Настройката на клъстер за репликация главен/подчинен е често срещан случай на използване в повечето организации. Използването на MySQL Replication позволява вашите данни да бъдат репликирани в различни среди и гарантира, че информацията ще бъде копирана. Той е асинхронен и еднонишков (по подразбиране), но репликацията също ви позволява да го конфигурирате да бъде синхронна (или всъщност „полусинхронна“) и може да изпълнява подчинена нишка към множество нишки или паралелно.
Тази идея е много често срещана и обикновено пристига с проста настройка, като нейната подчинена служи като негово възстановяване или за резервни решения. Това обаче винаги идва на цена, особено когато се репликират лоши заявки (като липса на първични или уникални ключове) или някои проблеми с хардуера (като проблеми с мрежовия или дисков IO). Когато възникнат тези проблеми, най-често срещаният проблем е забавянето на репликацията.
Закъснението при репликация е цената на забавянето за транзакция(и) или операция(и), изчислена чрез нейната времева разлика на изпълнение между първичния/главния спрямо резервния/подчинения възел. Най-сигурните случаи в MySQL разчитат на лоши заявки, които се репликират, като липса на първични ключове или лоши индекси, лош мрежов хардуер или неправилно функционираща мрежова карта, отдалечено местоположение между различни региони или зони или някои процеси, като извършване на физическо архивиране, могат да причинят вашата база данни MySQL, за да забавите прилагането на текущата реплицирана транзакция. Това е много често срещан случай при диагностициране на тези проблеми. В този блог ще проверим как да се справяме с тези случаи и какво да търсим, ако изпитвате забавяне на репликацията на MySQL.
"ПОКАЗВАНЕ НА СТАТУС НА ДОБРЕ":Мантрата на MySQL DBA
В някои случаи това е сребърният куршум, когато се занимавате със забавяне на репликацията и разкрива предимно всичко, което е причината за проблем във вашата MySQL база данни. Просто изпълнете този SQL оператор във вашия подчинен възел, за който се подозира, че изпитва забавяне на репликацията.
Началните полета, които са общи за проследяване за проблеми, са,
- Slave_IO_State - Това ви казва какво прави нишката. Това поле ще ви предостави добра информация дали здравето на репликацията работи нормално, изправени пред мрежови проблеми като повторно свързване към главен сървър или отнема твърде много време за запис на данни, което може да показва проблеми с диска при синхронизиране на данни с диск. Можете също да определите тази стойност на състоянието, когато изпълнявате SHOW PROCESSLIST.
- Master_Log_File - Името на binlog файла на главния, където в момента се извлича I/O нишката.
- Read_Master_Log_Pos - позиция на binlog файла от главния, където репликационната I/O нишка вече е прочетена.
- Relay_Log_File - името на релейния регистрационен файл, за който SQL нишката в момента изпълнява събитията
- Relay_Log_Pos - позиция на binlog от файла, посочен в Relay_Log_File, за който SQL нишката вече е изпълнена.
- Relay_Master_Log_File – Главният binlog файл, който SQL нишката вече е изпълнила и съответства на Read_Master_Log_Pos стойност.
- Seconds_Behind_Master - това поле показва приблизителна разлика между текущото времево клеймо на подчинения спрямо клеймото за време на главния за събитието, което в момента се обработва на подчинения. Въпреки това, това поле може да не е в състояние да ви каже точното изоставане, ако мрежата е бавна, тъй като разликата в секунди се приема между подчинената SQL нишка и подчинената I/O нишка. Така че може да има случаи, че може да бъде настигнат с бавно четеща подчинена I/O нишка, но аз го владея вече е различно.
- Slave_SQL_Running_State - състояние на SQL нишката и стойността е идентична със стойността на състоянието, показана в SHOW PROCESSLIST.
- Retrieved_Gtid_Set - Предлага се при използване на репликация на GTID. Това е наборът от GTID, съответстващ на всички транзакции, получени от този подчинен.
- Executed_Gtid_Set - Предлага се при използване на репликация на GTID. Това е набор от GTID, записани в двоичния регистър.
Например, нека вземем примера по-долу, който използва репликация на GTID и изпитва забавяне на репликацията:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)При диагностициране на проблеми като този, mysqlbinlog може също да бъде вашият инструмент, за да идентифицирате каква заявка се изпълнява на конкретна позиция binlog x &y. За да определим това, нека вземем Retrieved_Gtid_Set, Relay_Log_Pos и Relay_Log_File. Вижте командата по-долу:
[example@sqldat.com mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET example@sqldat.com_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Той ни казва, че се е опитвал да репликира и изпълни DML оператор, който се опитва да бъде източникът на изоставането. Тази таблица е огромна таблица, съдържаща 13M редове.
Проверете SHOW PROCESSLIST, SHOW ENGINE INNODB STATUS, с комбинация от команди ps, top, iostat
В някои случаи ПОКАЗВАНЕ НА СТАТУСА НА ПОДЧИСТВОТО не е достатъчно, за да ни каже виновника. Възможно е репликираните оператори да са засегнати от вътрешни процеси, изпълнявани в подчинената база данни на MySQL. Изпълнението на операторите SHOW [FULL] PROCESSLIST и SHOW ENGINE INNODB STATUS също предоставя информативни данни, които ви дават представа за източника на проблема.
Например, да кажем, че работи инструмент за сравнителен анализ, което води до насищане на дисковия IO и CPU. Можете да проверите, като изпълните и двата SQL оператора. Комбинирайте го с ps и top команди.
Можете също да определите тесни места с вашето дисково хранилище, като стартирате iostat, който предоставя статистически данни за текущия обем, който се опитвате да диагностицирате. Изпълнението на iostat може да покаже колко зает или натоварен е вашият сървър. Например, взето от подчинен, който изостава, но също така изпитва високо използване на IO в същото време,
[example@sqldat.com ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Резултатът по-горе показва високото използване на IO и високото ниво на запис. Той също така разкрива, че средният размер на опашката и средният размер на заявката се движат, което означава, че това е индикация за голямо натоварване. В тези случаи трябва да определите дали има външни процеси, които карат MySQL да задушава нишките за репликация.
Как може ClusterControl да помогне?
С ClusterControl справянето с подчинено забавяне и определянето на виновника е много лесно и ефективно. Той директно ви казва в уеб потребителския интерфейс, вижте по-долу:
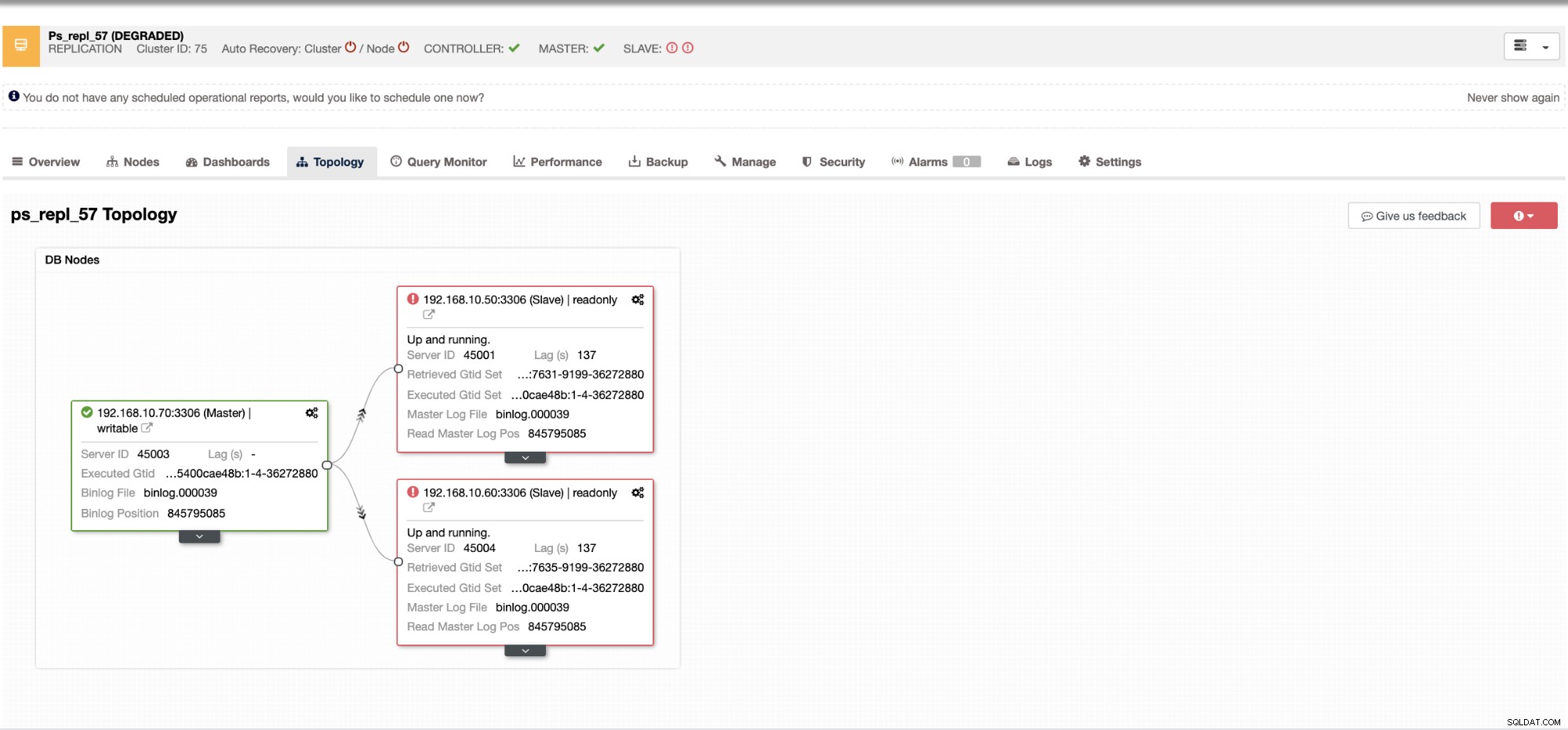
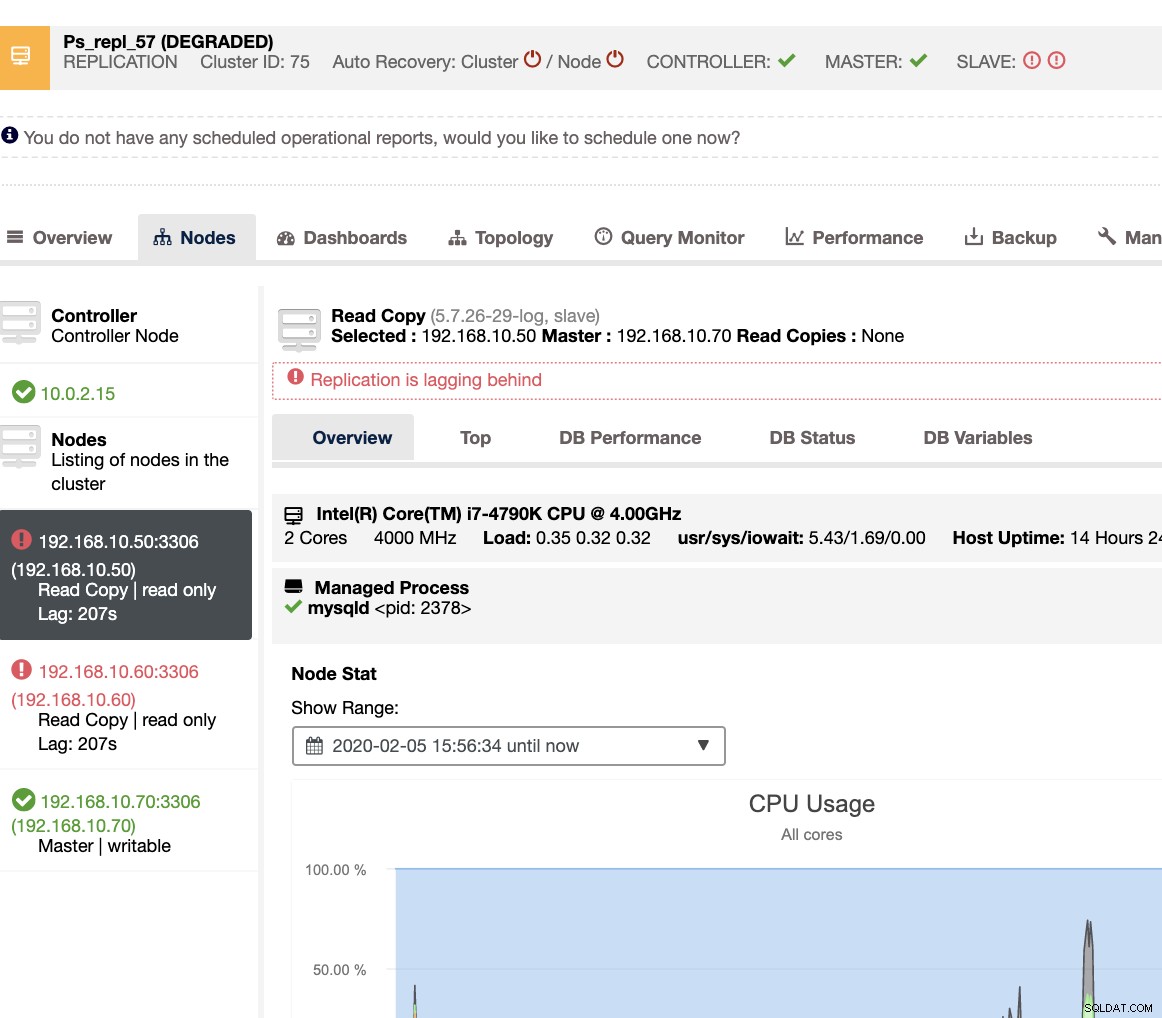
Той ви разкрива текущото забавяне на подчинените устройства, което изпитват вашите подчинени възли. Не само това, с таблата за управление на SCUMM, ако са активирани, ви предоставят повече представа за здравето на вашия подчинен възел или дори за целия клъстер:
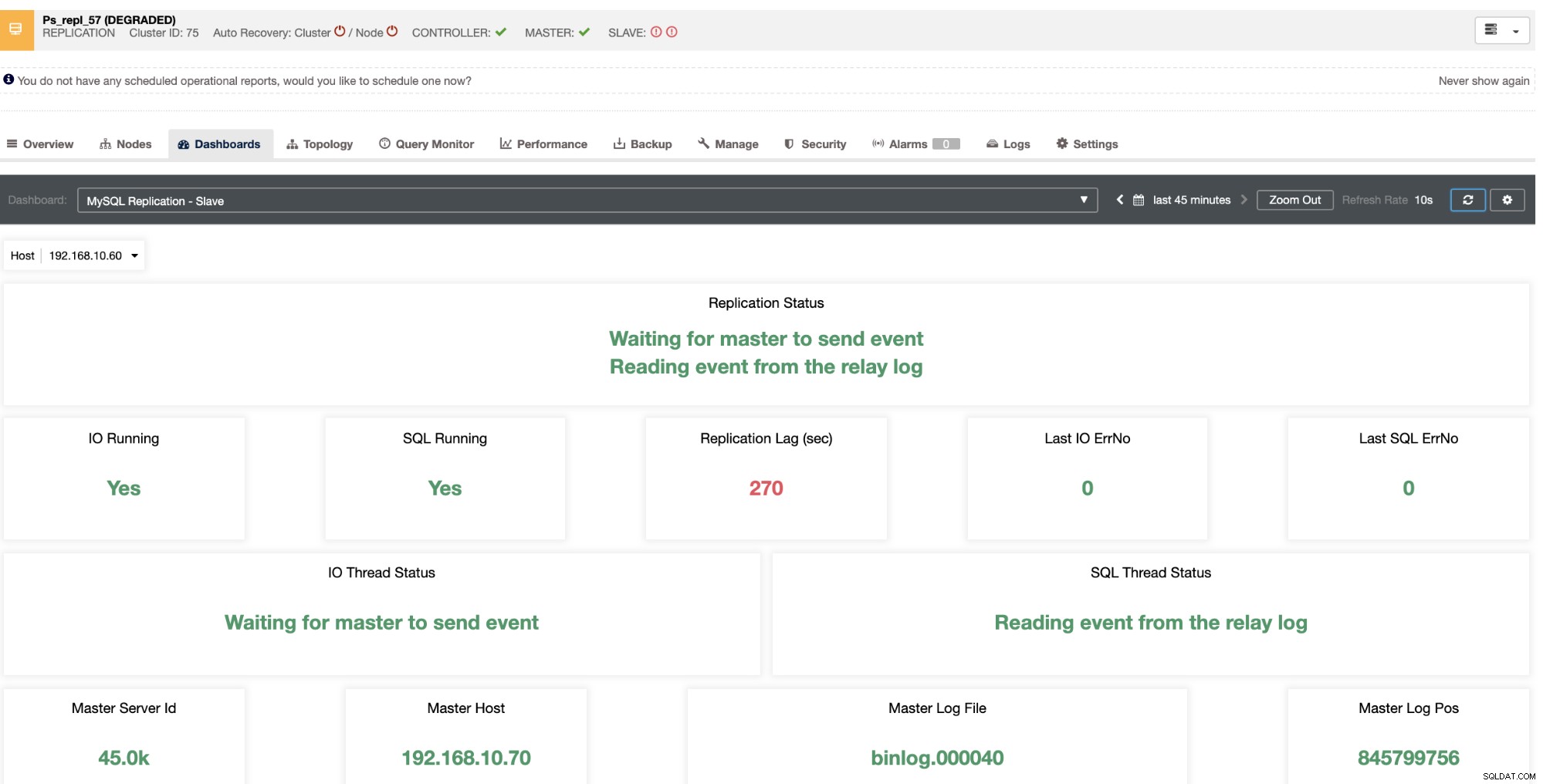


Не само, че тези неща са налични в ClusterControl, но и ви предоставят способността да се избягват възникването на лоши заявки с тези функции, както се вижда по-долу,
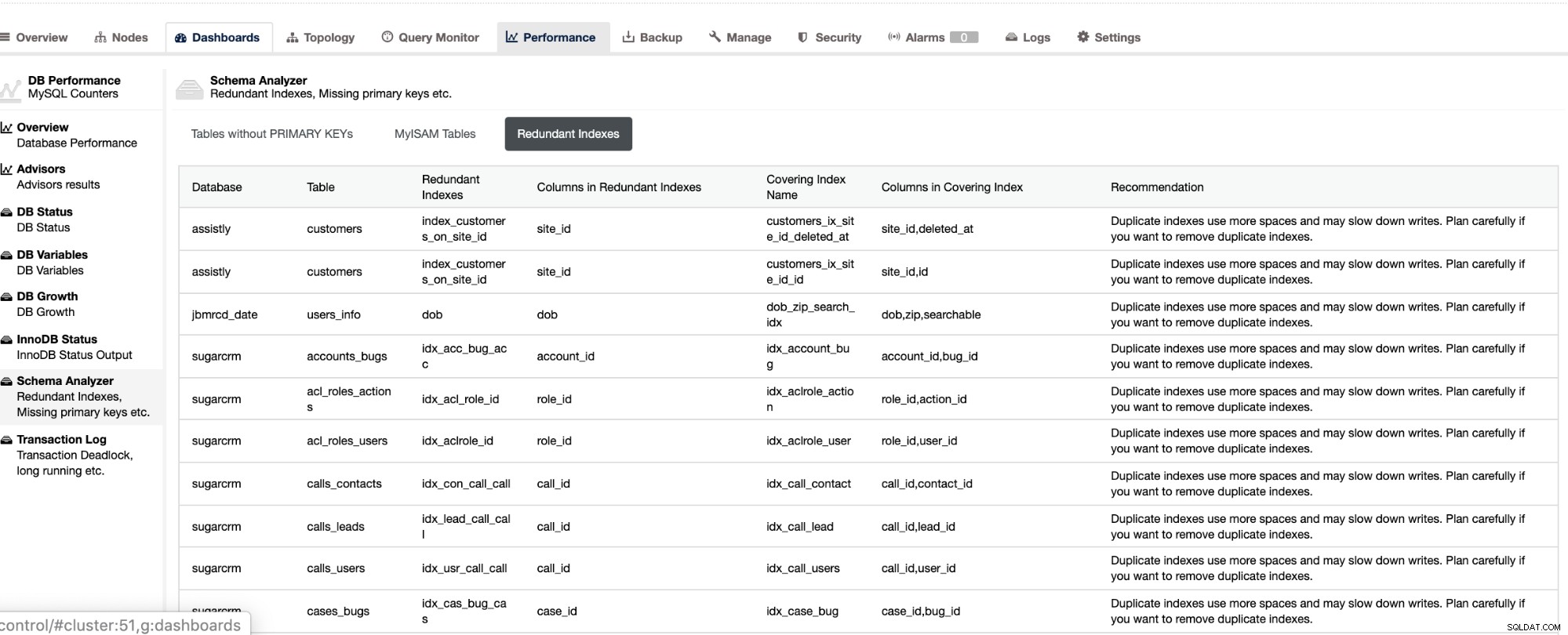
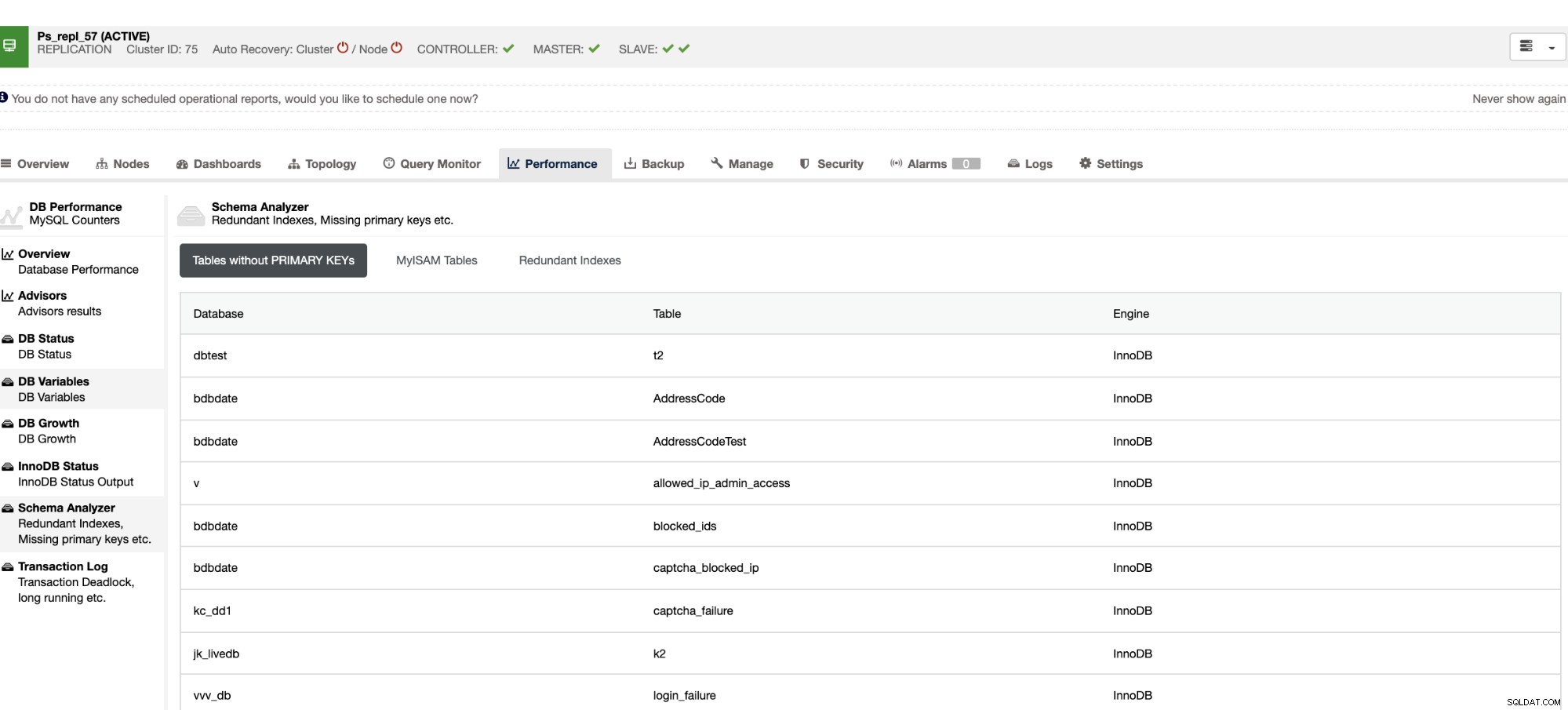
Излишните индекси ви позволяват да определите, че тези индекси могат да причинят проблеми с производителността за входящи заявки, които препращат към дублиращите се индекси. Той също така ви казва таблици, които нямат първични ключове, които обикновено са често срещан проблем на подчинено забавяне, когато определена SQL заявка или транзакции, които препращат към големи таблици без първични или уникални ключове, когато се репликират на подчинените.
Заключение
Справянето със забавянето на репликацията на MySQL е често срещан проблем в настройката на главен-подчинен репликация. Може лесно да се диагностицира, но трудно да се реши. Уверете се, че имате съществуващи таблици с първичен или уникален ключ и определете стъпките и инструментите за отстраняване на неизправности и диагностика на причината за забавяне на подчинените. Ефективността винаги е ключът при решаването на проблеми.