SQLAlchemy ви помага да работите с бази данни в Python. В тази публикация ви казваме всичко, което трябва да знаете, за да започнете с този модул.
В предишната статия говорихме как да използвате Python в ETL процеса. Ние се фокусирахме върху това да свършим работата чрез изпълнение на съхранени процедури и SQL заявки. В тази и следващата статия ще използваме различен подход. Вместо да пишем SQL код, ще използваме инструментариума SQLAlchemy. Можете също да използвате тази статия отделно, като бързо въведение в инсталирането и използването на SQLAlchemy.
Готов? Да започнем.
Какво е SQLAlchemy?
Python е добре известен със своя брой и разнообразие от модули. Тези модули намаляват значително времето ни за кодиране, защото изпълняват рутинни процедури, необходими за постигане на конкретна задача. Налични са редица модули, които работят с данни, включително SQLAlchemy.
За да опиша SQLAlchemy, ще използвам цитат от SQLAlchemy.org:
SQLAlchemy е инструментариумът на Python SQL и Object Relational Mapper, който дава на разработчиците на приложения пълната мощност и гъвкавост на SQL.
Осигурява пълен набор от добре позната устойчивост на корпоративно ниво шаблони, проектирани за ефективен и високопроизводителен достъп до база данни, адаптирани към прост и Pythonic домейн език.
Най-важната част тук е малкото за ORM (обектно-релационен картограф), който ни помага да третираме обектите на базата данни като обекти на Python, а не като списъци.
Преди да продължим по-нататък с SQLAlchemy, нека направим пауза и да поговорим за ORM.
Плюсите и минусите на използването на ORMs
В сравнение със суровия SQL, ORM имат своите плюсове и минуси – и повечето от тях се отнасят и за SQLAlchemy.
Добрите неща:
- Преносимост на кода. ORM се грижи за синтактичните разлики между базите данни.
- Само един език е необходим за работа с вашата база данни. Въпреки че, честно казано, това не трябва да е основната мотивация за използване на ORM.
- ORM опростяват кода ви , напр. те се грижат за връзките и ги третират като обекти, което е чудесно, ако сте свикнали с ООП.
- Можете да манипулирате данните си в програмата .
За съжаление всичко си има цена. Не толкова добрите неща за ORMs:
- В някои случаи ORM може да е бавен .
- Писане на сложни заявки може да стане още по-сложно или да доведе до бавни заявки. Но това не е така, когато използвате SQLAlchemy.
- Ако познавате добре своята СУБД, тогава е загуба на време да се научите как да пишете същите неща в ORM.
След като се справихме с тази тема, нека се върнем към SQLAlchemy.
Преди да започнем...
... нека си припомним целта на тази статия. Ако просто се интересувате от инсталиране на SQLAlchemy и имате нужда от бърз урок за това как да изпълнявате прости команди, тази статия ще направи това. Въпреки това командите, представени в тази статия, ще бъдат използвани в следващата статия за изпълнение на ETL процеса и замяна на SQL (запомнени процедури) и кода на Python, които представихме в предишни статии.
Добре, сега нека започнем от самото начало:с инсталирането на SQLAlchemy.
Инсталиране на SQLAlchemy
1. Проверете дали модулът вече е инсталиран
За да използвате Python модул, трябва да го инсталирате (тоест, ако не е бил инсталиран преди това). Един от начините да проверите кои модули са инсталирани е да използвате тази команда в Python Shell:
help('modules')
За да проверите дали е инсталиран конкретен модул, просто опитайте да го импортирате. Използвайте тези команди:
import sqlalchemy sqlalchemy.__version__
Ако SQLAlchemy вече е инсталиран, тогава първият ред ще се изпълни успешно. импорт <име на модула> е стандартна команда на Python, използвана за импортиране на модули. Ако модулът не е инсталиран, Python ще изведе грешка – всъщност списък с грешки, в червен текст – която не можете да пропуснете :)
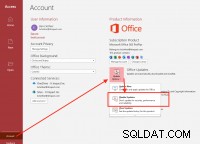
Втората команда връща текущата версия на SQLAlchemy. Върнатият резултат е на снимката по-долу:

Ще ни трябва и друг модул и това е PyMySQL . Това е лека клиентска библиотека на MySQL на чисто Python. Този модул поддържа всичко необходимо, за да работим с MySQL база данни, от изпълнение на прости заявки до по-сложни действия в базата данни. Можем да проверим дали съществува с помощта на help('modules') , както е описано по-горе, или използвайки следните две изрази:
import pymysql pymysql.__version__
Разбира се, това са същите команди, които използвахме, за да тестваме дали SQLAlchemy е инсталиран.
Ами ако SQLAlchemy или PyMySQL вече не са инсталирани?
Импортирането на предварително инсталирани модули не е трудно. Но какво ще стане, ако модулите, от които се нуждаете, все още не са инсталирани?
Някои модули имат инсталационен пакет, но най-вече ще използвате командата pip, за да ги инсталирате. PIP е инструмент на Python, използван за инсталиране и деинсталиране на модули. Най-лесният начин да инсталирате модул (в Windows OS) е:
- Използвайте Команден ред -> Изпълнение -> cmd .
- Позиционирайте в директорията на Python cd C:\...\Python\Python37\Scripts .
- Изпълнете командата pip
install <име на модула>(в нашия случай ще изпълнимpip install pyMySQLиpip install sqlAlchemy.
PIP може да се използва и за деинсталиране на съществуващия модул. За да направите това, трябва да използвате pip uninstall .
2. Свързване с базата данни
Въпреки че инсталирането на всичко необходимо за използване на SQLAlchemy е от съществено значение, не е много интересно. Нито всъщност е част от това, което ни интересува. Дори не сме се свързали с базите данни, които искаме да използваме. Ще решим това сега:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Използвайки горния скрипт, ще установим връзка с базата данни, разположена на нашия локален сървър, subscription_live база данни.
(Забележка: Заменете <потребителско име>:<парола> с вашето действително потребителско име и парола.)
Нека преминем през скрипта, команда по команда.
import sqlalchemy from sqlalchemy.engine import create_engine
Тези два реда импортират нашия модул и create_engine функция.
След това ще установим връзка с базата данни, намираща се на нашия сървър.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Функцията create_engine създава двигателя и използва .connect() , се свързва с базата данни. create_engine функцията използва следните параметри:
dialect+driver://username:password@host:port/database
В нашия случай диалектът е mysql , драйверът е pymysql (по-рано инсталиран), а останалите променливи са специфични за сървъра и базата данни, към които искаме да се свържем.
(Забележка: Ако се свързвате локално, използвайте localhost вместо вашия „локален“ IP адрес, 127.0.0.1 и съответния порт :3306 .)

Резултатът от командата print(engine_live.table_names()) е показано на снимката по-горе. Както се очакваше, получихме списъка с всички таблици от нашата оперативна/активна база данни.
3. Изпълнение на SQL команди с помощта на SQLAlchemy
В този раздел ще анализираме най-важните SQL команди, ще разгледаме структурата на таблицата и ще изпълним четирите DML команди:SELECT, INSERT, UPDATE и DELETE.
Ще обсъдим изразите, използвани в този скрипт отделно. Моля, имайте предвид, че вече сме преминали през частта за свързване на този скрипт и вече сме изброили имената на таблици. Има малки промени в този ред:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Току-що импортирахме всичко, което ще използваме от SQLAlchemy.
Таблици и структура
Ще стартираме скрипта, като напишем следната команда в Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Резултатът е изпълненият скрипт. Сега нека анализираме останалата част от скрипта.
SQLAlchemy импортира информация, свързана с таблици, структура и връзки. За да работите с тази информация, може да е полезно да проверите списъка с таблици (и техните колони) в базата данни:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Това просто връща списък с всички таблици от свързаната база данни.
Забележка: имена_на_таблици() метод връща списък с имена на таблици за дадения двигател. Можете да отпечатате целия списък или да го повторите с помощта на цикъл (както бихте могли да направите с всеки друг списък).
След това ще върнем списък с всички атрибути от избраната таблица. Съответната част от скрипта и резултатът са показани по-долу:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
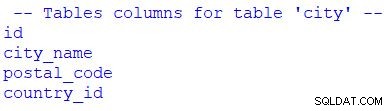
Можете да видите, че съм използвал за за да преминете през набора от резултати. Бихме могли да заменим table_city.c с table_city.columns .
Забележка: Процесът на зареждане на описанието на базата данни и създаване на метаданни в SQLAlchemy се нарича отражение.
Забележка: MetaData е обектът, който съхранява информация за обекти в базата данни, така че таблиците в базата данни също са свързани с този обект. Като цяло този обект съхранява информация за това как изглежда схемата на базата данни. Ще го използвате като единна точка за контакт, когато искате да направите промени или да получите факти за DB схемата.
Забележка: Атрибутите autoload =True и autoload_with =engine_live трябва да се използва, за да се гарантира, че атрибутите на таблицата ще бъдат качени (ако вече не са били).
ИЗБОР
Не мисля, че трябва да обяснявам колко важен е операторът SELECT :) Така че, нека просто кажем, че можете да използвате SQLAlchemy, за да пишете изрази SELECT. Ако сте свикнали със синтаксиса на MySQL, ще отнеме известно време, за да се адаптирате; все пак всичко е доста логично. За да го кажа възможно най-просто, бих казал, че операторът SELECT е нарязан и някои части са пропуснати, но всичко е в същия ред.
Нека сега опитаме няколко оператора SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Първият е прост израз SELECT връщане на всички стойности от дадената таблица. Синтаксисът на това изявление е много прост:поставих името на таблицата в select() . Моля, обърнете внимание, че имам:
- Подготви изявлението -
stmt =select([table_city]. - Отпечата изявлението с помощта на
print(stmt), което ни дава добра представа за изявлението, което току-що се изпълнява. Това може да се използва и за отстраняване на грешки. - Отпечата резултатът с
print(connection_live.execute(stmt).fetchall()). - Прегледа резултата и отпечата всеки отделен запис.
Забележка: Тъй като ние също заредихме ограничения на първичния и външния ключ в SQLAlchemy, операторът SELECT приема списък с обекти на таблица като аргументи и автоматично установява връзки, където е необходимо.
Резултатът е показан на снимката по-долу:

Python ще извлече всички атрибути от таблицата и ще ги съхрани в обекта. Както е показано, можем да използваме този обект за извършване на допълнителни операции. Крайният резултат от нашето изявление е списък на всички градове от град таблица.
Сега сме готови за по-сложна заявка. Току-що добавих клауза ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Забележка: asc() методът извършва възходящо сортиране спрямо родителския обект, като използва дефинирани колони като параметри.
Върнатият списък е същият, но сега е сортиран по стойността на id във възходящ ред. Важно е да отбележим, че просто добавихме .order_by( към предишната заявка SELECT. .order_by(...) метод ни позволява да променим реда на върнатия набор от резултати, по същия начин, както бихме използвали в SQL заявка. Следователно параметрите трябва да следват логиката на SQL, като използват имената на колоните или реда на колоните и ASC или DESC.
След това ще добавим WHERE към нашия оператор SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Забележка: .where() методът се използва за тестване на условие, което сме използвали като аргумент. Можем също да използваме .filter() метод, който е по-добър при филтриране на по-сложни условия.
Още веднъж .where част е просто свързана с нашия оператор SELECT. Забележете, че сме поставили условието в скобите. Каквото и условие да е в скобите, се тества по същия начин, както би било тествано в частта WHERE на израза SELECT. Условието за равенство се тества с ==вместо =.
Последното нещо, което ще опитаме с SELECT, е да обединим две таблици. Нека първо да разгледаме кода и неговия резултат.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

В горното изявление има две важни части:
select([table_city.columns.city_name, table_country.columns.country_name])определя кои колони ще бъдат върнати в нашия резултат..select_from(table_city.join(table_country))дефинира условието/таблицата за присъединяване. Забележете, че не е трябвало да записваме пълното условие за присъединяване, включително ключовете. Това е така, защото SQLAlchemy „знае“ как тези две таблици се съединяват, тъй като правилата за първични и външни ключове се импортират на заден план.
ВМЪКВАНЕ / АКТУАЛИЗИРАНЕ / ИЗТРИВАНЕ
Това са трите оставащи DML команди, които ще разгледаме в тази статия. Въпреки че структурата им може да стане много сложна, тези команди обикновено са много по-прости. Използваният код е представен по-долу.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
И за трите израза се използва един и същ модел:подготовка на оператора, отпечатване и изпълнение и отпечатване на резултата след всеки израз, за да можем да видим какво всъщност се е случило в базата данни. Забележете още веднъж, че части от изявлението се третират като обекти (.values(), .where()).

Ще използваме тези знания в предстоящата статия, за да изградим цял ETL скрипт с помощта на SQLAlchemy.
Следва:SQLAlchemy в ETL процеса
Днес анализирахме как да настроим SQLAlchemy и как да изпълняваме прости DML команди. В следващата статия ще използваме тези знания, за да напишем пълния ETL процес с помощта на SQLAlchemy.
Можете да изтеглите пълния скрипт, използван в тази статия тук.