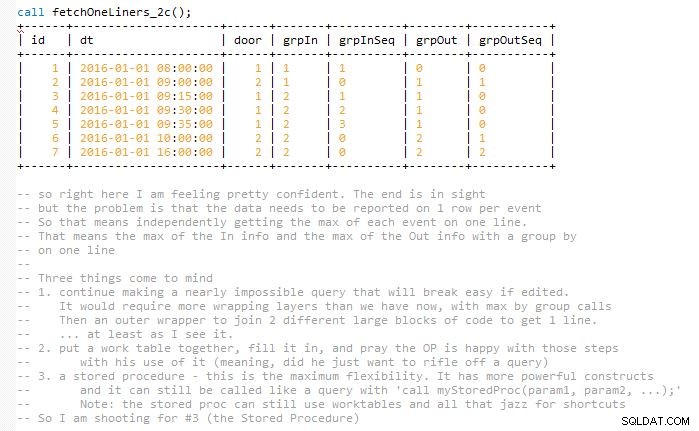
Това се стреми да поддържа решението лесно за поддържане, без да завършва окончателната заявка с един кадър, което би удвоило размера си (според мен). Това е така, защото резултатите трябва да бъдат съвпадащи и представени на един ред със съвпадащи събития за вход и изход. Така че накрая използвам няколко работни маси. Реализира се в съхранена процедура.
Съхранената процедура използва няколко променливи, които се въвеждат с cross join . Мислете за кръстосаното присъединяване като просто за механизъм за инициализиране на променливи. Променливите се поддържат безопасно, така че вярвам, че в духа на този документ
често се споменава в заявки за променливи. Важните части на препратката са безопасната обработка на променливи на ред, принуждавайки те да бъдат зададени преди други колони, които ги използват. Това се постига чрез greatest() и least() функции, които имат по-висок приоритет от променливите, които се задават без използването на тези функции. Забележете също, че coalesce() често се използва за същата цел. Ако използването им изглежда странно, като например вземането на най-голямото от число, за което е известно, че е по-голямо от 0 или 0, това е умишлено. Умишлено при налагане на подреждането по приоритет на задаваните променливи.
Колоните в заявката назовават неща като dummy2 etc са колони, за които изходът не е бил използван, но те са били използвани за задаване на променливи в, да речем, greatest() или друг. Това беше споменато по-горе. Изход като 7777 беше заместител в третия слот, тъй като беше необходима някаква стойност за if() който е бил използван. Така че игнорирайте всичко това.
Включих няколко екранни снимки на кода, докато прогресира слой по слой, за да ви помогна да визуализирате изхода. И как тези итерации на разработка бавно се сгъват в следващата фаза, за да разширят предходната.
Сигурен съм, че моите колеги биха могли да подобрят това с едно запитване. Можех да го завърша по този начин. Но вярвам, че това би довело до объркваща бъркотия, която би се счупила при докосване.
Схема:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Запазена процедура:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Тест:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Това е краят на отговора. По-долу е за визуализация от разработчика на стъпките, довели до завършване на съхранената процедура.
Версии на развитие, които доведоха до края. Надяваме се, че това помага за визуализацията, вместо просто да изпускате объркваща част от код със среден размер.
Стъпка А
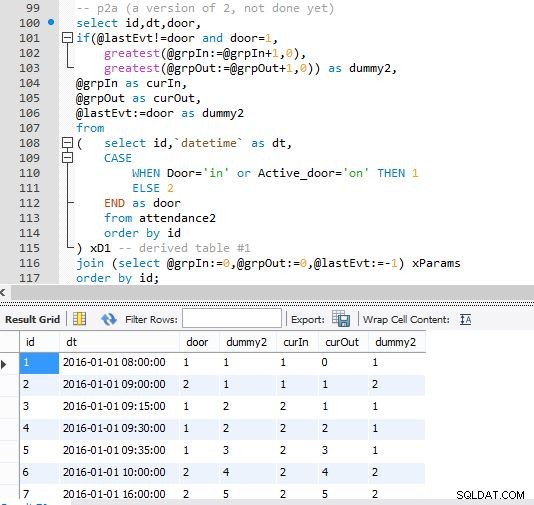
Стъпка Б
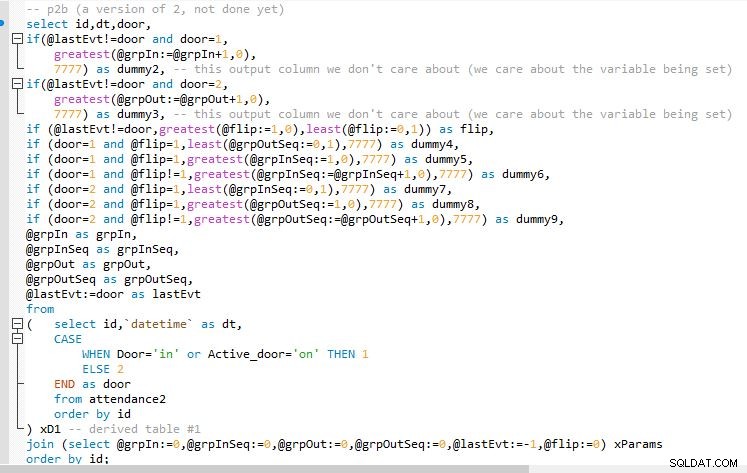
Изход на стъпка Б

Стъпка C
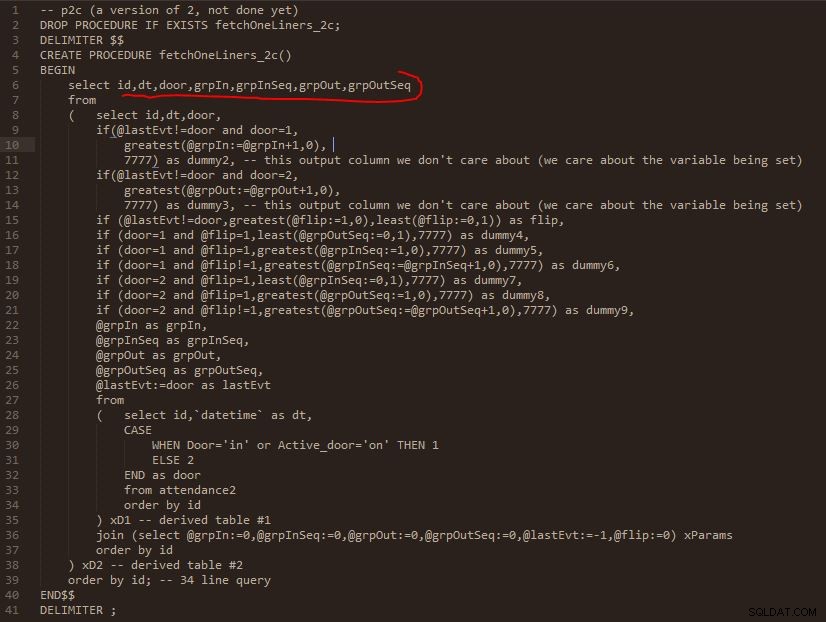
Изход на стъпка C