Установих, че задавам този въпрос и от всички публикации, които прочетох, никога не открих сравнения на производителността. И така, ето моя опит.
Създадох следните таблици, попълнени с 2 000 000 произволни IP адреса от 100 произволни мрежи.
CREATE TABLE ipv6_address_binary (
id SERIAL NOT NULL AUTO_INCREMENT PRIMARY KEY,
addr BINARY(16) NOT NULL UNIQUE
);
CREATE TABLE ipv6_address_twobigints (
id SERIAL NOT NULL AUTO_INCREMENT PRIMARY KEY,
haddr BIGINT UNSIGNED NOT NULL,
laddr BIGINT UNSIGNED NOT NULL,
UNIQUE uidx (haddr, laddr)
);
CREATE TABLE ipv6_address_decimal (
id SERIAL NOT NULL AUTO_INCREMENT PRIMARY KEY,
addr DECIMAL(39,0) NOT NULL UNIQUE
);
След това ИЗБИРАМ всички ip адреси за всяка мрежа и записвам времето за реакция. Средното време за реакция на таблицата twobigints е около 1 секунда, докато в двоичната таблица е около една стотна от секундата.
Ето запитванията.
SELECT COUNT(*) FROM ipv6_address_twobigints
WHERE haddr & NETMASK_HIGH = NETWORK_HIGH
AND laddr & NETMASK_LOW = NETWORK_LOW
SELECT COUNT(*) FROM ipv6_address_binary
WHERE addr >= NETWORK
AND addr <= BROADCAST
SELECT COUNT(*) FROM ipv6_address_decimal
WHERE addr >= NETWORK
AND addr <= BROADCAST
Средно време за отговор:
Графика:
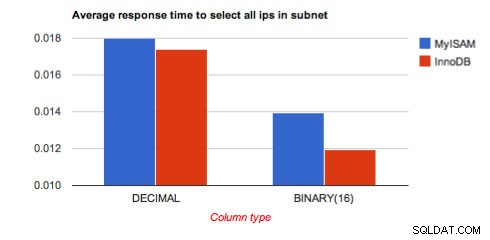
BINARY_InnoDB 0.0119529819489
BINARY_MyISAM 0.0139244818687
DECIMAL_InnoDB 0.017379629612
DECIMAL_MyISAM 0.0179929423332
BIGINT_InnoDB 0.782350552082
BIGINT_MyISAM 1.07809265852