Като се има предвид текущия основен случай на използване на база данни за извличане на данни, става много важно нейната производителност да е много висока и това може да бъде постигнато само ако данните се извличат по възможно най-ефективния начин от хранилището. Направени са много успешни изобретения и реализации, за да се постигне същото. Един от добре познатите подходи, възприети от повечето бази данни, е да има индекс в таблицата.
Какво е индекс на база данни?
Индексът на базата данни, както подсказва името, поддържа индекс към действителните данни и по този начин подобрява производителността за извличане на данни от действителната таблица. В по-голяма терминология на базата данни, индексът позволява извличане на страница, съдържаща индексирани данни, при много минимално обхождане, тъй като данните се сортират в определен ред. Предимството на индекса идва с цената на допълнително пространство за съхранение, за да се записват допълнителни данни. Индексите са специфични за основната таблица и се състоят от един или повече ключа (т.е. една или повече колони от посочената таблица). Има предимно два типа архитектура на индекси
- Клъстериран индекс – Индексните данни се съхраняват заедно с друга част от данните и данните се сортират въз основа на индексния ключ. Най-много може да има само един индекс в тази категория за определена таблица.
- Неклъстериран индекс – Индексните данни се съхраняват отделно и имат указател към хранилището, където се съхранява друга част от данните. Това е известно още като вторичен индекс. В определена таблица може да има толкова индекси от тази категория, колкото искате.
Има различни структури от данни, използвани за внедряване на индекси, някои от широко разпространените от повечето бази данни са B-Tree и Hash.
Какво е PostgreSQL индекс?
PostgreSQL поддържа само неклъстериран индекс. Това означава индексни данни и пълни данни (тук нататък се наричат хъп данни ) се съхраняват в отделен склад. Неклъстерираните индекси са като „Съдържание“ във всеки документ, при което първо проверяваме номера на страницата и след това проверяваме номерата на тези страници, за да прочетем цялото съдържание. За да получи пълните данни на базата на индекс, той поддържа указател към съответните данни за купчина. Това е същото като след като се знае номерът на страницата, трябва да отиде на тази страница и да получи действителното съдържание на страницата.
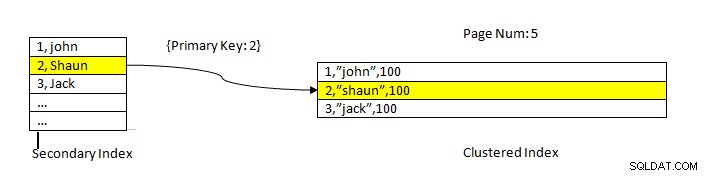
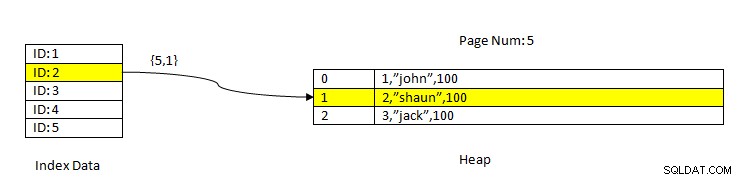 PostgreSQL:Данните се четат с помощта на индекс
PostgreSQL:Данните се четат с помощта на индекс Например, помислете за таблица с три колони и индекс на колона ID . За да се ПРОЧЕТАТ данните въз основа на ключ ID=2, първо се търсят индексирани данни със стойност на ID 2. Това съдържа указател (наричан като указател на елемент) по отношение на номера на страницата (т.е. номера на блок) и отместването на данните в тази страница. В настоящия пример индексът сочи към страница номер 5 и втория ред в страницата, което от своя страна поддържа изместване спрямо всички данни (2,”Shaun”,100). Забележете, че целите данни също съдържат индексирани данни, което означава, че едни и същи данни се повтарят в две хранилища.
Как INDEX помага за подобряване на производителността? Е, за да избере произволен ИНДЕКС запис, той не сканира всички страници последователно, а просто трябва частично да сканира някои от страниците, използвайки основната структура на индексните данни. Но има обрат, тъй като всеки запис, намерен от индексни данни, трябва да търси в Heap данни за цели данни, което причинява много произволни I/O и се счита, че работи по-бавно от Sequential I/O. Така че само ако се избират малък процент от записи (което е решено въз основа на цената на оптимизатора на PostgreSQL), тогава само PostgreSQL избира индексно сканиране, в противен случай, въпреки че има индекс в таблицата, той продължава да използва сканиране на последователността.
В обобщение, въпреки че създаването на индекс ускорява производителността, той трябва да бъде внимателно избран, тъй като има допълнителни разходи по отношение на съхранението, влошена производителност на INSERT.
Сега може да се чудим, в случай че имаме нужда само от индексната част от данните, можем ли да извлечем само от страницата за съхранение на индекса? Е, отговорът на това е пряко свързан с това как MVCC работи върху индексното хранилище, както е обяснено по-долу.
Използване на MVCC за индексиране
Подобно на Heap страниците, индексната страница поддържа множество версии на индексни кортежи, но не поддържа информация за видимост. Както беше обяснено в предишния ми MVCC блог, за да се реши подходяща видима версия на кортежи, той изисква сравнение на транзакцията. Транзакцията, която е вмъкнала/актуализирала/изтрила кортеж, се поддържа заедно с кортеж на купчина, но същото не се поддържа с кортеж с индекс. Това се прави единствено за спестяване на място за съхранение и е компромис между пространство и производителност.
Сега да се върнем към първоначалния въпрос, тъй като информацията за видимост в индексния кортеж не е там, той трябва да се консултира със съответния кортеж на купчина, за да види дали избраните данни са видими. Така че, въпреки че други части от данните от кортежа на купчината не се изискват, все пак трябва да получите достъп до страниците на heap, за да проверите видимостта. Но отново има обрат, в случай че всички кортежи на дадена страница (страница, обозначена с индекс, т.е. ItemPointer) са видими, след което не е необходимо да препращате всеки елемент от Heap страницата за „проверка на видимостта“ и следователно данните могат да бъдат върнати само от индексната страница. Този специален случай се нарича „Сканиране само с индекс“. За да поддържа това, PostgreSQL поддържа карта на видимост за всяка страница, за да провери видимостта на ниво страница.
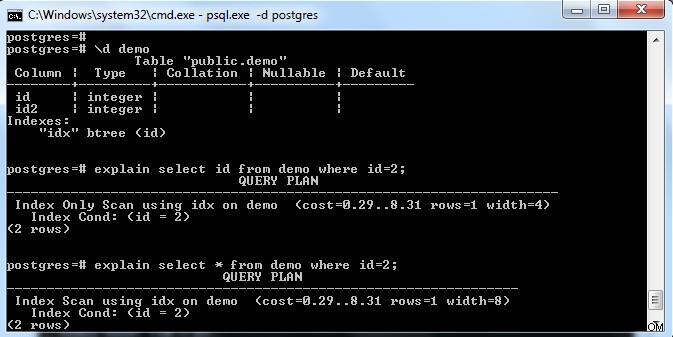
Както е показано на горното изображение, има индекс на таблицата „demo“ с ключ в колона „id“. Ако се опитаме да изберем само индексно поле (т.е. идентификатор), тогава той избра „Сканиране само за индекс“ (като се има предвид, че препращащата страница е напълно видима).
Клъстериран индекс
Няма поддръжка на директен клъстериран индекс в PostgreSQL, но има индиректен начин за частично постигане на същото. Това се постига чрез следните SQL команди:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Първата команда инструктира базата данни да клъстерира таблица (т.е. да сортира таблица) с помощта на даден индекс. Този индекс трябва да е вече създаден. Това групиране е само еднократна операция и влиянието му не остава след последващата операция върху тази таблица, т.е. ако се вмъкнат/актуализират повече записи, таблицата може да не остане подредена. Ако е необходимо на потребителя да поддържа таблицата групирана (подредена), тогава той може да използва първата команда, без да дава име на индекс.
Втората команда е полезна само за повторно клъстериране на таблица (т.е. таблицата, която вече е групирана с помощта на някакъв индекс). Тази команда повторно групира всички таблици в текущата база данни, видими за текущия свързан потребител.
Например на фигурата по-долу първият SELECT връща записи в несортиран ред, тъй като няма клъстериран индекс. Въпреки че вече има неклъстериран индекс, записите се избират от масива, където записите не са сортирани.
Вторият SELECT връща записите, сортирани по колона „id“, тъй като е групирана с помощта на индекс, съдържащ колона „id“.
Третият SELECT връща частични записи в сортиран ред, но нововмъкнатите записи не се сортират. Четвъртият SELECT отново връща всички записи в сортиран ред, тъй като таблицата е отново групирана
 PostgreSQL Cluster Command
PostgreSQL Cluster Command Тип на индекса
PostgreSQL предоставя няколко типа индекси, както е показано по-долу:
- B-дърво
- Хеш
- GiST
- GIN
- BRIN
Всеки тип индекс реализира различни видове основна структура на данни, която е най-подходяща за различни типове заявки. По подразбиране се създава индекс на B-Tree, който е широко използван индекс. Подробности за всеки тип индекс ще бъдат разгледани в бъдещ блог.
Разни:частичен и изразен индекс
Обсъдихме само индекси в една или повече колони на таблица, но има и други два начина за създаване на индекси в PostgreSQL
- Частичен индекс: Частичният индекс е индекс, изграден с помощта на подмножество на ключова колона за конкретна таблица. Подмножеството се дефинира от условния израз, даден по време на създаване на индекс. Така че с частичния индекс се спестява място за съхранение за съхранение на индексни данни. Така че потребителят трябва да избере условието по такъв начин, че това да не са много често срещани стойности, тъй като за по-чести (общи) стойности така или иначе няма да се избира индексно сканиране. Останалата част от функционалността остава същата като при нормален индекс. Пример:Частичен индекс
- Индекс на изрази: Индексите на изрази дават друг вид гъвкавост в PostgreSQL. Всички индекси, обсъждани досега, включително частичните индекси, са в определен набор от колони. Но какво ще стане, ако заявката включва достъп до таблица въз основа на израза (израз, включващ една или повече колони), без индекс на израз тя няма да избере сканиране на индекса. Така че, за да получите бърз достъп до този вид заявки, PostgreSQL позволява да се създаде индекс на израз. Останалата част от функционалността остава същата като при нормален индекс.
 Пример:Индекс на изрази
Пример:Индекс на изрази
Съхранение на индекси в InnoDB
Използването и функционалността на Index са предимно същите като тези в PostgreSQL с голяма разлика по отношение на клъстерния индекс.
InnoDB поддържа две категории индекси:
- Клъстериран индекс
- Вторичен индекс
Клъстериран индекс
Клъстерираният индекс е специален вид индекс в InnoDB. Тук индексираните данни не се съхраняват отделно, а са част от данните от целия ред. С други думи, клъстерираният индекс просто принуждава данните в таблицата да бъдат сортирани физически, като се използва ключовата колона на индекса. Може да се разглежда като „Речник“, където данните се сортират въз основа на азбуката.
Тъй като клъстерираният индекс сортира редове с помощта на индексен ключ, може да има само един клъстериран индекс. Освен това трябва да има един клъстериран индекс, тъй като InnoDB използва същия за оптимално манипулиране на данни по време на различни операции с данни.
Клъстерираният индекс се създава автоматично (като част от създаването на таблица) с помощта на една от колоните на таблицата според приоритета по-долу:
- Използване на първичния ключ, ако първичният ключ е споменат като част от създаването на таблицата.
- Избира всяка уникална колона, където всички ключови колони НЕ са NULL.
- В противен случай вътрешно генерира скрит клъстериран индекс в системна колона, която съдържа идентификатора на реда на всеки ред.
За разлика от неклъстерния индекс на PostgreSQL, InnoDB осъществява достъп до ред, използвайки клъстериран индекс, по-бързо, тъй като търсенето в индекса води директно до страницата с всички данни от редове и по този начин избягва произволно I/O.
Също така получаването на данните в таблицата в сортиран ред с помощта на клъстерирания индекс е много бързо, тъй като всички данни вече са сортирани, а също така са налични и цели данни.
Вторичен индекс
Индексът, създаден изрично в InnoDB, се счита за вторичен индекс, който е подобен на неклъстерния индекс на PostgreSQL. Всеки запис във вторичното хранилище за индекс съдържа колони с първичен ключ на редовете (които са били използвани за създаване на клъстериран индекс), както и колоните, посочени за създаване на вторичен индекс.
 InnoDB:Данните се четат с помощта на индекс
InnoDB:Данните се четат с помощта на индекс Извличането на данни с помощта на вторичен индекс е подобно като в случая на PostgreSQL, с изключение на това, че търсенето на вторичен индекс InnoDB дава първичен ключ като указател за извличане на останалите данни от клъстерирания индекс.
Например, както е показано на горната снимка, клъстерираният индекс е в колона ID, така че данните в таблицата се сортират по същото. Вторичният индекс е в колона „име ”, така че както можем да видим, вторичният индекс има стойност както на ID, така и на име. След като търсим с помощта на вторичния индекс, той намира подходящия слот със съответната стойност на ключа. Тогава съответният първичен ключ се използва за препращане към останалата част от данните от клъстерирания индекс.
MVCC за индекс
Клъстерираният индекс MVCC използва традиционния модел за отмяна на InnoDB (всъщност същото като MVCC за цели данни, тъй като клъстерираният индекс не е нищо друго освен цели данни).
Но вторичният индекс MVCC използва малко по-различен подход за поддържане на MVCC. При актуализиране на вторичния индекс, старият запис в индекса се маркира за изтриване и новите записи се вмъкват в същото хранилище, т.е. UPDATE не е на място. Накрая старите записи в индекса се изчистват. Досега може би сте забелязали, че вторичният индекс на InnoDB MVCC е почти същият като този на PostgreSQL MVCC модела.
Тип на индекса
InnoDB поддържа само индекс тип B-Tree и следователно не се изисква да се посочва при създаване на индекс.
Разни:Адаптивни хеш индекси
Както беше споменато в предишния раздел, само индексът от тип B-Tree се поддържа от InnoDB, но има обрат. InnoDB има функционалността да открива автоматично дали заявката може да се възползва от изграждането на хеш индекс и също така цели данни от таблицата могат да се поберат в паметта, след което автоматично го прави.
Хеш индексът се изгражда с помощта на съществуващия индекс на B-Tree в зависимост от заявката. Ако има множество вторични индекси на B-Tree, тогава той ще избере този, който отговаря на изискванията според заявката. Изграденият хеш индекс не е пълен, той просто изгражда частичен индекс според модела на използване на данни.
Това е една от наистина мощните функции за динамично подобряване на производителността на заявките.
Заключение
Използването на всеки индекс във всяка база данни е наистина полезно за подобряване на производителността на ЧЕТЕНЕ, но в същото време влошава производителността на INSERT/UPDATE, тъй като се нуждае от запис на допълнителни данни. Така че индексът трябва да бъде избран много разумно и трябва да се създава само ако индексните ключове се използват като предикат за извличане на данни.
InnoDB предоставя много добра функция по отношение на клъстерирания индекс, която може да бъде много полезна в зависимост от случаите на употреба. Освен това адаптивното му хеш индексиране е много мощно.
Докато PostgreSQL предоставя различни типове индекси, които наистина могат да дадат опции за обхват на функции и един или всички могат да се използват в зависимост от бизнес случая. Също така частичните и индексите на изразите са доста полезни в зависимост от случая на употреба.