Следва извадка от нашата бяла книга „Как да проектираме високодостъпни среди за бази данни с отворен код“, която може да бъде изтеглена безплатно.
Няколко думи за „Висока наличност“
В наши дни високата наличност е задължителна за всяко сериозно внедряване. Отдавна са отминали дни, когато можете да планирате престой на вашата база данни за няколко часа, за да извършите поддръжка. Ако вашите услуги не са достъпни, губите клиенти и пари. Следователно осигуряването на високодостъпна среда на база данни обикновено има един от най-високите приоритети.
Това представлява значително предизвикателство за администраторите на бази данни. Първо, как да разберете дали вашата среда е много достъпна или не? Как бихте го измерили? Какви са стъпките, които трябва да предприемете, за да подобрите наличността? Как да проектирате настройката си, за да я направите високодостъпна от самото начало?
Има много много HA решения, налични в екосистемата MySQL (и MariaDB), но как да разберем на кои можем да се доверим? Някои решения може да работят при определени специфични условия, но могат да причинят повече проблеми, когато се прилагат извън тези условия. Дори основна функционалност като MySQL репликация, която може да бъде конфигурирана по много начини, може да причини значителна вреда - например кръгова репликация с множество записващи глави. Въпреки че е лесно да се настрои „настройка с няколко главния“ с помощта на репликация, тя може много лесно да се счупи и да ни остави различни набори от данни на различни сървъри. За база данни, която често се счита за единствен източник на истина, компрометираната цялост на данните може да има катастрофални последици.
В следващите глави ще обсъдим изискванията за висока наличност в настройките на базата данни
и как да проектираме системата от самото начало.
Измерване на висока наличност
Какво е висока наличност? За да можете да решите дали дадена среда е силно достъпна или не, човек трябва да има някои показатели за това. Има много начини, по които можете да измервате високата наличност, ние ще се съсредоточим върху някои от най-основните неща.
Първо обаче, нека помислим за какво е цялата тази висока наличност? Каква е целта му? Става дума за това да се уверите, че вашата среда служи на целта си. Целта може да бъде дефинирана по много начини, но обикновено става дума за предоставяне на някаква услуга. В света на базата данни обикновено това е донякъде свързано с данни. Може да обслужва данни към вашето вътрешно приложение. Тя може да бъде да съхранява данни и да ги прави заявени чрез аналитични процеси. Това може да бъде да съхранявате някои данни за вашите потребители и да ги предоставяте, когато бъдат поискани при поискване. След като сме наясно с целта, можем да установим включените фактори за успех. Това ще ни помогне да определим какво означава висока наличност в нашия конкретен случай.
SLA
Споразумение за ниво на обслужване (SLA). Също така е доста често да се дефинират SLA за вътрешни услуги. Какво е SLA? Това е дефиниция на нивото на обслужване, което планирате да предоставите на клиентите си. Това е за тях, за да разберат по-добре какво ниво на стабилност планирате за услуга, която са закупили или планират да купят. Има много методи, които можете да използвате, за да подготвите SLA, но типичните са:
- Наличност на услугата (процент)
- Отзивчивост на услугата – латентност (средна, максимална, 95 персентил, 99 персентил)
- Загуба на пакети през мрежата (процент)
- Пропускателна способност (средна, минимална, 95 персентил, 99 персентил)
Все пак може да стане по-сложно от това. В разделена, многопотребителска среда можете да дефинирате, да речем, вашето SLA като:„Услугата ще бъде достъпна в 99,99% от времето, престой се декларира, когато са засегнати повече от 2% от потребителите. Разрешаването на нито един инцидент не може да отнеме повече от 15 минути”. Такъв SLA може също да бъде разширен, за да включи времето за отговор на заявката:„престой се извиква, ако 99 процентил на латентността за заявки надвишава 200 милисекунди.
Деветки
Наличността обикновено се измерва в „деветки“, нека да разгледаме какво точно гарантира дадено количество „деветки“. Таблицата по-долу е взета от Wikipedia:
| Процент на наличност | Престой на година | Престой на месец | Престой на седмица | Престой на ден |
|---|---|---|---|---|
| 90% („едно девет“) | 36,5 дни | 72 часа | 16,8 часа | 2,4 часа |
| 95% („една деветка и половина“) | 18,25 дни | 36 часа | 8,4 часа | 1,2 часа |
| 97% | 10,96 дни | 21,6 часа | 5,04 часа | 43,2 мин. |
| 98% | 7,30 дни | 14,4 часа | 3,36 часа | 28,8 мин. |
| 99% („две деветки“) | 3,65 дни | 7,20 часа | 1,68 часа | 14,4 минути |
| 99,5% („две деветки и половина“) | 1,83 дни | 3,60 часа | 50,4 мин. | 7,2 минути |
| 99,8% | 17,52 часа | 86,23 мин. | 20,16 минути | 2,88 мин. |
| 99,9% („три деветки“) | 8,76 часа | 43,8 мин. | 10,1 мин. | 1,44 мин |
| 99,95% („три деветки и половина“) | 4,38 часа | 21,56 мин. | 5,04 мин. | 43,2 s |
| 99,99% („четири деветки“) | 52,56 минути | 4,38 минути | 1,01 мин | 8,64 s |
| 99,995% („четири и половина деветки“) | 26,28 минути | 2,16 минути | 30,24 s | 4.32 s |
| 99,999% („пет деветки“) | 5,26 минути | 25,9 s | 6.05 s | 864,3 ms |
| 99,9999% („шест деветки“) | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999% („седем деветки“) | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999% („осем деветки“) | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999% („девет деветки“) | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Както виждаме, ескалира бързо. Пет деветки (99 999% наличност) се равняват на 5,26 минути престой в течение на една година. Наличността може също да се изчислява в различни, по-малки диапазони:на месец, на седмица, на ден. Имайте предвид тези числа, тъй като те ще бъдат полезни, когато започнем да обсъждаме разходите, свързани с поддържането на различни нива на наличност.
Измерване на наличността
За да разберете дали има прекъсване или не, човек трябва да има поглед върху околната среда. Трябва да проследявате показателите, които определят наличността на вашите системи. Важно е да имате предвид, че трябва да го измервате от гледна точка на клиента, като вземете предвид по-широката картина. Няма значение дали базите ви данни са актуални, ако, да речем, поради проблем с мрежата никое приложение не може да достигне до тях. Всеки отделен градивен елемент от вашата настройка има своето влияние върху наличността.
Едно от добрите места, където да търсите данни за наличност, са регистрационните файлове на уеб сървъра. Всички заявки, които завършиха с грешки, означават, че нещо се е случило. Може да е HTTP грешка 500, върната от приложението, защото връзката с базата данни е неуспешна. Това може да са програмни грешки, сочещи към някои проблеми с базата данни и които се озовават в регистъра за грешки на Apache. Можете също да използвате проста метрика като време на работа на сървърите на бази данни, въпреки че при по-сложни SLA може да е трудно да се определи как липсата на една база данни се е отразила на вашата потребителска база. Каквото и да правите, трябва да използвате повече от един показател – това е необходимо, за да уловите проблеми, които може да са се случили на различни слоеве на вашата среда.
Магическо число:„Три“
Въпреки че високата наличност също е свързана с излишък, в случай на клъстери от база данни, три е магическо число. Не е достатъчно да имате два възела за резервиране - такава настройка не осигурява никаква вградена висока наличност. Разбира се, може да е по-добре от само един възел, но е необходима човешка намеса за възстановяване на услугите. Нека видим защо е така.
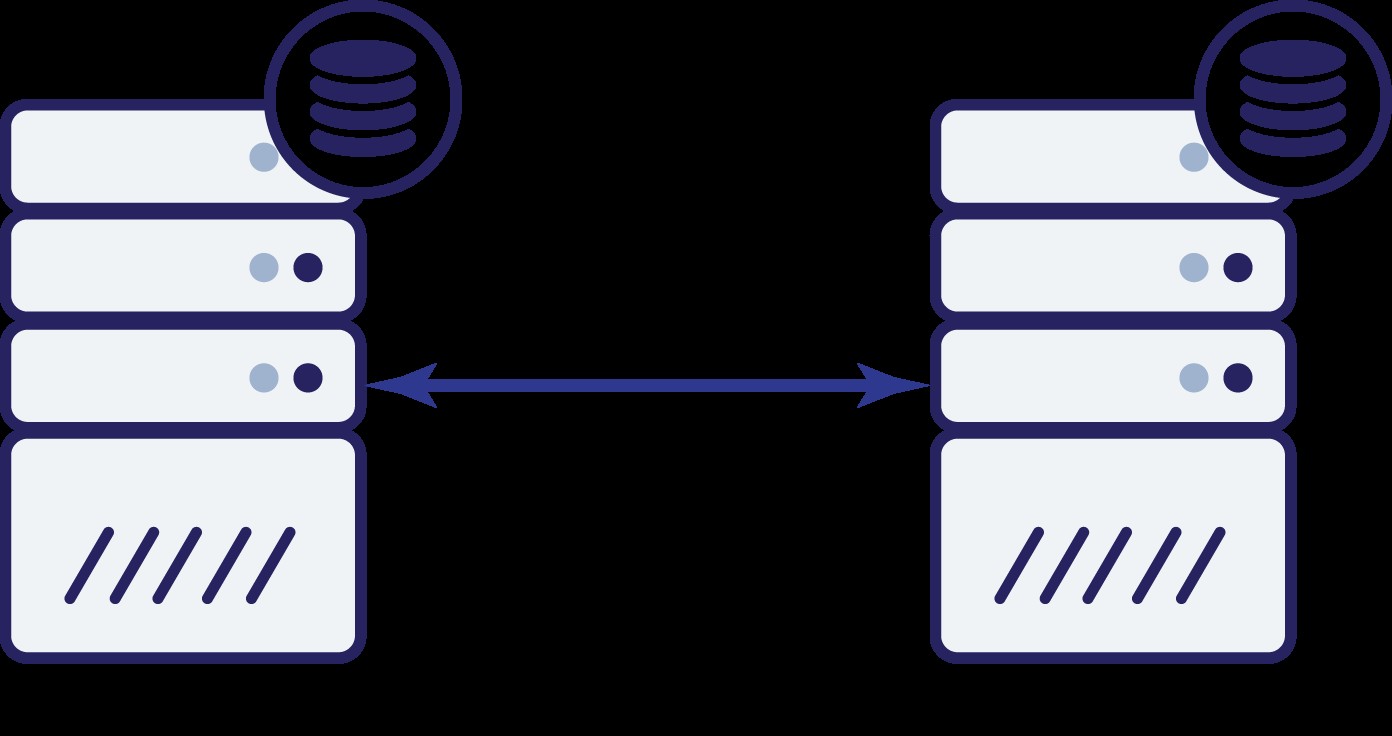
Да приемем, че имаме два възела, A и B. Между тях има мрежова връзка. Да приемем, че и A, и B обслужват запис и приложението избира произволно къде да се свърже (което означава, че част от приложението ще се свърже с възел A, а другата част ще се свърже с възел B). Сега, нека си представим, че имаме проблем с мрежата, който води до загуба на мрежова връзка между A и B.
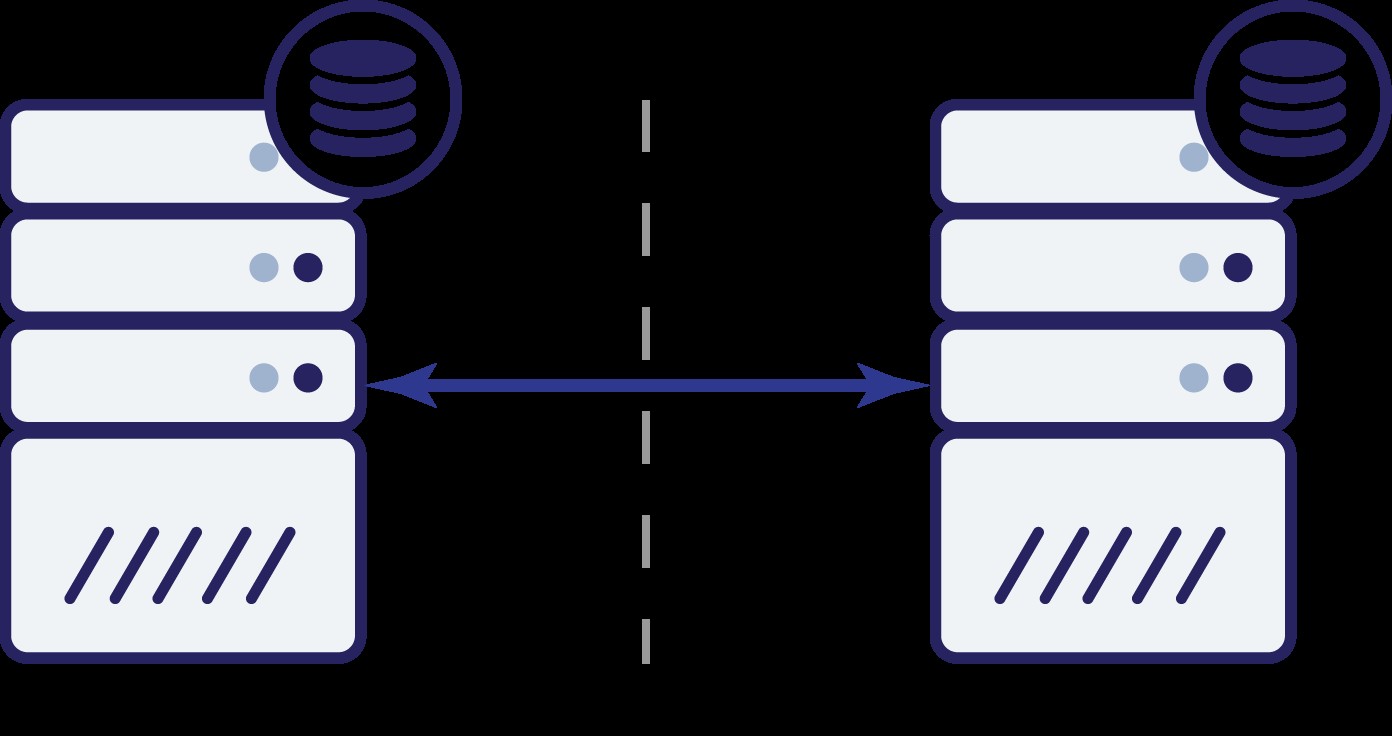
Сега какво? Нито A, нито B могат да знаят състоянието на другия възел. Има две действия, които могат да бъдат предприети от двата възела:
- Могат да продължат да приемат трафик
- Могат да спрат да работят и да откажат да обслужват трафик
Нека помислим за първия вариант. Докато другият възел наистина не работи, това е предпочитаното действие - искаме нашата база данни да продължи да обслужва трафик. В крайна сметка това е основната идея зад високата наличност. Какво би се случило обаче, ако и двата възела продължат да приемат трафик, докато са изключени един от друг? Нови данни ще бъдат добавени от двете страни и наборите от данни ще излязат от синхрон. Когато проблемът с мрежата бъде разрешен, ще бъде трудна задача да обедините тези два набора от данни. Следователно не е приемливо да се поддържат и двата възела работещи. Проблемът е - как може възел A да разбере дали възел B е жив или не (и обратно)? Отговорът е - не може. Ако цялата свързаност е прекъсната, няма начин да се разграничи неуспешен възел от неуспешна мрежа. В резултат на това единственото безопасно действие е и двата възела да спрат всички операции и да откажат
обслужват трафик.
Нека сега да помислим как трети възел може да ни помогне в такава ситуация.
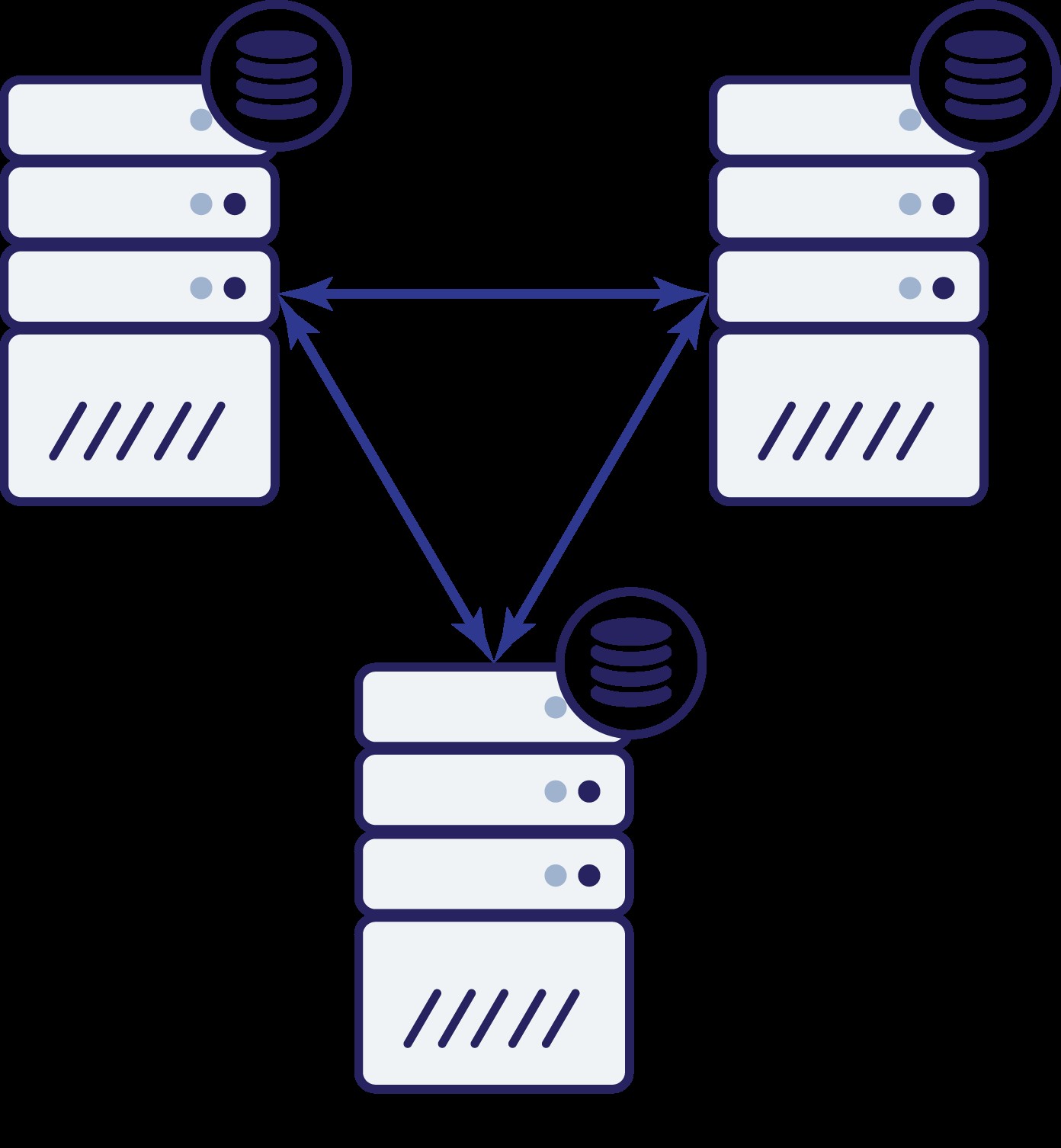
Така че вече имаме три възела:A, B и C. Всички са свързани помежду си, всички обработват четене и запис.
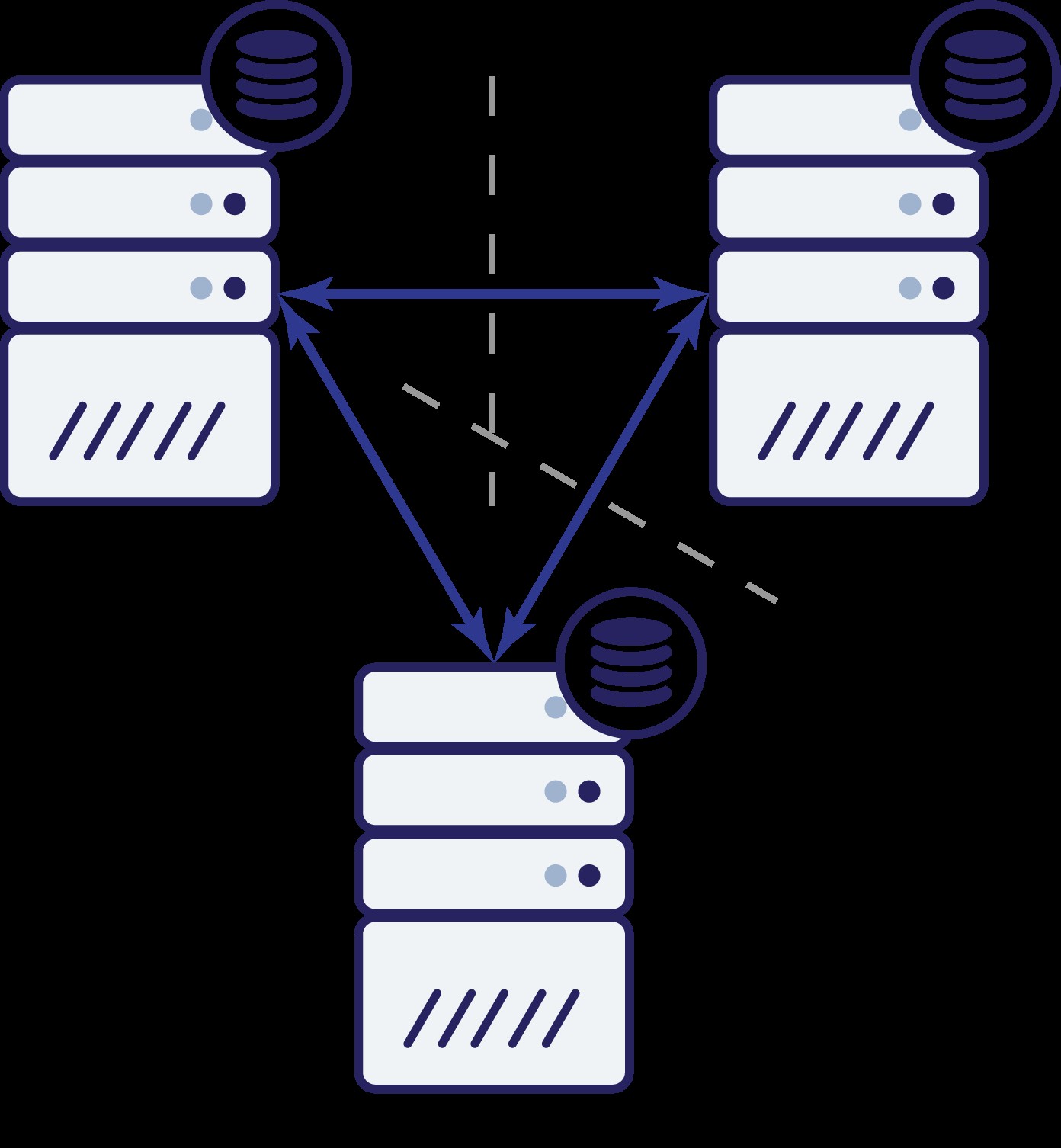
Отново, както в предишния пример, възел B е отрязан от останалата част от клъстера поради проблеми с мрежата. Какво може да се случи след това? Е, ситуацията е доста подобна на това, което обсъдихме по-рано. Две опции - възел B може или да е надолу (а останалата част от клъстера трябва да продължи), или да е нагоре, в който случай не трябва да му се разрешава да обработва трафик. Можем ли сега да кажем какво е състоянието на клъстера? Всъщност да. Можем да видим, че възлите A и C могат да говорят помежду си и в резултат на това те могат да се съгласят, че възел B не е наличен. Те няма да могат да кажат защо се е случило, но това, което знаят е, че от три възела в клъстера два все още имат връзка помежду си. Като се има предвид, че тези два възела формират по-голямата част от клъстера, това прави възможно продължаването на обработката на трафика. В същото време възел B може също да заключи, че проблемът е от негова страна. Не може да има достъп нито до възел A, нито до възел C, което прави възел B отделен от останалата част от клъстера. Тъй като е изолиран и не е част от мнозинството (1 от 3), единственото безопасно действие, което може да предприеме, е да спре да обслужва трафик и да откаже да приеме каквито и да е заявки, като гарантира, че няма да се случи отклоняване на данните.
Разбира се, това не означава, че можете да имате само три възела в клъстера. Ако искате по-добра толерантност към неуспехи, може да искате да добавите още. Имайте предвид обаче, че трябва да е нечетно число, ако искате да подобрите високата наличност. Освен това говорихме за „възли“ в примерите по-горе. Моля, имайте предвид, че това важи и за центрове за данни, зони за достъпност и т.н. Ако имате два центъра за данни, всеки от които има еднакъв брой възли (да кажем три възела всеки), и губите връзка между тези два DC, тук важат същите принципи - не можете да кажете коя половина от клъстера трябва да започне да обработва трафика. За да можете да разберете това, трябва да имате наблюдател в трети център за данни. Това може да бъде още един набор от възли или само един хост със задача
да наблюдава състоянието на останалите информационни центрове и да участва във вземането на решения (пример тук би бил арбитърът на Galera).
Единични точки на отказ
Високата наличност е свързана с премахването на единични точки на повреда (SPOF) и без въвеждане на нови в процеса. Какво представляват SPOF? Всяка част от вашата инфраструктура, която при неуспех води до престой, както е определено в SLA, се нарича SPOF. Проектирането на инфраструктурата изисква холистичен подход, различните компоненти не могат да бъдат проектирани независимо един от друг. Най-вероятно вие не носите отговорност за целия дизайн -
администраторите на бази данни са склонни да се фокусират върху бази данни, а не, например, върху мрежовия слой. Все пак трябва да имате предвид другите части и да работите с екипите, които отговарят за тях, за да сте сигурни, че не само частта, за която отговаряте, е проектирана правилно, но и че останалите части от инфраструктурата са проектирани с помощта на същите принципи. На всичкото отгоре, такова познаване как е проектирана цялата
инфраструктура, ви помага да проектирате и стека на базата данни. Познаването на проблемите, които могат да възникнат, помага да се изградят някои механизми, за да се предотврати тяхното въздействие върху наличността на базата данни.