При работата с имена на хора и правенето на размити търсения върху тях, това, което работи за мен, беше да създам втора таблица с думи. Също така създайте трета таблица, която е пресечна таблица за връзката много към много между таблицата, съдържаща текста, и таблицата с думи. Когато към текстовата таблица се добави ред, вие разделяте текста на думи и попълвате пресечната таблица по подходящ начин, като добавяте нови думи към таблицата с думи, когато е необходимо. След като тази структура е на място, можете да правите търсения малко по-бързо, защото трябва само да изпълнявате функцията си damlev върху таблицата с уникални думи. Едно просто присъединяване ви получава текста, съдържащ съвпадащите думи. 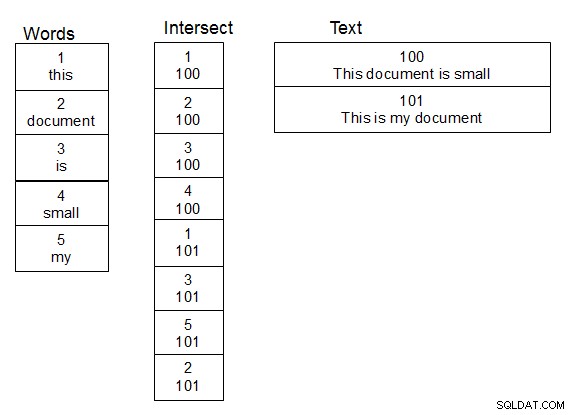
Заявка за съвпадение на една дума би изглеждала така:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
и две думи биха изглеждали така (извън главата ми, така че може да не са точно правилни):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Предимствата тук, с цената на малко пространство в базата данни, са, че трябва само да приложите скъпата във времето функция damlev към уникалните думи, които вероятно ще се броят само в 10-те хиляди, независимо от размера на вашата таблица с текст. Това има значение, тъй като damlev UDF няма да използва индекси - той ще сканира цялата таблица, върху която е приложен, за да изчисли стойност за всеки ред. Сканирането само на уникалните думи трябва да бъде много по-бързо. Другото предимство е, че damlev се прилага на ниво дума, което изглежда е това, което искате. Друго предимство е, че можете да разширите заявката, за да поддържате търсене по множество думи, и можете да класирате резултатите, като групирате съвпадащите пресичащи се редове в TextId и класирате според броя на съвпаденията.