ProxySQL е специален балансьор на натоварване за MySQL, който се предлага с различни функции, включително, но не само, пренасочване на заявки, кеширане на заявки или оформяне на трафик. Може да се използва за лесно настройване на разделяне на четене-запис и пренасочване на заявки към отделни бекенд възли. В резултат на това той предоставя много убедителни причини за използване. От друга страна, HAProxy е страхотен балансьор на натоварването, но не е предназначен за бази данни и въпреки че може да се използва, не може да се сравнява реално с ProxySQL. Това може да е причината за среди, които все още разчитат на HAProxy да се опитат да мигрират към ProxySQL.
В тази кратка публикация в блога ще споделим няколко предложения относно процеса на миграция.
Планиране на надстройката
Това е до голяма степен очевидно и трябва да бъде без съмнение, но все пак бихме искали да го имаме в писмен вид. Планирайте надграждането си. Уверете се, че сте запознати с процеса, че сте тествали всичко обстойно. Настройте тестова среда, в която можете да проверите различни подходи към надстройката и да решите кой би работил най-добре за вас.
Тествайте разделяне на четене/запис в ProxySQL, ако обмисляте да го използвате
В зависимост от вашите изисквания, може да помислите за използването на разделяне на четене/запис в ProxySQL. Това вероятно е една от най-убедителните причини за надграждане. Вместо да го прилагате от страната на приложението (или да не го прилагате изобщо, ако не можете да го постигнете в приложението), можете да разчитате на ProxySQL да извърши разделянето на четене/запис вместо вас. Настройката е много лесна, особено ако разгръщате ProxySQL с помощта на ClusterControl - става почти автоматично.
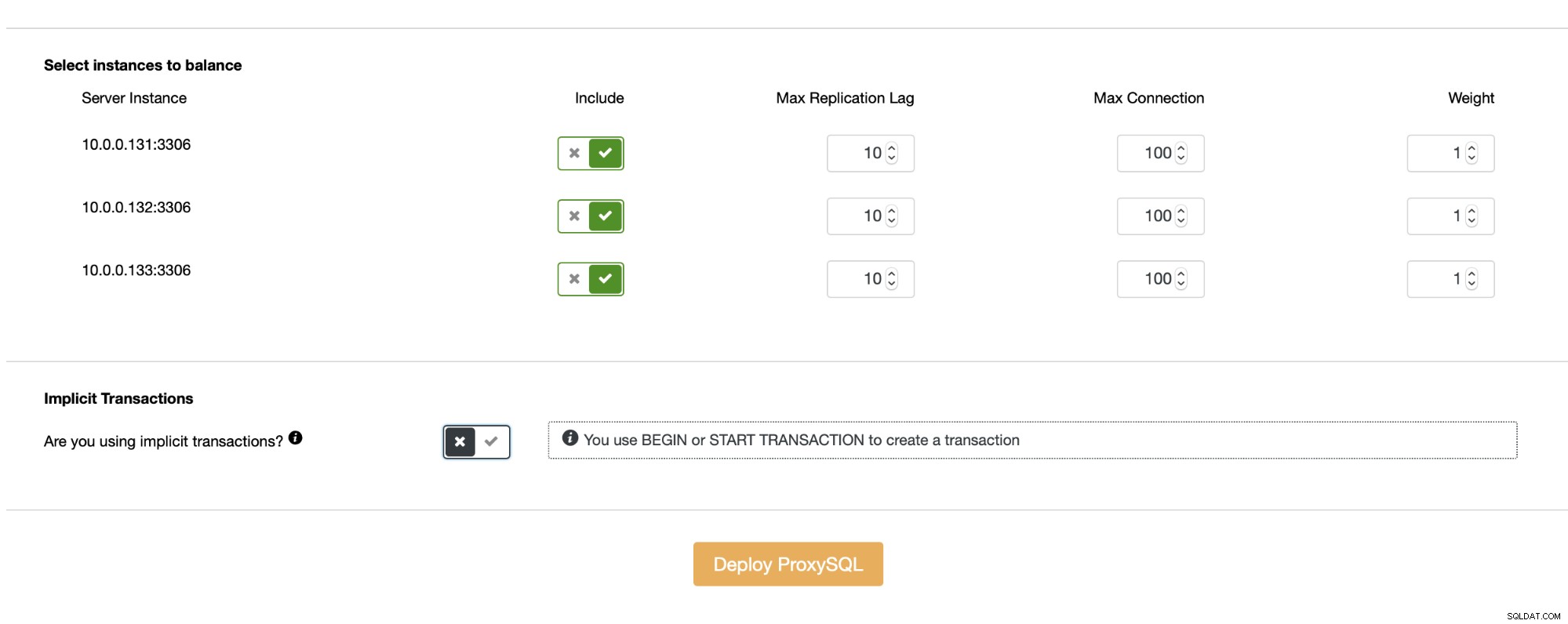
Докато не използвате неявни транзакции, ClusterControl ще настрои разделяне за четене/запис вместо вас с помощта на набор от правила за заявка:
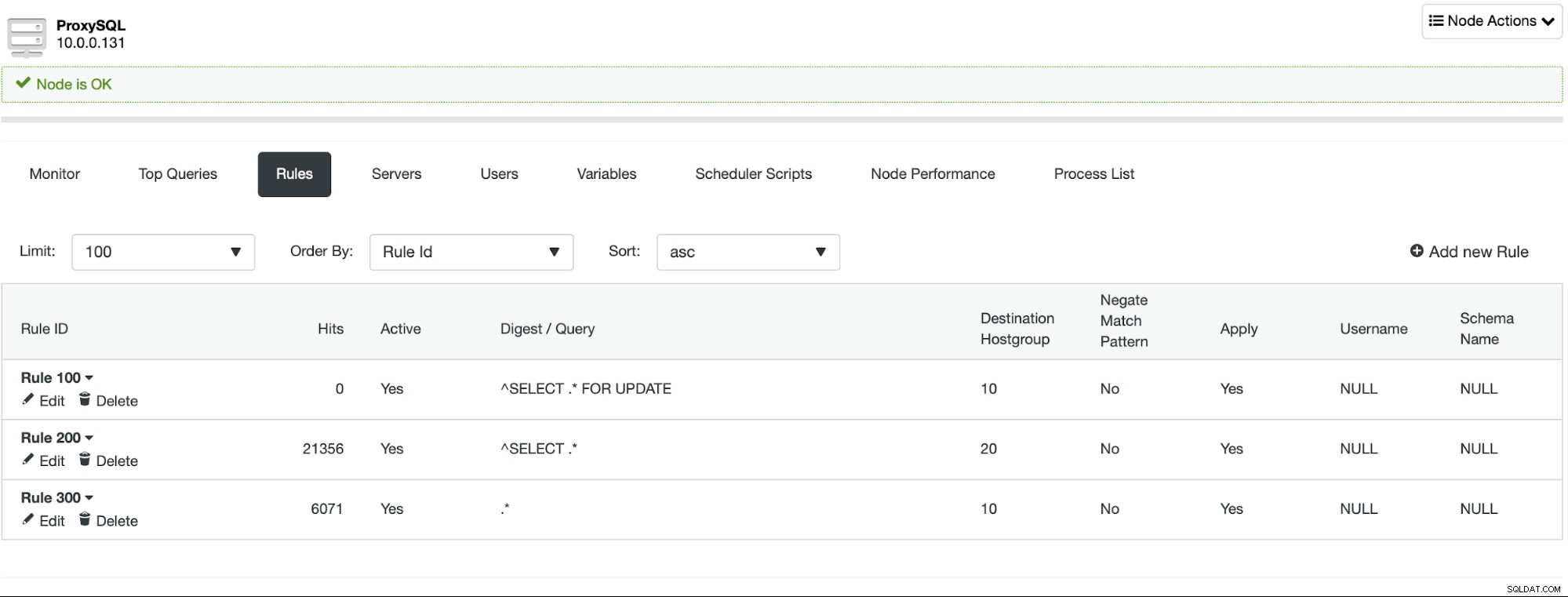
Въпреки че е много лесно да приложите разделяне на четене/запис, трябва бъдете внимателни, когато планирате да го направите. Приложенията може да разчитат на някои функции, които наистина не работят от кутията в ProxySQL. В повечето случаи допълнителната конфигурация ще ви позволи да се възползвате от тази функция, но е много важно по време на тестовата фаза да определите дали приложението ви просто ще работи или трябва да добавите някаква персонализирана конфигурация. Особено трудни части са проблемите при четене след запис – в този случай може да се наложи да преконфигурирате ProxySQL, за да деактивирате мултиплексирането на връзки за някои от заявките.
Забравете за конфигурационния файл в ProxySQL
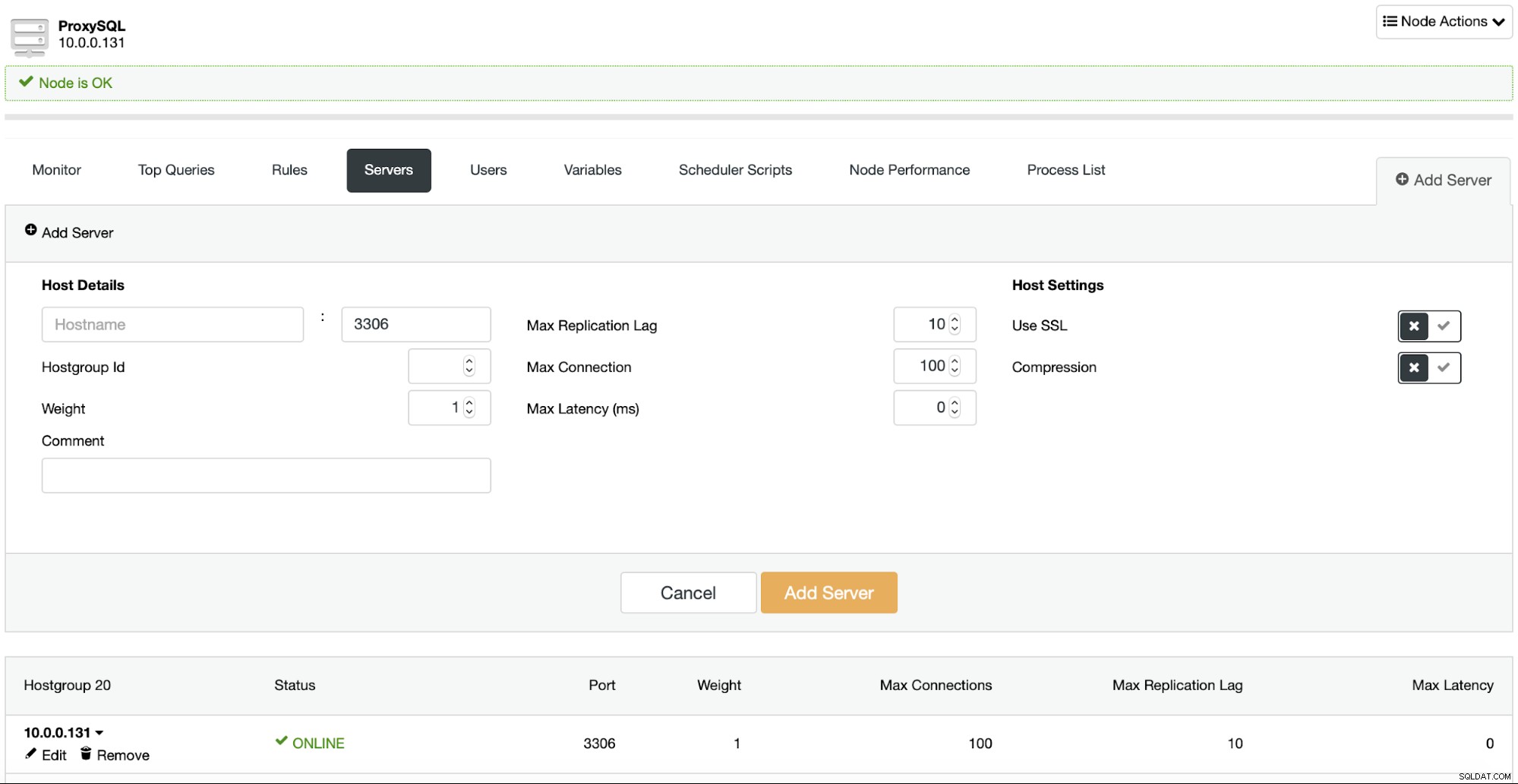
Това е едно от нещата, които идват като изненада за новите потребители на ProxySQL. Той всъщност не използва конфигурационни файлове. Има един, да, но той до голяма степен действа като начин за стартиране на ProxySQL по време на първото стартиране. ProxySQL използва база данни на SQLite, която съдържа нейната конфигурация и правилният начин за извършване на промени в конфигурацията е чрез MySQL клиент, свързан към административния порт на ProxySQL. От там можете да направите промените в конфигурацията по време на изпълнение, почти без да е необходимо да рестартирате ProxySQL.
Разбира се, потребителският интерфейс на ClusterControl също ви позволява да преконфигурирате ProxySQL:
Модели за внедряване на ProxySQL
Има два основни начина, по които искате да внедрите ProxySQL. Можете да използвате или специални сървъри, за да разположите ProxySQL на:
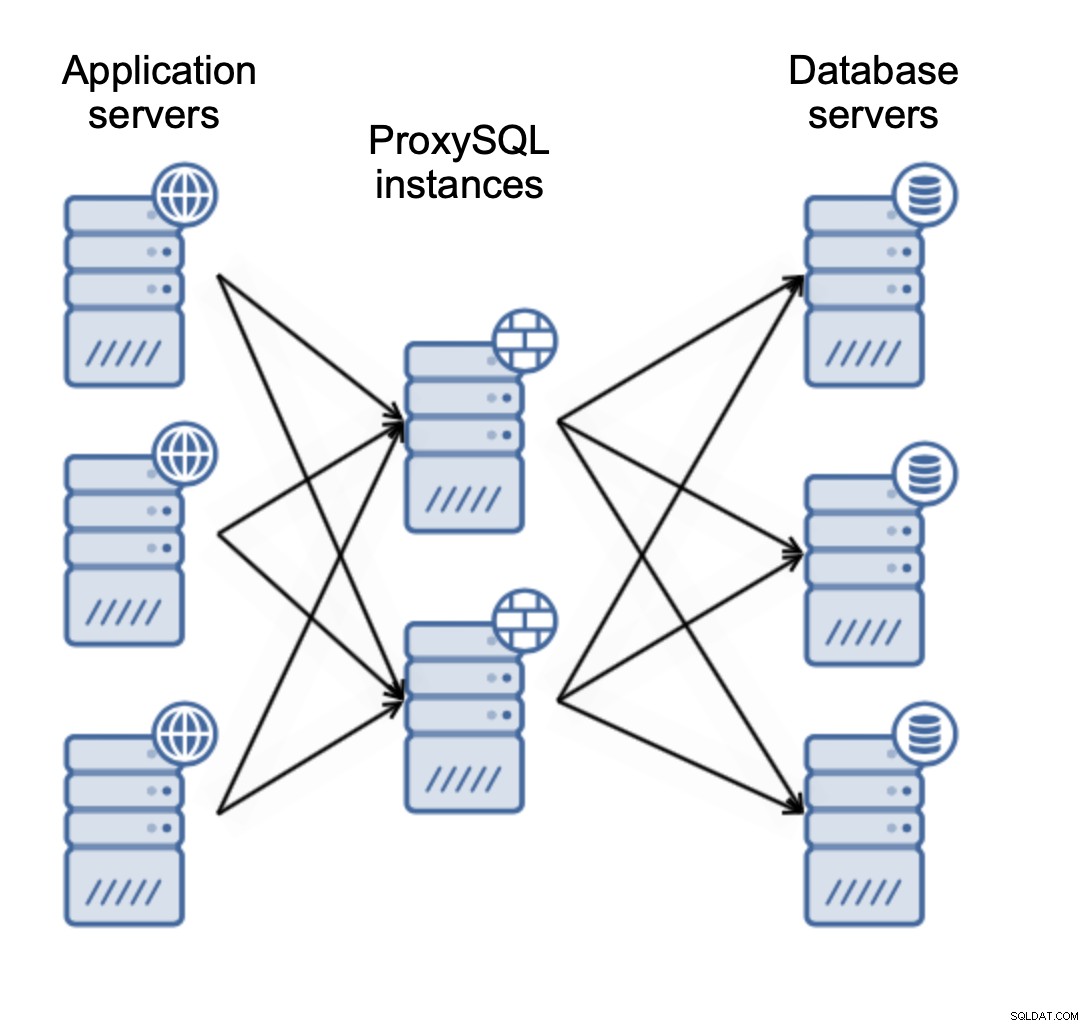
Или можете да разпределите ProxySQL със сървъри на приложения:
Това позволява на приложението ви да се свърже с локалния ProxySQL екземпляр с помощта на Unix сокет, който е по-добра по отношение на производителността, отколкото използването на отдалечена TCP връзка. Това също така опростява настройката - няма нужда да се внедрява Keepalived или друг доставчик на виртуален IP за балансиране на натоварването между екземпляри на ProxySQL. Приложението се свързва само с локалния ProxySQL и това е почти всичко.
Използвайте ProxySQL клъстери за по-големи внедрявания
Да се уверите, че вашите ProxySQL екземпляри съдържат една и съща конфигурация през цялото време, може да бъде предизвикателство, особено ако броят им е голям. Има много начини за справяне с подобни предизвикателства - Ansible/Chef/Puppet, shell скриптове и така нататък. Предлагаме да разчитате на вграденото решение - ProxySQL Cluster. Само с няколко промени в конфигурацията можете да конфигурирате възлите на ProxySQL, за да образуват клъстер, където промяната на конфигурацията на един от възлите ще бъде разпространена във всички членове на клъстера.
Търговия със SO_REUSEPORT за изящно превключване на балансира на натоварването
Една от по-предизвикателните части може да бъде да гарантирате, че ще превключите трафика от HAProxy към ProxySQL по начин, който ще сведе до минимум въздействието върху приложението. Обикновено ще трябва да промените поне една настройка - име на хост или порт, към който приложението трябва да се свърже. В зависимост от вашата среда това може да не е идеално, особено ако конфигурацията за свързване на базата данни е вградена в приложението. Това в голяма степен ще изисква промяна в кодовата база и въвеждане на нов код в производството. Не е най-голямата от сделките, но можете да направите по-добре от това.
Интересната част е, че както ProxySQL, така и последните версии на HAProxy (започвайки от 1.8) могат да използват SO_REUSEPORT. Тази опция за сокет е налична в Linux, започвайки от ядрото 3.9 и позволява на множество процеси да споделят един и същ порт. ProxySQL може да го използва за грациозни надстройки между версиите на ProxySQL, HAProxy го използва за презареждане на конфигурацията без никакво въздействие върху приложението. Интересното е, че е възможно да се конфигурира ProxySQL да споделя порта с HAProxy за безпроблемна миграция между тези два балансира на натоварване.
Има няколко неща, които трябва да имате предвид, когато се опитвате да направите това - първо, ProxySQL не използва тази опция по подразбиране, трябва да добавите -r флаг към ProxySQL при стартиране. Можете да направите това, като редактирате ProxySQL systemd файл:
example@sqldat.com:~# systemctl edit proxysql --fullи промяна на директивата ExecStart на:
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rДруго ограничение, което трябва да знаете в Linux, е, че само процеси, стартирани от същия потребителски идентификатор, могат да споделят порта. Това ще означава, че ще трябва да преконфигурирате ProxySQL, за да се изпълнява като „haproxy“ потребител.
Както обикновено, може да искате да стартирате тестове, преди да се опитате да извършите тази операция в производствена среда. Определено е възможно да се постигне този подвиг, но трябва да внимавате и да проверите отново дали това няма да повлияе на производството ви поради някаква нестандартна конфигурация, свързана с вашата среда.
Надяваме се, че този кратък блог ще ви даде известна представа за процеса на миграция от HAProxy към ProxySQL. За задните части на базата данни тази промяна ще бъде много полезна, дори ако подготвителната част може да отнеме време. Ако преминете през правилно тестване, окончателната миграция трябва да бъде доста проста и безопасна.