Пример можете да намерите тук:https://github.com/afedulov/routing-data- източник .
Spring предоставя вариант на DataSource, наречен AbstractRoutingDatasource . Той може да се използва вместо стандартни реализации на DataSource и позволява механизъм за определяне кой конкретен DataSource да се използва за всяка операция по време на изпълнение. Всичко, което трябва да направите, е да го разширите и да предоставите реализация на абстрактен determineCurrentLookupKey метод. Това е мястото за прилагане на вашата персонализирана логика за определяне на конкретния източник на данни. Върнатият обект служи като ключ за търсене. Обикновено това е String или en Enum, използван като квалификатор в конфигурацията на Spring (подробностите ще последват).
package website.fedulov.routing.RoutingDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DbContextHolder.getDbType();
}
}
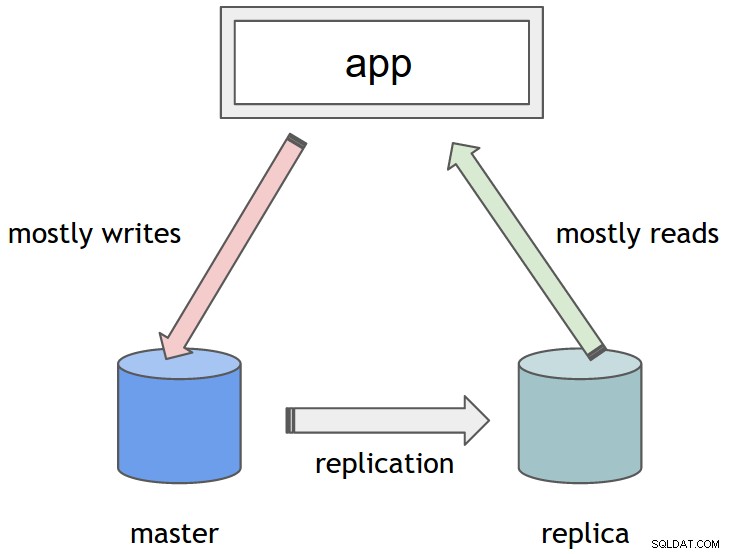
Може би се чудите какъв е този обект DbContextHolder и как той знае кой идентификатор на DataSource да върне? Имайте предвид, че determineCurrentLookupKey методът ще бъде извикан всеки път, когато TransactionsManager поиска връзка. Важно е да запомните, че всяка транзакция е "свързана" с отделна нишка. По-точно TransactionsManager свързва Connection с текущата нишка. Следователно, за да изпращаме различни транзакции към различни целеви източници на данни, ние трябва да се уверим, че всяка нишка може надеждно да идентифицира кой източник на данни е предназначен да бъде използван. Това прави естествено използването на ThreadLocal променливи за обвързване на конкретен DataSource към нишка и следователно към транзакция. Ето как се прави:
public enum DbType {
MASTER,
REPLICA1,
}
public class DbContextHolder {
private static final ThreadLocal<DbType> contextHolder = new ThreadLocal<DbType>();
public static void setDbType(DbType dbType) {
if(dbType == null){
throw new NullPointerException();
}
contextHolder.set(dbType);
}
public static DbType getDbType() {
return (DbType) contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}
Както виждате, можете също да използвате enum като ключ и Spring ще се погрижи да го разреши правилно въз основа на името. Свързаната конфигурация и ключове на DataSource може да изглежда така:
....
<bean id="dataSource" class="website.fedulov.routing.RoutingDataSource">
<property name="targetDataSources">
<map key-type="com.sabienzia.routing.DbType">
<entry key="MASTER" value-ref="dataSourceMaster"/>
<entry key="REPLICA1" value-ref="dataSourceReplica"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSourceMaster"/>
</bean>
<bean id="dataSourceMaster" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.master.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
<bean id="dataSourceReplica" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.replica.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
В този момент може да откриете, че правите нещо подобно:
@Service
public class BookService {
private final BookRepository bookRepository;
private final Mapper mapper;
@Inject
public BookService(BookRepository bookRepository, Mapper mapper) {
this.bookRepository = bookRepository;
this.mapper = mapper;
}
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
...//other methods
Сега можем да контролираме кой DataSource ще се използва и да препращаме заявки, както пожелаем. Изглежда добре!
...Или е така? На първо място, тези извиквания на статични методи към магически DbContextHolder наистина стърчат. Изглеждат сякаш не принадлежат на бизнес логиката. И те не го правят. Те не само не съобщават целта, но изглеждат крехки и податливи на грешки (какво ще кажете да забравите да почистите dbType). И какво ще стане, ако между setDbType и cleanDbType бъде хвърлено изключение? Не можем просто да го игнорираме. Трябва да сме абсолютно сигурни, че нулираме dbType, в противен случай потокът, върнат в ThreadPool, може да е в "счупено" състояние, опитвайки се да запише в реплика при следващото извикване. Значи имаме нужда от това:
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
try{
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
} catch (Exception e){
throw new RuntimeException(e);
} finally {
DbContextHolder.clearDbType(); // <----- make sure ThreadLocal setting is cleared
}
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
Ами >_< ! Това определено не изглежда като нещо, което бих искал да вложа във всеки метод само за четене. Можем ли да се справим по-добре? Разбира се! Този модел на „направете нещо в началото на метода, след това направете нещо в края“ трябва да бие звънец. Аспекти за спасяване!
За съжаление тази публикация вече стана твърде дълга, за да покрие темата за персонализираните аспекти. Можете да проследите подробностите за използването на аспекти, като използвате този връзка .