което предполага клъстер. IIRC MySQL клъстерите също поддържат разделяне.
Също така би било много полезно да знаете какво ниво на едновременност е предназначено да поддържа системата и как ще бъдат добавени данни (подаване или пакет).
Казвате „Очевидно не мога да изчислим предварително нито един от резултатите от агрегирането, защото комбинациите от филтри (и следователно наборите от резултати) са огромни.“
Това е най-големият ви проблем и ще бъде най-важният фактор за определяне на производителността на вашата система. Разбира се, не можете да поддържате материализирани изгледи на всяка възможна комбинация, но най-голямата ви печалба от производителност ще бъде поддържането на ограничени предварително обобщени изгледи и изграждането на оптимизатор, който може да намери най-близкото съвпадение. Не е толкова трудно.
В.