Въведение
Пренавиване са специфични за оператори от вътрешната страна на вложени цикли, присъединяване или прилагане. Идеята е да се използват повторно предварително изчислени резултати от част от план за изпълнение, където е безопасно да се направи това.
Каноничният пример за оператор на план, който може да превърта назад, е мързеливият Табличен пул . Това е raison d’être е да кеширате редове с резултати от поддървото на плана, след което да възпроизведете тези редове при следващи итерации, ако някои корелирани параметри на цикъла са непроменени. Повторното възпроизвеждане на редове може да бъде по-евтино от повторното изпълнение на поддървото, което ги е генерирало. За повече информация относно тези производителни шпули вижте предишната ми статия.
В документацията се казва, че само следните оператори могат да превъртат назад:
- Спула за маса
- Шпула за броене на редове
- Неклъстерирана индексна спула
- Функция със стойност на таблица
- Сортиране
- Отдалечена заявка
- Потвърждение и Филтър оператори с израз за стартиране
Първите три елемента най-често са макари за производителност, въпреки че могат да бъдат въведени по други причини (когато може да са нетърпеливи, както и мързеливи).
Функции със стойност на таблица използвайте променлива на таблица, която може да се използва за кеширане и възпроизвеждане на резултати при подходящи обстоятелства. Ако се интересувате от превъртания на функции с таблица, моля, вижте моите въпроси и отговори на Stack Exchange на администратори на база данни.
Като изключим тези, тази статия е изключително за Сортове и кога могат да превъртат назад.
Сортиране назад
Сортирането използва съхранение (памет и може би диск, ако се разлее), така че имат способно средство на съхраняване на редове между итерациите на цикъла. По-конкретно, сортираният изход може по принцип да бъде възпроизведен (пренавиван).
И все пак, краткият отговор на заглавния въпрос „Превърта ли се сортирането назад?“ е:
Да, но няма да го виждате много често.
Типове сортиране
Сортовете се предлагат в много различни типове вътрешно, но за нашите текущи цели има само два:
- Сортиране в памет (
CQScanInMemSortNew).- Винаги в паметта; не може да се разлее на диск.
- Използва стандартна библиотека за бързо сортиране.
- Максимум 500 реда идве страници от 8KB общо.
- Всички входове трябва да са константи по време на изпълнение. Обикновено това означава, че цялото поддърво за сортиране трябва да се състои от само Постоянно сканиране и/или Изчисли скаларен оператори.
- Само изрично различими в плановете за изпълнение, когато подробен план за показване е активиран (флаг за проследяване 8666). Това добавя допълнителни свойства към Сортиране оператор, един от които е „InMemory=[0|1]“.
- Всички други видове.
(И двата типа Сортиране оператор включва техния Сортиране най-напред и Различно сортиране варианти).
Поведение при пренавиване
-
Сортиране в паметта винаги може да превърта назад когато е безопасно. Ако няма корелирани параметри на цикъла или стойностите на параметрите са непроменени спрямо непосредствено предходната итерация, този тип сортиране може да възпроизведе съхранените си данни, вместо да изпълнява повторно оператори под него в плана за изпълнение.
-
Сортиране без памет може да превърта назад когато е безопасно, но само ако Сортиране операторът съдържа най-много един ред . Моля, обърнете внимание на Сортиране входът може да осигури един ред при някои итерации, но не и при други. Следователно поведението по време на изпълнение може да бъде сложна смес от пренавиване и повторно свързване. Напълно зависи от това колко реда са предоставени на Сортиране на всяка итерация по време на изпълнение. По принцип не можете да предвидите какво е Сортиране ще прави при всяка итерация, като проверява плана за изпълнение.
Думата „безопасно“ в описанията по-горе означава:Или не е настъпила промяна в параметъра, или няма оператори под Сортиране имат зависимост от променената стойност.
Важна забележка относно плановете за изпълнение
Плановете за изпълнение не винаги отчитат правилно превъртанията (и превързвания) за Сортиране оператори. Операторът ще докладва превъртане назад, ако някои корелирани параметри са непроменени, и повторно свързване в противен случай.
За сортиране извън паметта (далеч и най-често срещаното), докладваното превъртане действително ще възпроизведе отново съхранените резултати от сортиране само ако има най-много един ред в изходния буфер за сортиране. В противен случай сортирането ще отчита превъртане назад, но поддървото пак ще бъде напълно изпълнено отново (превързване).
За да проверите колко отчетени превъртания са били действителни превъртания, проверете Брой изпълнения свойство на оператори под Сортиране .
История и моето обяснение
Сортиране Поведението на оператора при пренавиване може да изглежда странно, но е било по този начин от (поне) SQL Server 2000 до SQL Server 2019 включително (както и Azure SQL база данни). Не успях да намеря официално обяснение или документация за това.
Моето лично мнение е, че Сортиране пренавиването е доста скъпо поради основната машина за сортиране, включително съоръжения за разливане, и използването на системни транзакции в tempdb .
В повечето случаи оптимизаторът ще направи по-добре да въведе изрична скоростна спула когато открие възможността за дублиране на корелирани параметри на цикъла. Спулите са най-евтиният начин за кеширане на частични резултати.
Това е възможно това повторно възпроизвеждане на Сортиране резултатът би бил само по-рентабилен от Spool когато Сортиране съдържа най-много един ред. В крайна сметка сортирането на един ред (или без редове!) всъщност не включва никакво сортиране, така че голяма част от режийните разходи могат да бъдат избегнати.
Чиста спекулация, но някой трябваше да попита, така че това е.
Демонстрация 1:Неточно превъртане назад
Този първи пример включва две таблични променливи. Първата съдържа три стойности, дублирани три пъти в колона c1 . Втората таблица съдържа два реда за всяко съвпадение на c2 = c1 . Двата съвпадащи реда се отличават със стойност в колона c3 .
Задачата е да върнете реда от втората таблица с най-висок c3 стойност за всяко съвпадение на c1 = c2 . Кодът вероятно е по-ясен от моето обяснение:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
NO_PERFORMANCE_SPOOL намек е налице, за да попречи на оптимизатора да въведе пул за производителност. Това може да се случи с променливи в таблицата, когато напр. флагът за проследяване 2453 е активиран или е налична компилация с отложена променлива на таблица, така че оптимизаторът може да види истинската мощност на променливата на таблицата (но не и разпределението на стойностите).
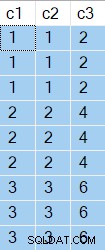
Резултатите от заявката показват c2 и c3 върнатите стойности са еднакви за всеки отделен c1 стойност:
Действителният план за изпълнение на заявката е:
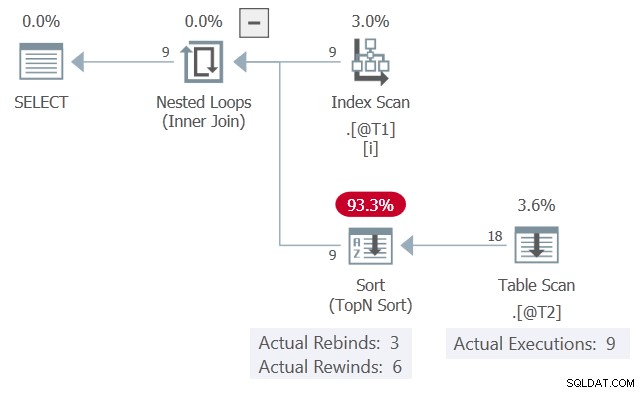
c1 стойностите, представени в ред, съответстват на предишната итерация 6 пъти и се променят 3 пъти. Сортиране отчита това като 6 превъртания назад и 3 превъртания.
Ако това беше вярно, Сканиране на таблица ще се изпълни само 3 пъти. Сортиране ще превърти (превърта) резултатите си в останалите 6 пъти.
Както е, можем да видим Сканиране на таблица беше изпълнено 9 пъти, по веднъж за всеки ред от таблица @T1 . Тук не е имало превъртания назад .
Демонстрация 2:Сортиране назад
Предишният пример не позволяваше Сортиране за превъртане назад, защото (а) не е Сортиране в памет; и (b) при всяка итерация на цикъла Sort съдържаше два реда. Plan Explorer показва общо 18 реда от Сканиране на таблица , два реда на всяка от 9 итерации.
Нека сега да настроим примера, така че да има само един ред в таблица @T2 за всеки съвпадащ ред от @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Резултатите са същите като показаните по-рано, защото запазихме съответстващия ред, който беше сортиран най-високо в колона c3 . Планът за изпълнение също е външно подобен, но с важна разлика:
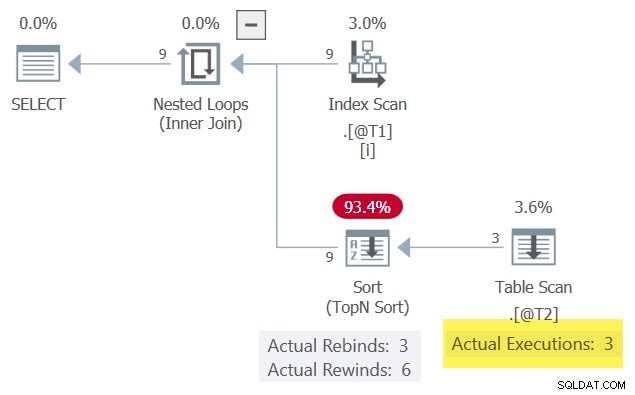
С един ред в Сортиране във всеки един момент може да се превърти назад, когато корелираният параметър c1 не се променя. Сканиране на таблица в резултат се изпълнява само 3 пъти.
Обърнете внимание на Сортиране произвежда повече редове (9), отколкото получава (3). Това е добра индикация, че Сортиране е успял да кешира набор от резултати един или повече пъти – успешно превъртане назад.
Демонстрация 3:Пренавиване на нищо
Споменах преди това Сортиране без памет може да превърта назад, когато съдържа най-много един ред.
За да видите това в действие с нула редове , ние променяме на OUTER APPLY и не поставяйте редове в таблица @T2 . Поради причини, които ще станат ясни скоро, ние също ще спрем да проектираме колона c2 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Резултатите вече имат NULL в колона c3 както се очаква:
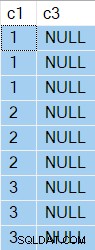
Планът за изпълнение е:
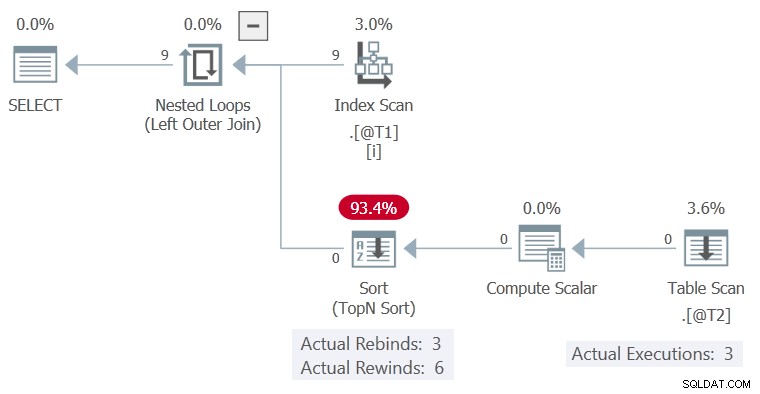
Сортиране успя да пренавие без редове в буфера си, така че Сканиране на таблица беше изпълнено само 3 пъти, всяка колона за време c1 променена стойност.
Демонстрация 4:Максимално превъртане назад!
Подобно на другите оператори, които поддържат пренавиване, Сортиране ще само свърже отново неговото поддърво, ако корелиран параметър е променен и поддървото зависи по някакъв начин от тази стойност.
Възстановяване на колоната c2 проекцията към демонстрация 3 ще покаже това в действие:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Резултатите вече показват две NULL колони разбира се:
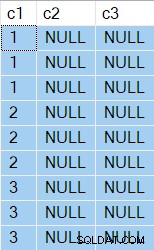
Планът за изпълнение е доста различен:
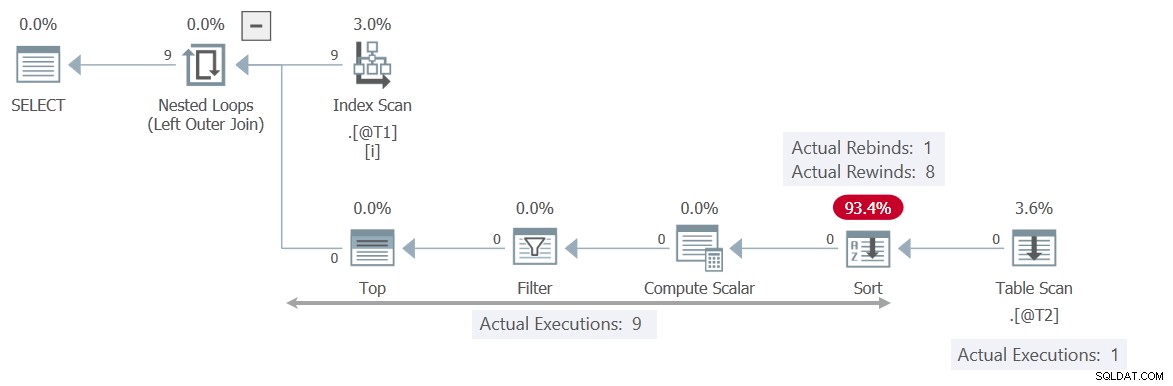
Този път Филтър съдържа проверката T2.c2 = T1.c1 , правейки Сканиране на таблица независима на текущата стойност на корелирания параметър c1 . Сортиране може безопасно да превърта 8 пъти назад, което означава, че сканирането се изпълнява само веднъж .
Демонстрация 5:Сортиране в памет
Следващият пример показва Сортиране в паметта оператор:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Резултатите, които получавате, ще варират от изпълнение до изпълнение, но ето един пример:
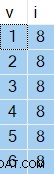
Интересното е стойностите в колона i винаги ще бъде един и същ — въпреки ORDER BY NEWID() клауза.
Вероятно вече сте се досетили, че причината за това е Сортиране кеширане на резултати (пренавиване). Планът за изпълнение показва Постоянно сканиране изпълнява само веднъж, произвеждайки общо 11 реда:
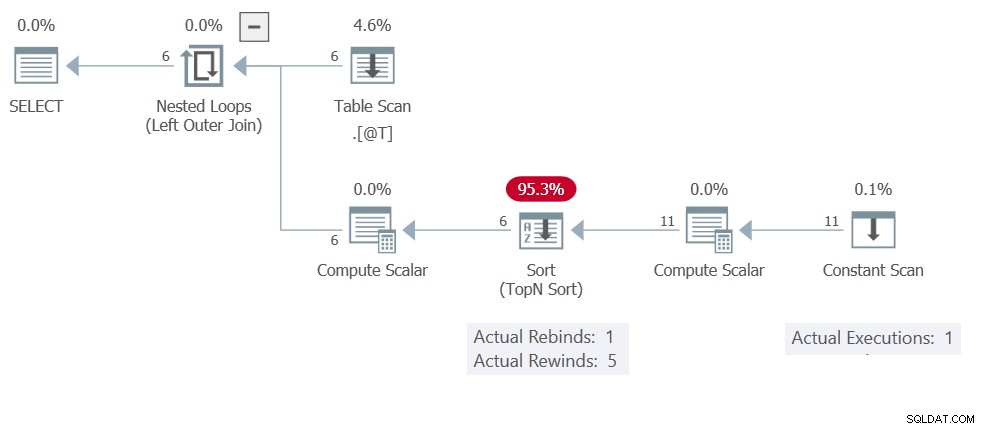
Това Сортиране има само Compute Scalar и Постоянно сканиране оператори на неговия вход, така че е Сортиране в памет . Не забравяйте, че те не са ограничени най-много до един ред – те могат да побират 500 реда и 16 КБ.
Както бе споменато по-рано, не е възможно изрично да се види дали Сортиране е В паметта или не чрез проверка на редовен план за изпълнение. Нуждаем се от подробен изход на showplan , активиран с недокументиран флаг за проследяване 8666. При активиране се появяват допълнителни свойства на оператора:
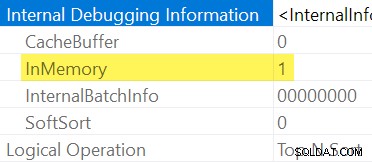
Когато не е практично да използвате недокументирани флагове за проследяване, можете да заключите, че Сортиране е „InMemory“ чрез своята входна фракция на паметта е нула и Използване на паметта елементи, които не са налични в плана за показване след изпълнение (на версии на SQL Server, поддържащи тази информация).
Обратно към плана за изпълнение:Няма свързани параметри, така че Сортиране е свободен за превъртане 5 пъти назад, което означава Постоянно сканиране се изпълнява само веднъж. Чувствайте се свободни да промените TOP (1) до TOP (3) или каквото искате. Пренавиването означава, че резултатите ще бъдат еднакви (кеширани/пренавивани) за всеки входен ред.
Може да се притеснявате от ORDER BY NEWID() клауза, която не предотвратява пренавиването. Това наистина е спорен момент, но изобщо не се ограничава до видове. За по-пълна дискусия (предупреждение:възможна заешка дупка), моля, вижте тези въпроси и отговори. Кратката версия е, че това е умишлено решение за дизайн на продукта, оптимизиращо за производителност, но има планове да се направи поведението по-интуитивно с течение на времето.
Демонстрация 6:Няма сортиране в памет
Това е същото като демонстрация 5, с изключение на това, че репликираният низ е с един знак по-дълъг:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Отново резултатите ще варират в зависимост от изпълнението, но ето един пример. Обърнете внимание на i стойностите вече не са еднакви:

Допълнителният символ е достатъчно, за да изтласка прогнозния размер на сортираните данни над 16KB. Това означава Сортиране в паметта не може да се използва и превъртанията изчезват.
Планът за изпълнение е:
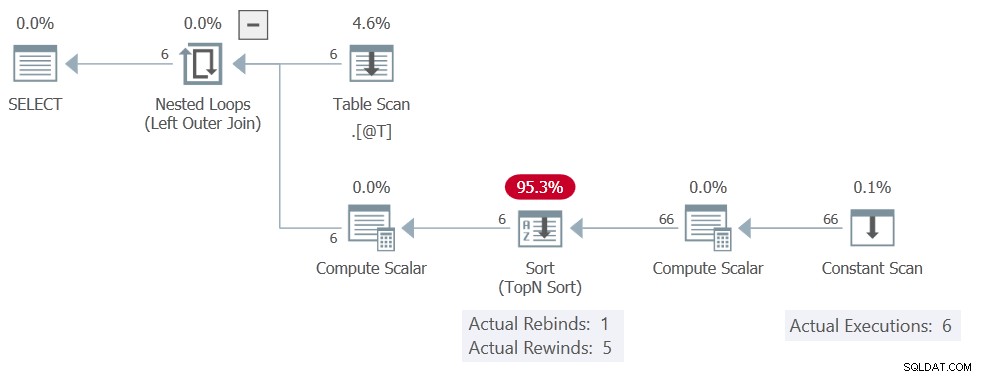
Сортиране все още доклади 5 превъртания назад, но Постоянно сканиране се изпълнява 6 пъти, което означава, че не е имало никакви превъртания назад. Той произвежда всичките 11 реда при всяко от 6 изпълнения, което дава общо 66 реда.
Обобщение и заключителни мисли
Няма да видите Сортиране операторнаистина пренавиване много често, въпреки че ще го видите да казва, че е така доста.
Не забравяйте, че обикновено Сортиране може да превърта само ако е безопасно и има максимум един ред в сортирането в даден момент. Да бъдеш „безопасен“ означава или липса на промяна в параметрите на корелация на цикъла, или нищо под Сортиране се влияе от промените на параметрите.
Сортиране в паметта може да работи с до 500 реда и 16KB данни, получени от Constant Scan и Изчисли скаларен само оператори. Освен това ще се пренавива само когато е безопасно (без грешки в продукта!), но не е ограничено до максимум един ред.
Това може да изглеждат като езотерични подробности и предполагам, че са. Така казано, те ми помогнаха да разбера план за изпълнение и да намеря добри подобрения в производителността повече от веднъж. Може би някой ден информацията ще ви бъде полезна.
Внимавайте за Сортове които произвеждат повече редове, отколкото имат на своя вход!
Ако искате да видите по-реалистичен пример за Сортиране пренавивания въз основа на демонстрация, предоставена от Ицик Бен-Ган в част първа от Най-близкия му мач серия, моля, вижте най-близкото съвпадение със сортиране назад.