В наши дни базите данни, обхващащи множество облаци, са доста често срещани. Те обещават висока наличност и възможност за лесно прилагане на процедури за възстановяване след бедствие. Те също са метод за избягване на заключване на доставчик:ако проектирате вашата среда на база данни, така че тя да може да работи в множество доставчици на облак, най-вероятно не сте обвързани с функции и реализации, специфични за един конкретен доставчик. Това ви улеснява да добавите друг доставчик на инфраструктура към вашата среда, независимо дали става въпрос за друг облак или локална настройка. Такава гъвкавост е много важна, като се има предвид, че има ожесточена конкуренция между доставчиците на облак и мигрирането от един към друг може да е доста осъществимо, ако бъде подкрепено от намаляване на разходите.
Разпространението на вашата инфраструктура в множество центрове за данни (от един и същ доставчик или не, всъщност няма значение) води до сериозни проблеми за решаване. Как може да се проектира цялата инфраструктура по начин, по който данните да са безопасни? Как да се справите с предизвикателствата, с които трябва да се сблъскате, докато работите в мулти-облачна среда? В този блог ще разгледаме един, но може би най-сериозният - потенциал на разделен мозък. Какво означава? Нека се поразровим малко в това какво е разделен мозък.
Какво е „Разделен мозък“?
Разделеният мозък е състояние, при което среда, състояща се от множество възли, претърпява мрежово разделяне и е разделена на множество сегменти, които нямат контакт един с друг. Най-простият случай ще изглежда така:
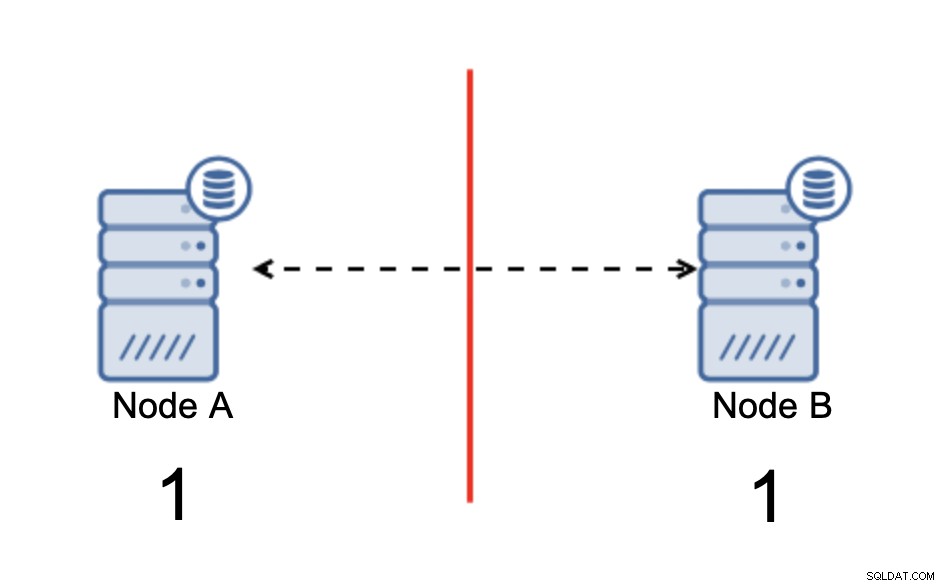
Имаме два възела, A и B, свързани през мрежа чрез bi -насочена асинхронна репликация. След това мрежовата връзка се прекъсва между тези възли. В резултат на това и двата възела не могат да се свържат един с друг и всички промени, извършени на възел А, не могат да бъдат предадени на възел B и обратно. И двата възела, A и B, са готови и приемат връзки, те просто не могат да обменят данни. Това може да доведе до сериозни проблеми, тъй като приложението може да прави промени и в двата възела, очаквайки да види пълното състояние на базата данни, докато всъщност работи само с частично известно състояние на данните. В резултат на това приложението може да предприеме неправилни действия, да представи на потребителя неправилни резултати и т.н. Смятаме, че е ясно, че разделеният мозък е потенциално много опасно състояние и един от приоритетите би бил да се справим с него до известна степен. Какво може да се направи по въпроса?
Как да избегнем разделяне на мозъка
Накратко, зависи. Основният проблем, с който трябва да се справите, е фактът, че възлите работят и работят, но нямат връзка помежду си, следователно не са наясно със състоянието на другия възел. Като цяло асинхронната репликация на MySQL няма някакъв механизъм, който да реши вътрешно проблема с разделения мозък. Можете да опитате да приложите някои решения, които ви помагат да избегнете разделянето на мозъка, но те идват с ограничения или все още не решават напълно проблема.
Когато се отклоним от асинхронната репликация, нещата изглеждат по различен начин. MySQL Group Replication и MySQL Galera Cluster са технологии, които се възползват от осведомеността за изграждане на клъстер. И двете решения поддържат комуникацията между възлите и гарантират, че клъстерът е наясно със състоянието на възлите. Те прилагат механизъм за кворум, който управлява дали клъстерите могат да работят или не.
Нека обсъдим тези две решения (асинхронна репликация и клъстери, базирани на кворум) по-подробно.
Клъстериране, базирано на кворум
Няма да обсъждаме разликите в имплементацията между MySQL Galera Cluster и MySQL Group Replication, ще се съсредоточим върху основната идея зад базирания на кворум подход и как той е предназначен да реши проблема с разделен мозък във вашия клъстер.
Изводът е, че:клъстерът, за да работи, изисква по-голямата част от неговите възли да са налични. С това изискване можем да сме сигурни, че малцинството никога не може да засегне останалата част от клъстера, защото малцинството не трябва да може да извършва никакви действия. Това също означава, че за да може да се справи с повреда на един възел, клъстерът трябва да има поне три възела. Ако имате само два възела:
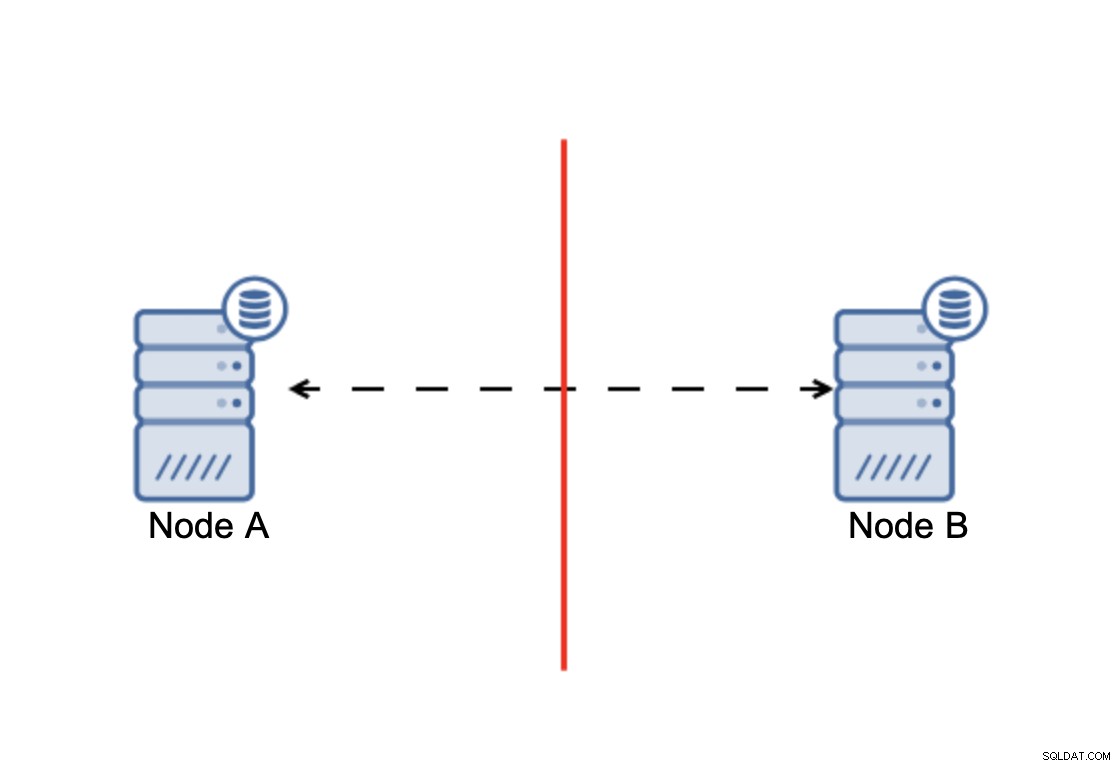
Когато има разделяне на мрежата, в крайна сметка получавате две части от клъстер, всеки от които се състои точно от 50% от общите възли в клъстера. Нито една от тези части няма мнозинство. Ако имате три възела обаче, нещата са различни:
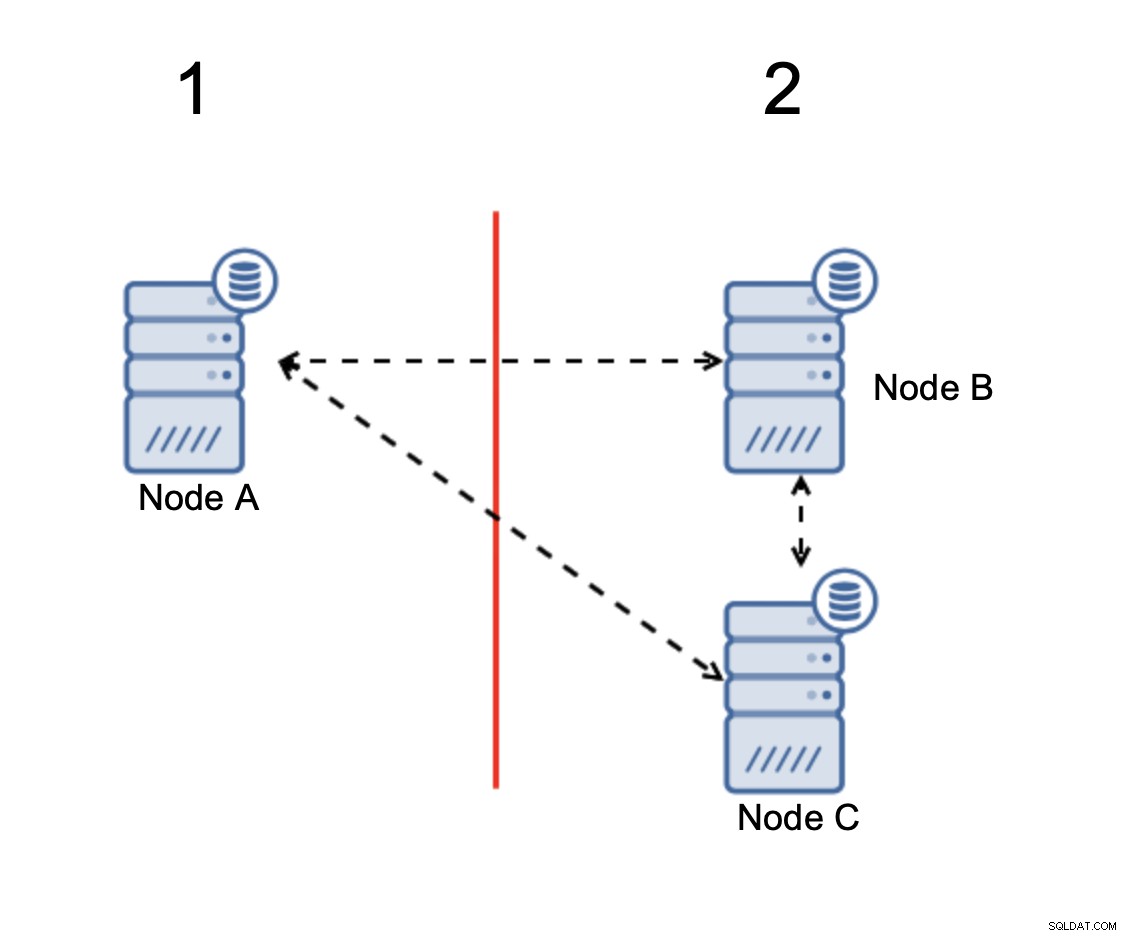
Възлите B и C имат мнозинството:тази част се състои от два възела навън от три, така че може да продължи да работи. От друга страна, възел A представлява само 33% от възлите в клъстера, така че няма мнозинство и ще престане да обработва трафика, за да избегне разделения мозък.
С такава реализация е много малко вероятно да се случи разделен мозък (ще трябва да бъде въведен чрез някои странни и неочаквани състояния на мрежата, условия на състезание или явни грешки в кода за клъстериране. Макар че не е невъзможно да се срещне при такива условия използването на едно от решенията, които са базирани на кворум, е най-добрият вариант за избягване на разделения мозък, който съществува в този момент.
Асинхронна репликация
Въпреки че не е идеалният избор, когато става въпрос за работа с разделен мозък, асинхронната репликация все още е жизнеспособна опция. Има няколко неща, които трябва да имате предвид, преди да внедрите многооблачна база данни с асинхронна репликация.
Първо, отказ. Асинхронната репликация идва с един записващ - само главният трябва да може да се записва, а другите възли трябва да обслужват само трафик само за четене. Предизвикателството е как да се справим с основната грешка?
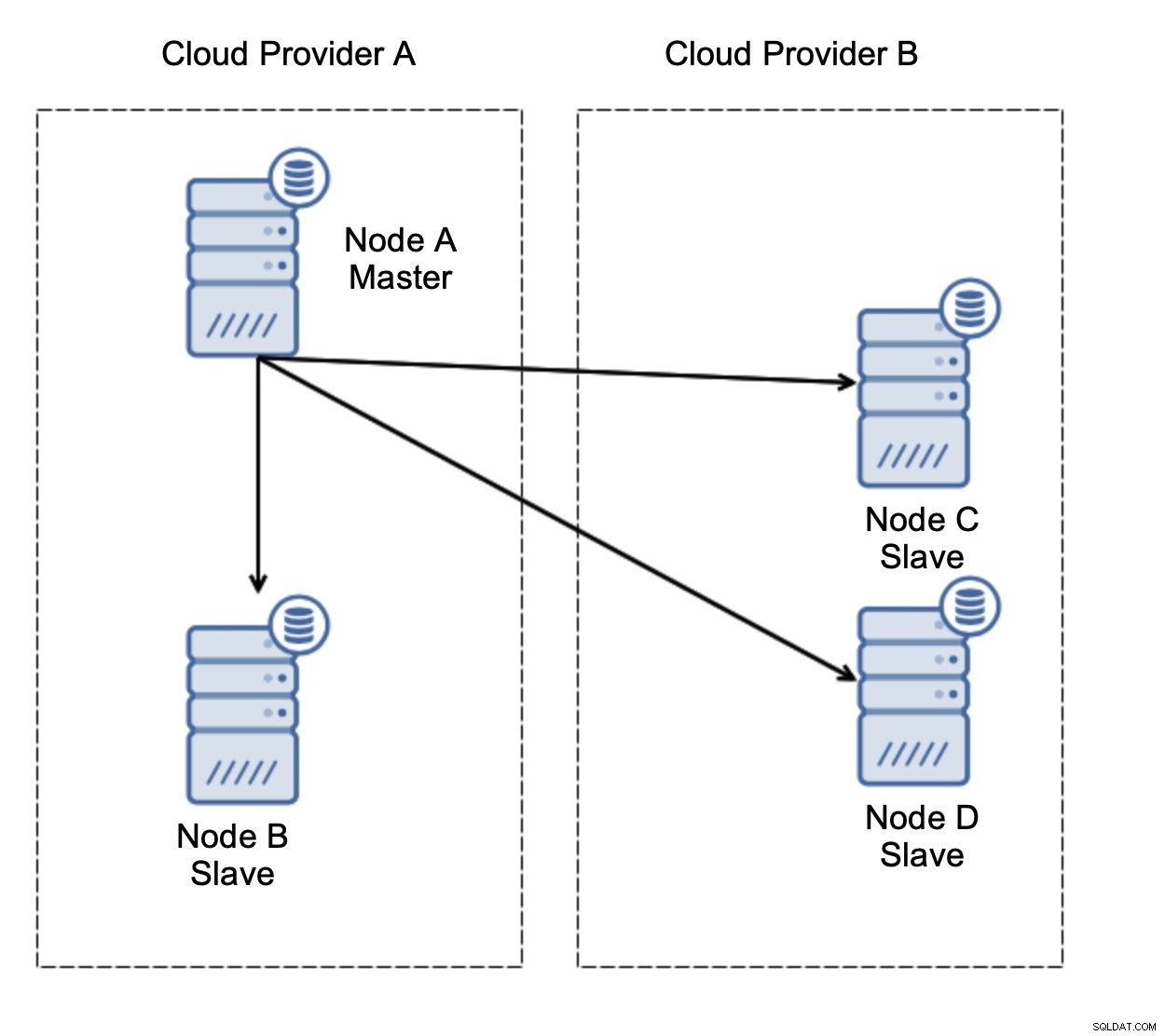
Нека разгледаме настройката, както е показано на диаграмата по-горе. Имаме два облачни доставчика, по два възела във всеки. Доставчик А също така е домакин. Какво трябва да се случи, ако капитанът се провали? Един от подчинените трябва да бъде повишен, за да се гарантира, че базата данни ще продължи да работи. В идеалния случай това трябва да бъде автоматизиран процес за намаляване на времето, необходимо за привеждане на базата данни в работно състояние. Какво ще се случи обаче, ако има мрежово разделяне? Как се очаква да проверим състоянието на клъстера?
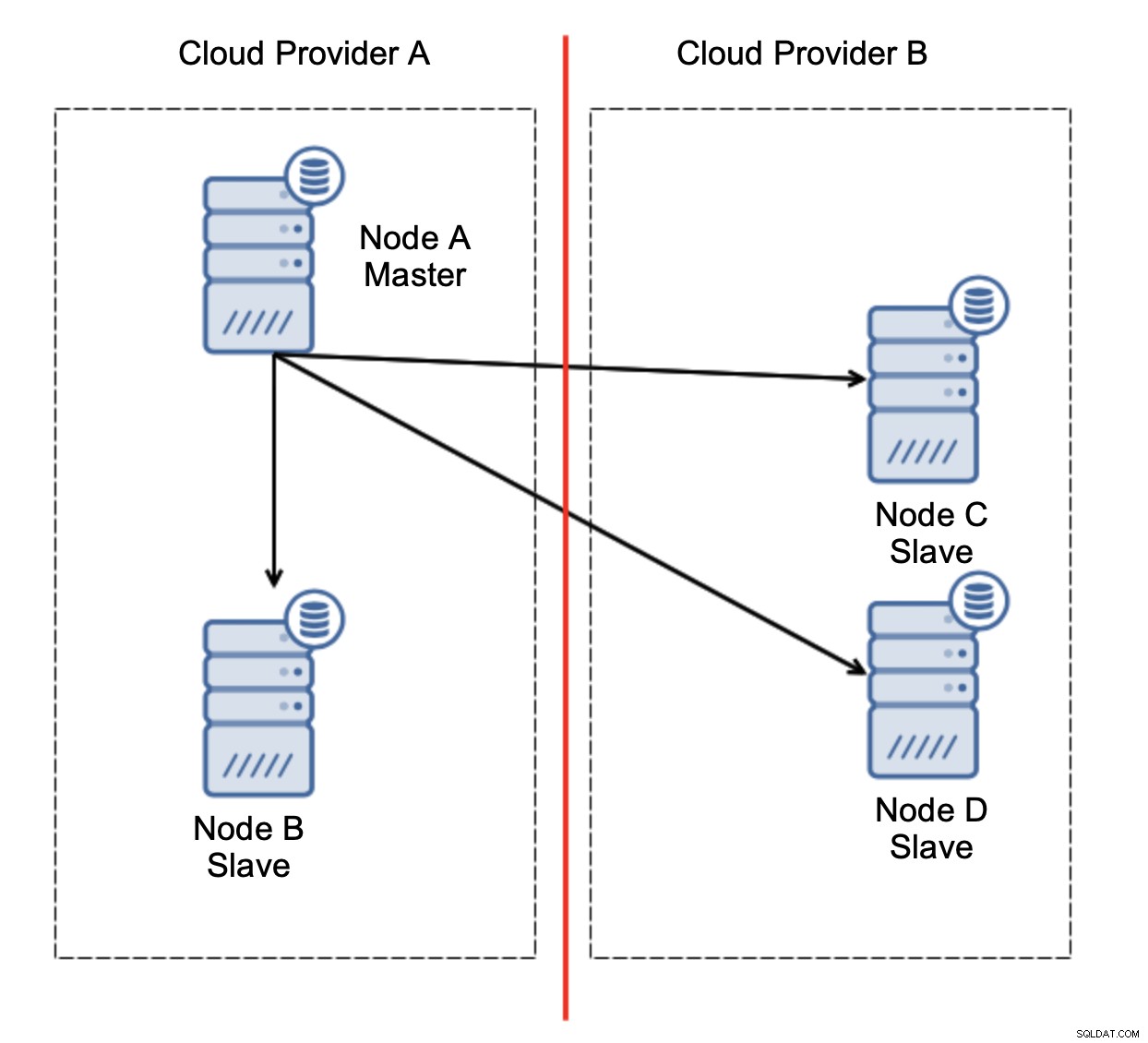
Ето предизвикателството. Мрежовата свързаност се губи между два облачни доставчици. От гледна точка на възлите C и D и възел B и главен, възел A са офлайн. Трябва ли възел C или D да бъде повишен, за да стане главен? Но старият мастер все още е готов - не се е сринал, просто не е достъпен през мрежата. Ако популяризираме един от възлите, разположени при доставчика B, ще се окажем с два записващи глави, два набора от данни и разделен мозък:
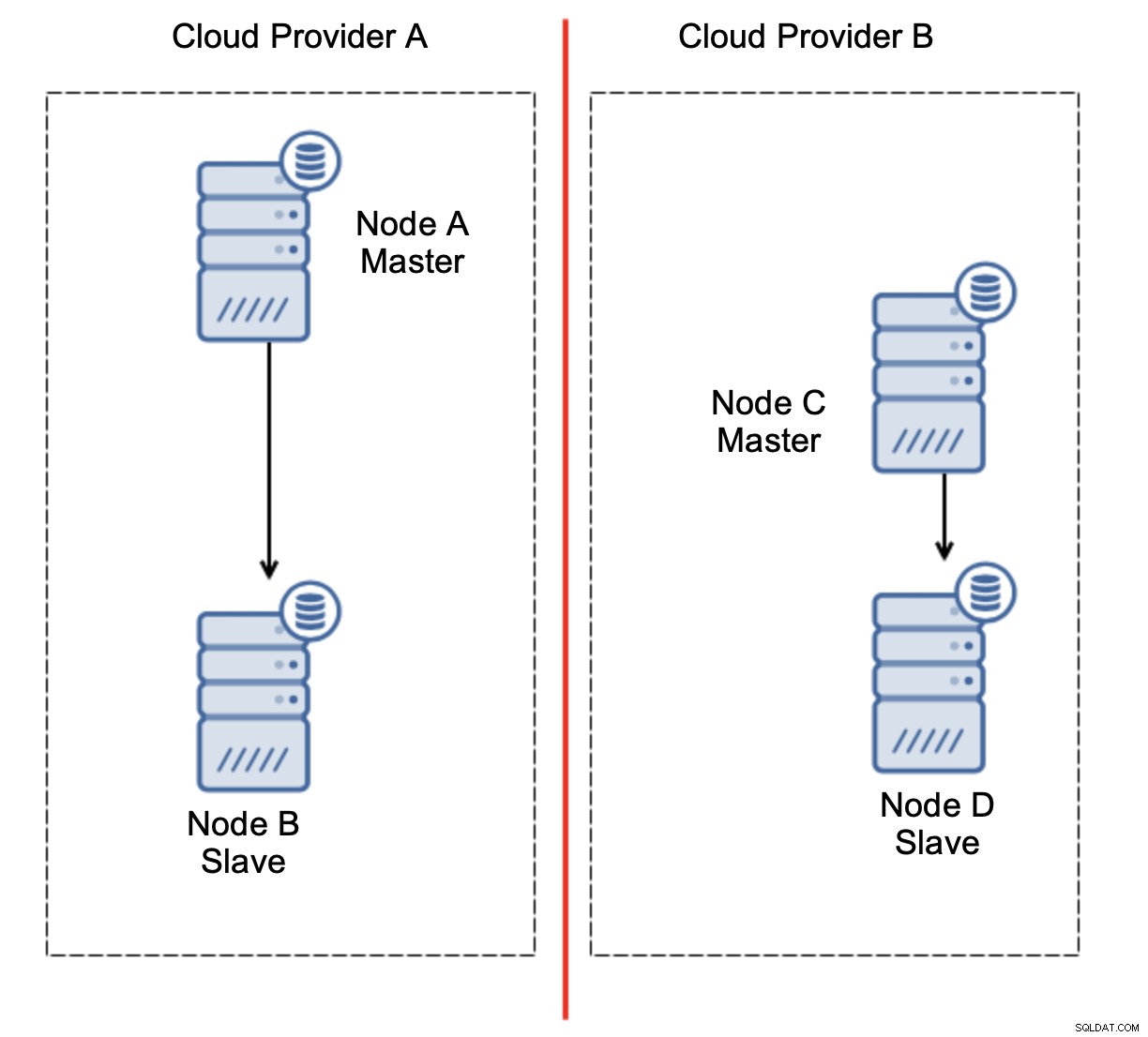
Това определено не е нещо, което искаме. Тук има няколко варианта. Първо, можем да дефинираме правила за преодоляване на срива по начин, при който отказът може да се случи само в един от мрежовите сегменти, където се намира главният. В нашия случай това би означавало, че само възел B може да бъде автоматично повишен в главен. По този начин можем да гарантираме, че автоматичното преминаване на отказ ще се случи, ако възел А не работи, но няма да бъдат предприети действия, ако има мрежово разделяне. Някои от инструментите, които могат да ви помогнат да се справите с автоматизирани откази (като ClusterControl), поддържат бели и черни списъци, позволявайки на потребителите да дефинират кои възли могат да се считат за кандидат за преминаване към отказ и кои никога не трябва да се използват като главни.
Друга вариант би бил да се внедри някакво решение за „осведомяване на топологията“. Например, човек може да се опита да провери главното състояние с помощта на външни услуги като балансьори на натоварване.
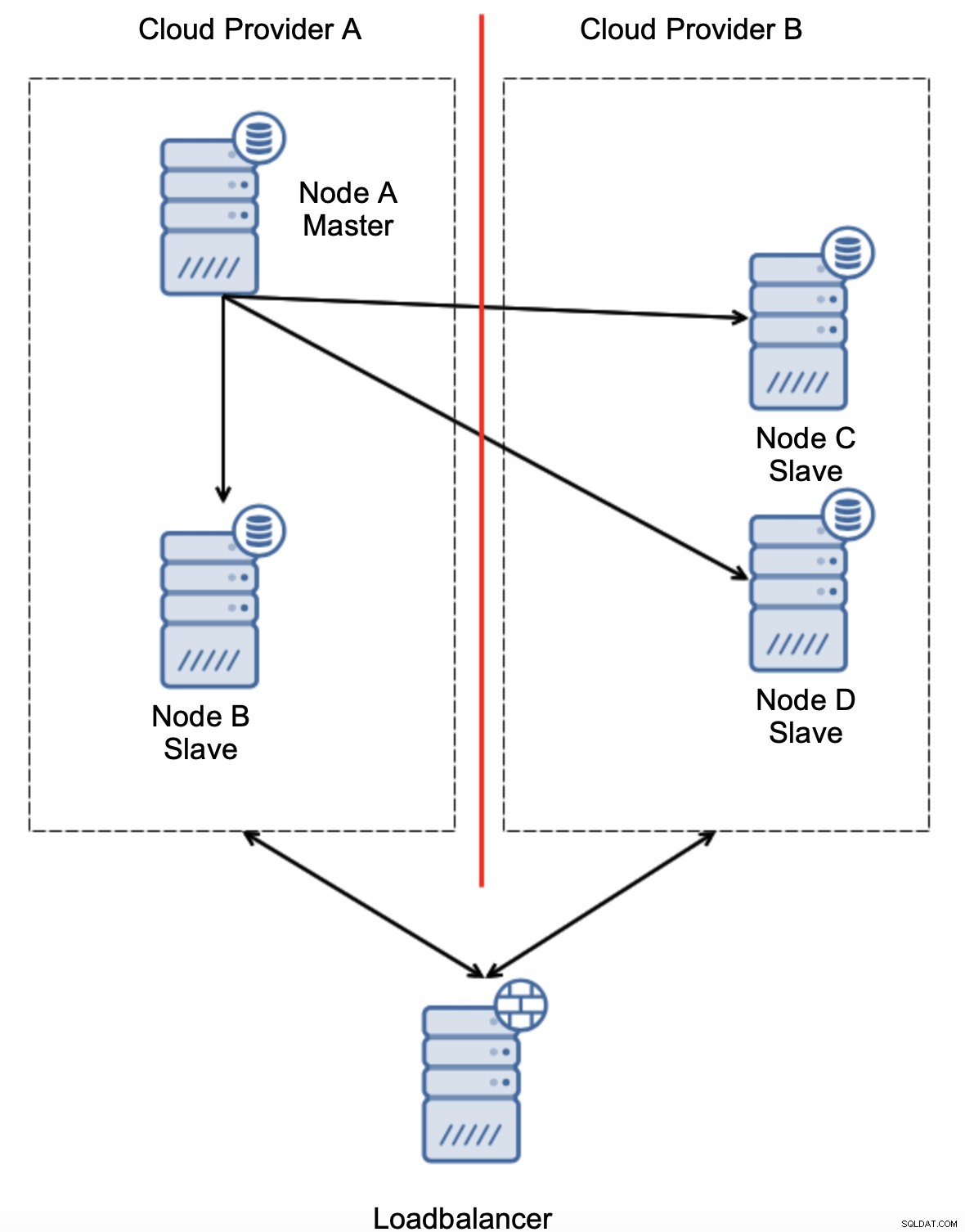
Ако автоматизацията при отказ може да провери състоянието на топологията, както се вижда от балансиращото натоварване, може да се окаже, че балансиращото устройство, разположено на трето място, може действително да достигне до двата центъра за данни и да покаже ясно, че възлите в доставчика на облак A не са изключени, просто не могат да бъдат достигнати от доставчика на облак B. Такива допълнителен слой от проверки е внедрен в ClusterControl.
Накрая, какъвто и инструмент да използвате за внедряване на автоматизиран отказ, той също може да е проектиран така, че да е наясно с кворума. След това, с три възела на три места, можете лесно да разберете коя част от инфраструктурата трябва да се поддържа жива и коя не.
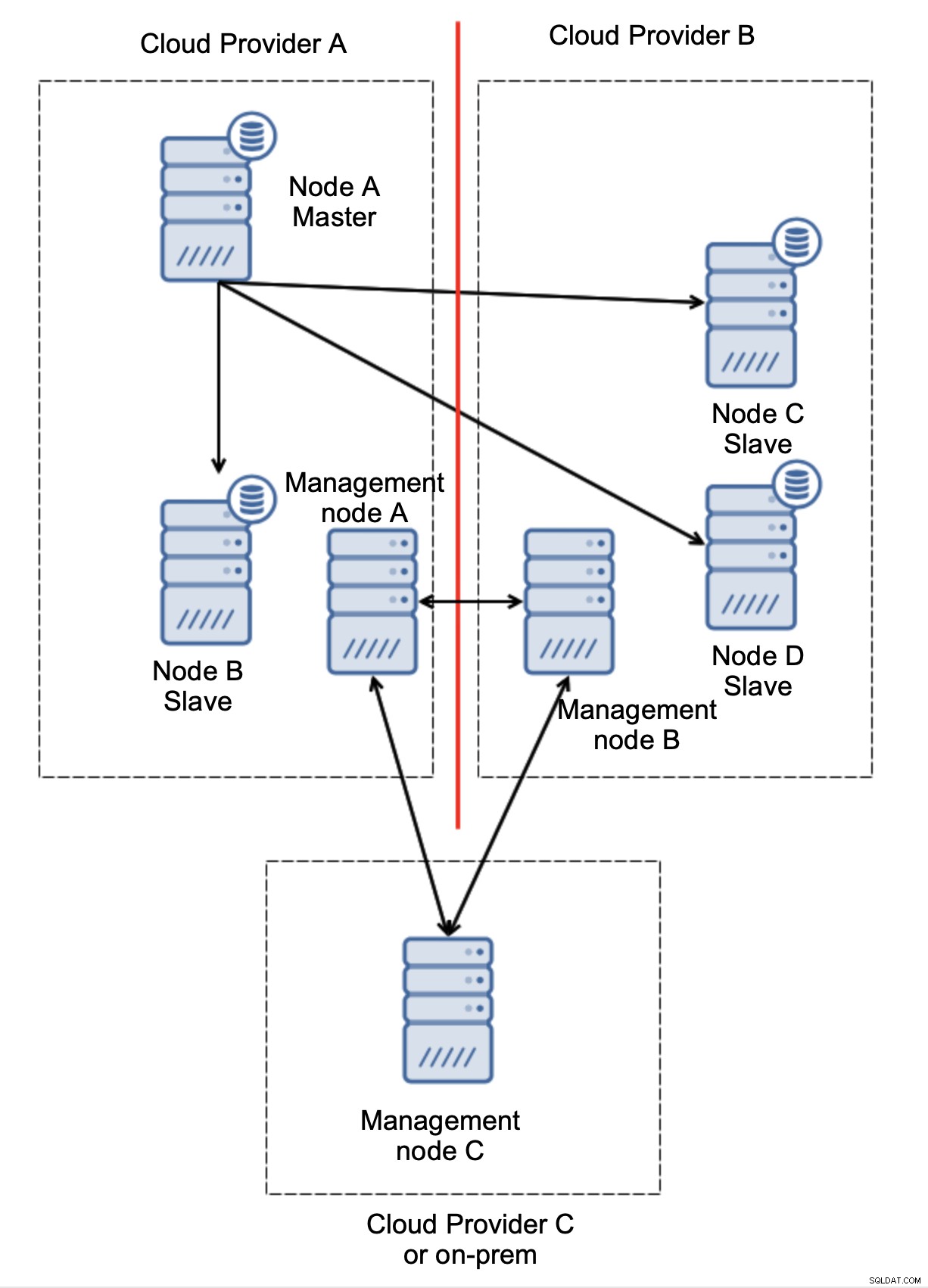
Тук ясно виждаме, че проблемът е свързан само със свързаността между доставчици A и B. Възелът за управление C ще действа като реле и в резултат на това не трябва да се стартира отказване. От друга страна, ако един център за данни е напълно изключен:

Също така е доста ясно какво се е случило. Управляващ възел A ще докладва, че не може да достигне до по-голямата част от клъстера, докато управляващите възли B и C ще формират мнозинството. Възможно е да се надгради върху това и например да се напишат скриптове, които ще управляват топологията според състоянието на управляващия възел. Това може да означава, че скриптовете, изпълнявани в доставчик на облак A, ще открият, че управляващ възел A не формира мнозинството и ще спрат всички възли на базата данни, за да гарантират, че няма да се извършват записи в разделения доставчик на облак.
ClusterControl, когато е разгърнат в режим на висока достъпност, може да се третира като възлите за управление, които използвахме в нашите примери. Три възела ClusterControl, отгоре на протокола RAFT, могат да ви помогнат да определите дали даден мрежов сегмент е разделен или не.
Заключение
Надяваме се, че тази публикация в блога ви дава някаква представа за сценариите с разделен мозък, които могат да се случат за внедряване на MySQL, обхващащо множество облачни платформи.