Изграждане на висока наличност, стъпка по стъпка
Когато става въпрос за инфраструктура на бази данни, всички ние я искаме. Всички се стремим да изградим високодостъпна настройка. Резервирането е ключът. Започваме да прилагаме съкращения на най-ниското ниво и продължаваме нагоре по стека. Започва се с хардуер - излишни захранвания, излишно охлаждане, дискове с гореща смяна. Мрежов слой - множество NIC, свързани заедно и свързани към различни комутатори, които използват излишни рутери. За съхранение използваме дискове, зададени в RAID, което дава по-добра производителност, но също така и излишък. След това, на ниво софтуер, ние използваме клъстерни технологии:множество възли на база данни, работещи заедно, за да внедрят излишък:MySQL Cluster, Galera Cluster.
Всичко това не е добре ако имате всичко в един център за данни:когато център за данни изпадне, или част от услугите (но важни) излязат в офлайн режим, или дори ако загубите връзка с центъра за данни, услугата ви ще изпадне - независимо от количеството съкращения в по-ниските нива. И да, тези неща се случват.
- Прекъсването на услугата S3 предизвика хаос в региона US-East-1 през февруари 2017 г.
- Прекъсване на услугата EC2 и RDS в източния регион на САЩ през април 2011 г.
- EC2, EBS и RDS бяха прекъснати в региона ЕС-Запад през август 2011 г.
- Прекъсване на електрозахранването свали Rackspace Texas DC през юни 2009 г.
- Повреда на UPS причини стотици сървъри да излязат офлайн в Rackspace London DC през януари 2010 г.
Това в никакъв случай не е пълен списък с неуспехи, това е просто резултат от бързо търсене в Google. Те служат като примери, че нещата може и ще се объркат, ако сложите всичките си яйца в една и съща кошница. Още един пример би бил ураганът Санди, който предизвика огромно изтичане на данни от САЩ-Изток към САЩ-Западен окръг Колумбия - по това време трудно бихте могли да завъртите случаи в САЩ-Запад, тъй като всички се втурнаха да преместят инфраструктурата си на другия бряг в очакване че Северна Вирджиния ще бъде сериозно засегната от времето.
Така че настройките с множество центрове за данни са задължителни, ако искате да изградите среда с висока наличност. В тази публикация в блога ще обсъдим как да изградим такава инфраструктура с помощта на Galera Cluster за MySQL/MariaDB.
Концепции на Galera
Преди да разгледаме конкретни решения, нека отделим известно време, обяснявайки две концепции, които са много важни при високодостъпни, мулти-DC настройки на Galera.
Кворум
Високата наличност изисква ресурси – а именно, имате нужда от редица възли в клъстера, за да го направите високодостъпен. Един клъстер може да толерира загубата на някои от членовете си, но само до известна степен. Отвъд определен процент неуспехи, може да разглеждате сценарий с разделен мозък.
Нека вземем пример с настройка с 2 възела. Ако един от възлите се повреди, как може другият да знае, че неговият партньор се е сринал и това не е повреда в мрежата? В този случай другият възел може също да е готов и да работи, обслужвайки трафик. Няма добър начин за справяне с такъв случай... Ето защо толерантността към грешки обикновено започва от три възела. Galera използва изчисление на кворума, за да определи дали е безопасно клъстерът да се справя с трафика, или трябва да спре да работи. След неуспех всички останали възли се опитват да се свържат един с друг и да определят колко от тях са нагоре. След това се сравнява с предишното състояние на клъстера и докато повече от 50% от възлите са изправени, клъстерът може да продължи да работи.
Това води до следното:
клъстер от 2 възли - без толерантност на грешки
клъстер от 3 възли - до 1 срив
клъстер от 4 възли - до 1 срив (ако два възела се сринат, само 50% от клъстера ще бъде наличен, имате нужда от повече от 50% възли, за да оцелеете)
клъстер с 5 възли - до 2 срива
клъстер с 6 възли - до 2 срива
Вероятно виждате модела - искате вашият клъстер да има нечетен брой възли - по отношение на високата наличност няма смисъл да се движите от 5 на 6 възли в клъстера. Ако искате по-добра отказоустойчивост, трябва да изберете 7 възела.
Сегменти
Обикновено в клъстер на Galera цялата комуникация следва модела „всичко към всички“. Всеки възел говори с всички останали възли в клъстера.
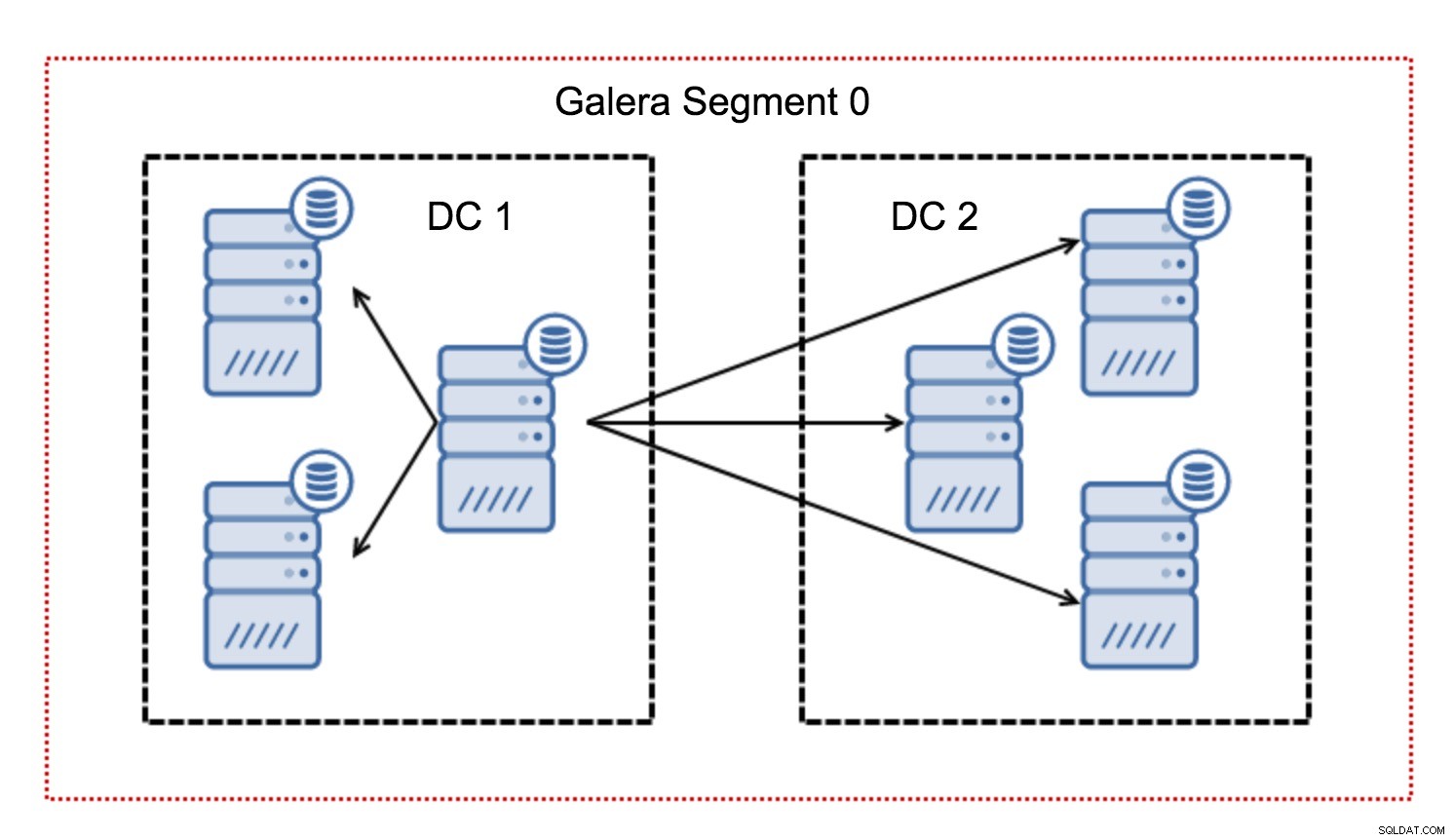
Както може би знаете, всеки набор за запис в Galera трябва да бъде сертифициран от всички възли в клъстера - следователно всяко записване, което се е случило на възел, трябва да бъде прехвърлено към всички възли в клъстера. Това работи добре в среда с ниска латентност. Но ако говорим за мулти-DC настройки, трябва да вземем предвид много по-висока латентност, отколкото в локална мрежа. За да го направи по-поносимо в клъстери, обхващащи широкообхватни мрежи, Galera въведе сегменти.
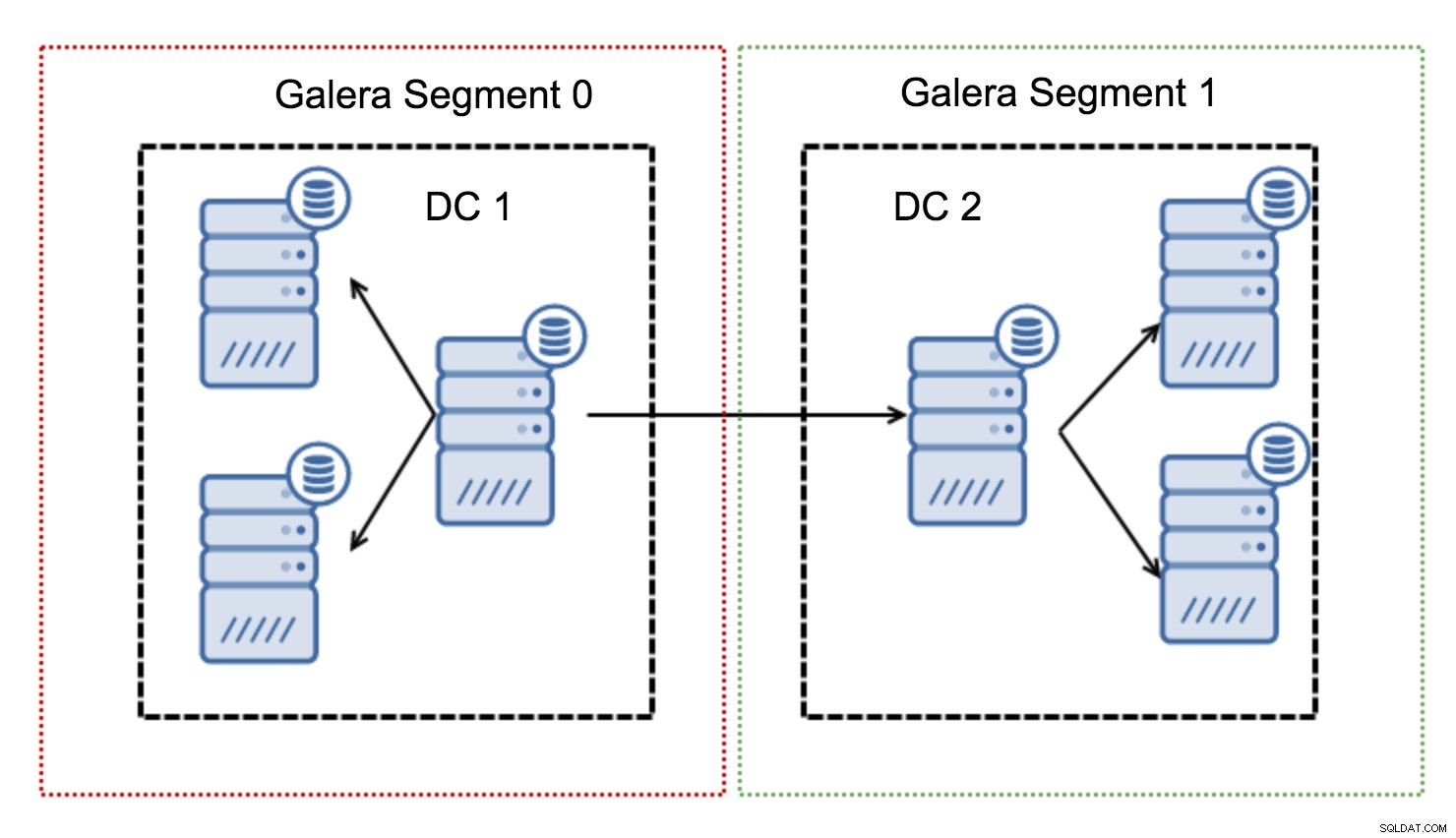
Те работят, като съдържат трафика на Galera в група от възли (сегмент). Всички възли в рамките на един сегмент действат така, сякаш са в локална мрежа - те приемат една към цялата комуникация. За трафика от кръстосани сегменти нещата са различни - във всеки от сегментите се избира един „релейен“ възел, целият трафик от кръстосани сегменти преминава през тези възли. Когато възелът на релето изпадне, се избира друг възел. Това не намалява латентността много – в края на краищата латентността на WAN ще остане същата, независимо дали правите връзка с един отдалечен хост или с множество отдалечени хостове, но като се има предвид, че WAN връзките обикновено са ограничени в честотната лента и може да има такса за количеството прехвърлени данни, такъв подход ви позволява да ограничите количеството данни, обменяни между сегментите. Друга възможност за спестяване на време и разходи е фактът, че възлите в същия сегмент са приоритетни, когато е необходим донор - отново това ограничава количеството данни, прехвърлени през WAN и най-вероятно ускорява SST като локална мрежа почти винаги ще бъде по-бърз от WAN връзка.
Сега, след като извадихме някои от тези концепции, нека разгледаме някои други важни аспекти на настройките с множество DC за клъстера Galera.
Проблеми, с които предстои да се сблъскате
Когато работите в среди, обхващащи WAN, има няколко въпроса, които трябва да вземете предвид при проектирането на вашата среда.
Изчисляване на кворума
В предишния раздел описахме как изглежда изчислението на кворума в клъстер Galera – накратко, искате да имате нечетен брой възли, за да увеличите максимално оцеляването. Всичко това все още е вярно в настройките с множество DC, но към микса се добавят още някои елементи. На първо място, трябва да решите дали искате Galera автоматично да се справя с повреда в центъра за данни. Това ще определи колко центрове за данни ще използвате. Нека си представим два DC - ако ще разделите възлите си 50% - 50%, ако един център за данни се повреди, вторият няма 50%+1 възли, за да поддържа своето "основно" състояние. Ако разделите възлите си по неравномерен начин, като използвате по-голямата част от тях в „главния“ център за данни, когато този център за данни изпадне, „резервният“ DC няма да има 50% + 1 възли, за да образува кворум. Можете да присвоите различни тегла на възлите, но резултатът ще бъде абсолютно същият - няма начин за автоматично превключване между два DC без ръчна намеса. За да приложите автоматично преминаване при отказ, имате нужда от повече от два DC. Отново, в идеалния случай нечетно число - три центъра за данни е идеална настройка. След това въпросът е - колко възли трябва да имате? Искате да ги имате равномерно разпределени в центровете за данни. Останалото е само въпрос на колко неуспешни възли трябва да се справи с вашата настройка.
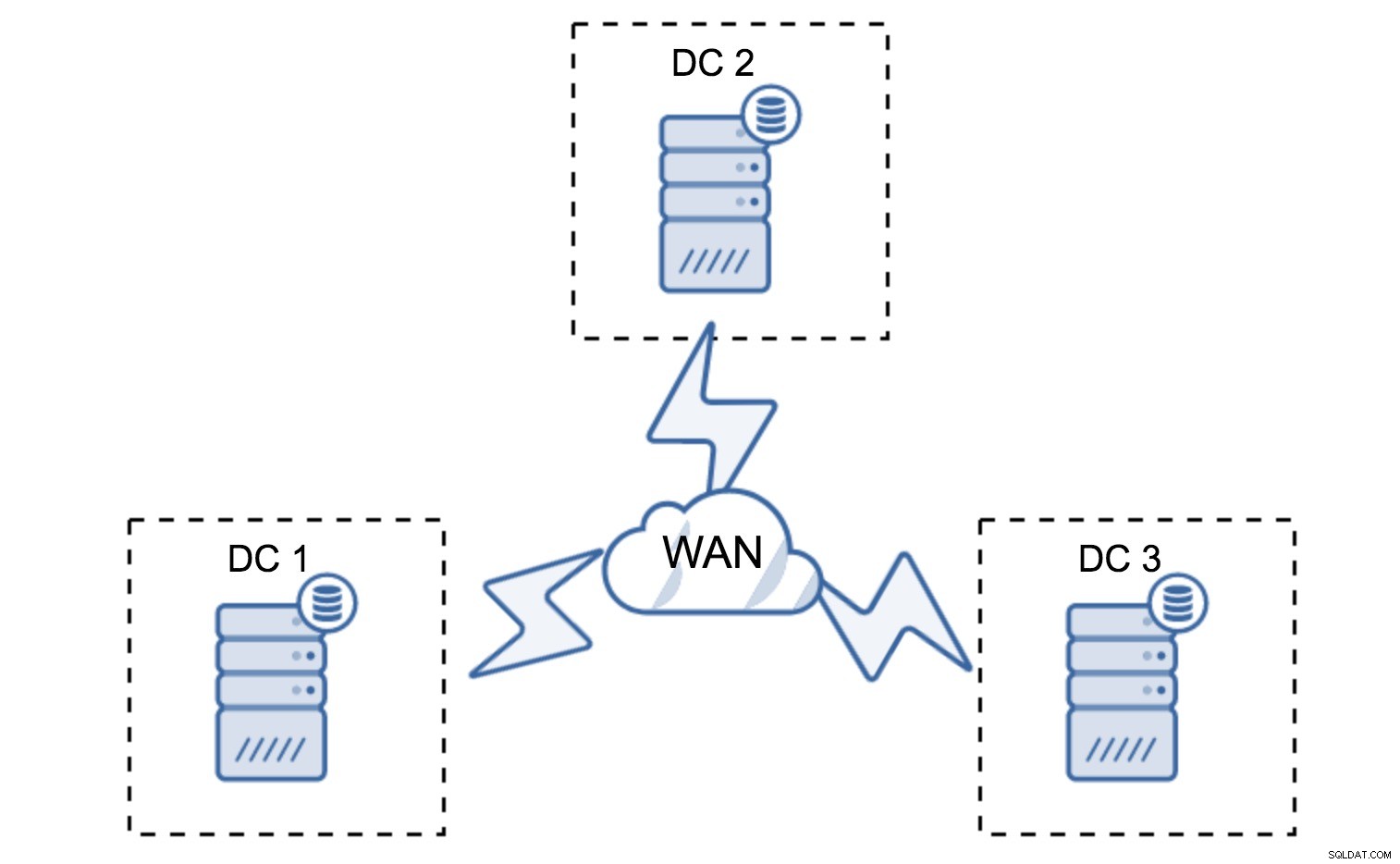
Минимална настройка ще използва един възел на център за данни - въпреки това има сериозни недостатъци. Всяко прехвърляне на състояние ще изисква преместване на данни през WAN и това води до по-дълго време, необходимо за завършване на SST, или по-високи разходи.
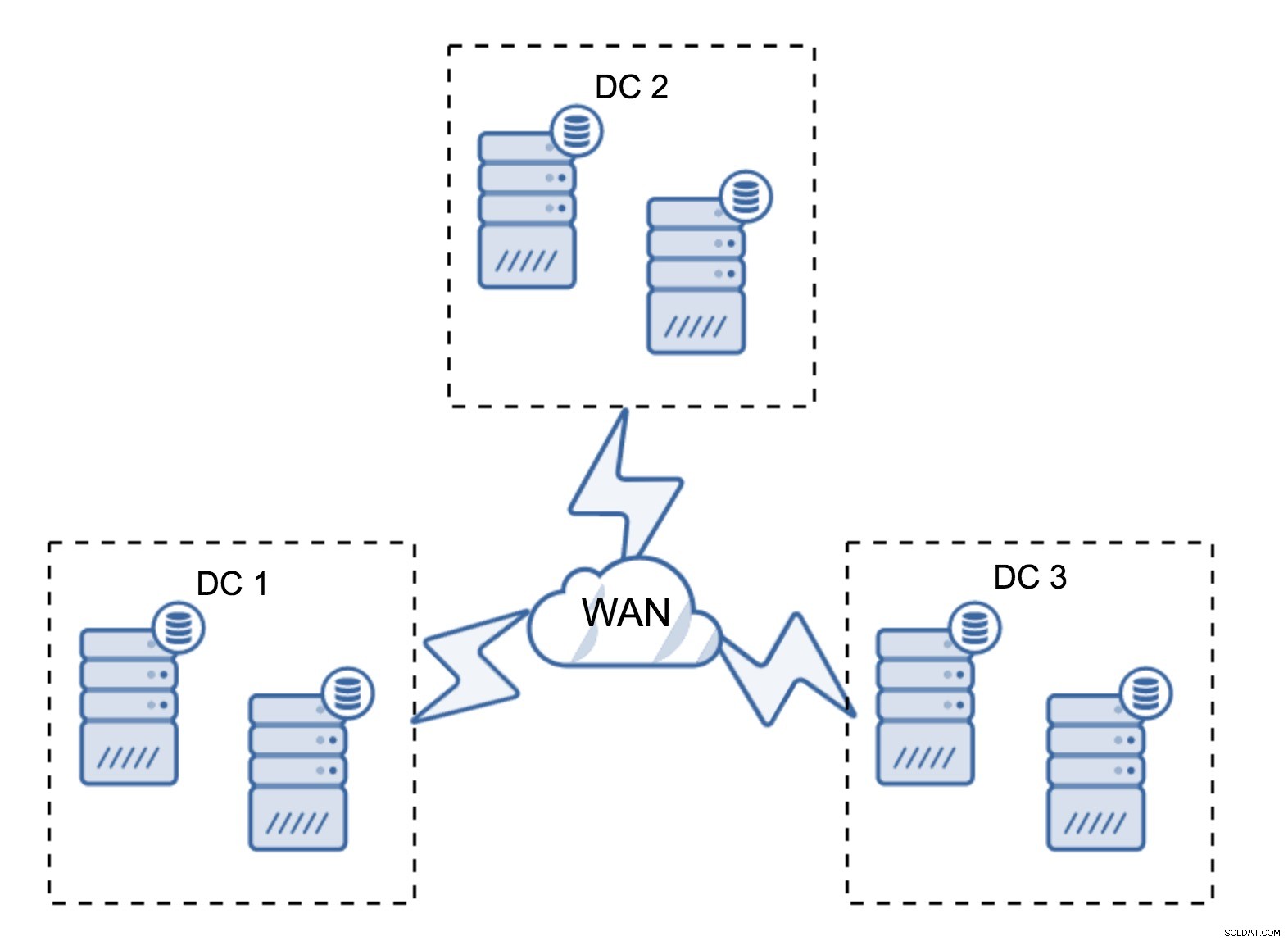
Доста типична настройка е да има шест възела, по два на център за данни. Тази настройка изглежда неочаквана, тъй като има четен брой възли. Но, като се замислите, може да не е толкова голям проблем:малко вероятно е три възела да се свалят наведнъж и такава настройка ще оцелее при срив на до два възела. Цял център за данни може да излезе офлайн и два оставащи DC ще продължат да работят. Той също така има огромно предимство пред минималната настройка - когато даден възел излезе офлайн, винаги има втори възел в центъра за данни, който може да служи като донор. През повечето време WAN няма да се използва за SST.
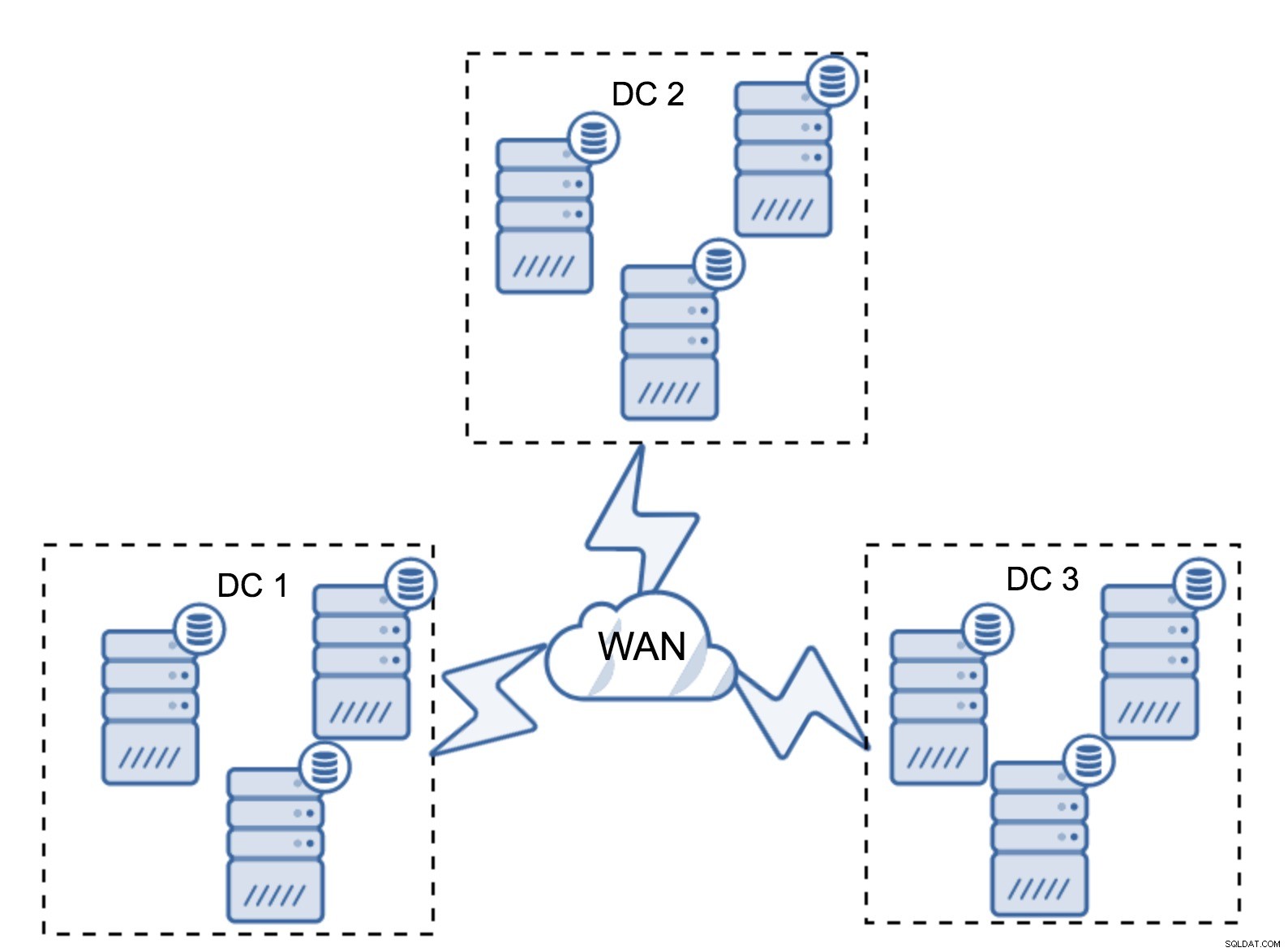
Разбира се, можете да увеличите броя на възлите до три на клъстер, общо девет. Това ви дава още по-добра преживяемост:до четири възела могат да се сринат и клъстерът все още ще оцелее. От друга страна, трябва да имате предвид, че дори и с използването на сегменти, повече възли означават по-високи разходи за операции и можете да мащабирате клъстера Galera само до известна степен.
Може да се случи, че няма нужда от трети център за данни, защото, да кажем, вашето приложение се намира само в два от тях. Разбира се, изискването за три центъра за данни все още е валидно, така че няма да го заобикаляте, но е напълно добре да използвате Galera Arbitrator (garbd) вместо напълно заредени сървъри на база данни.
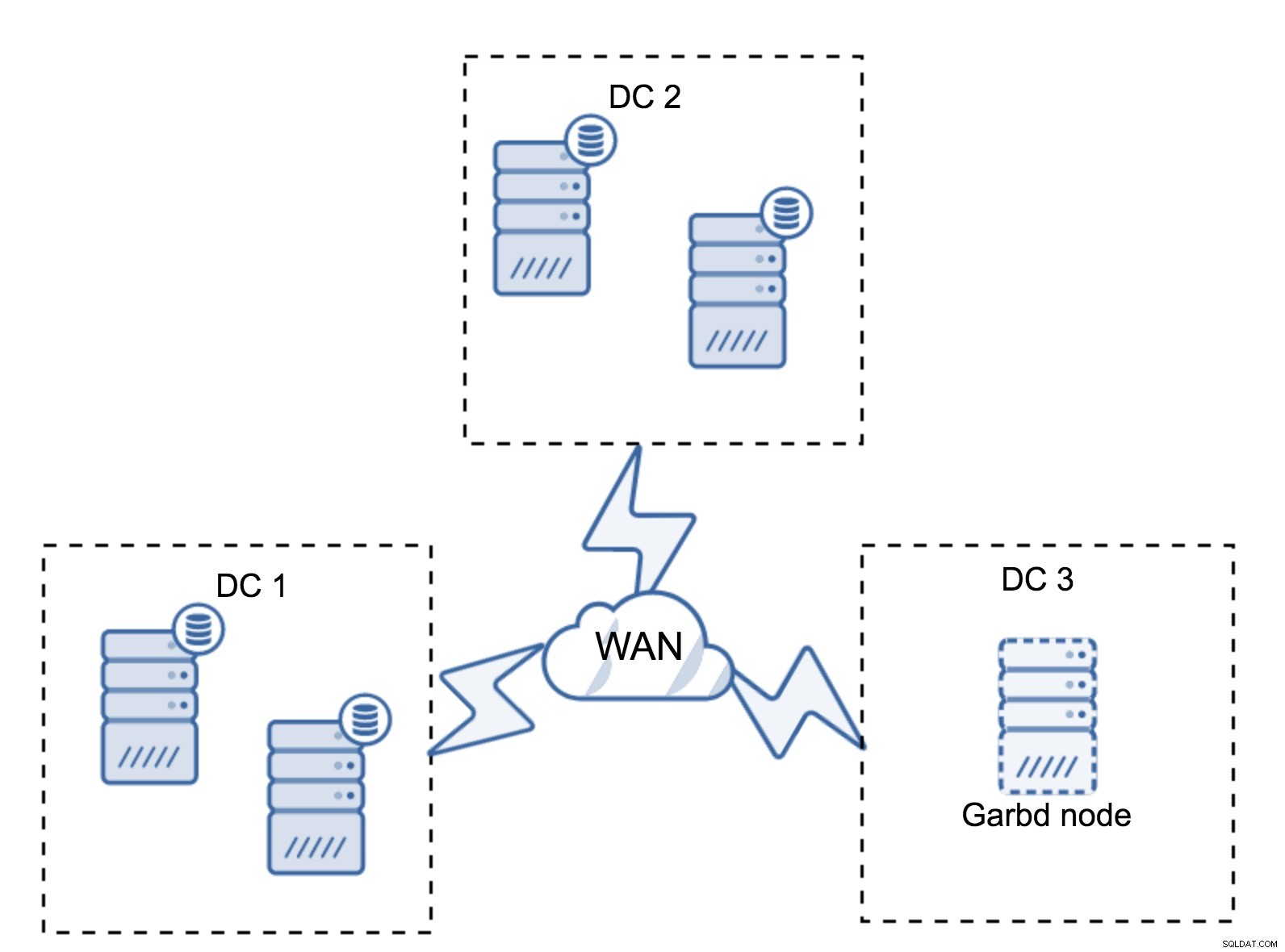
Garbd може да бъде инсталиран на по-малки възли, дори на виртуални сървъри. Не изисква мощен хардуер, не съхранява никакви данни, нито прилага нито един от наборите за запис. Но той вижда целия трафик на репликация и участва в изчисляването на кворума. Благодарение на него можете да разгръщате настройки като четири възела, два на DC + garbd в третия - имате общо пет възела и такъв клъстер може да приеме до два отказа. Това означава, че може да приеме пълно изключване на един от центровете за данни.
Кой вариант е по-добър за вас? Няма най-доброто решение за всички случаи, всичко зависи от вашите инфраструктурни изисквания. За щастие има различни опции, от които да избирате:повече или по-малко възли, пълни 3 DC или 2 DC и garbd в третия – много вероятно е да намерите нещо подходящо за вас.
Закъснение на мрежата
Когато работите с настройки с множество DC, трябва да имате предвид, че мрежовата латентност ще бъде значително по-висока от това, което бихте очаквали от локална мрежова среда. Това може сериозно да намали производителността на клъстера Galera, когато го сравните със самостоятелен екземпляр на MySQL или настройка на MySQL репликация. Изискването всички възли да трябва да сертифицират набор за запис означава, че всички възли трябва да го получат, независимо колко далеч са. С асинхронната репликация няма нужда да чакате преди комит. Разбира се, репликацията има други проблеми и недостатъци, но латентността не е основната. Проблемът е особено видим, когато вашата база данни има горещи точки - редове, които често се актуализират (броячи, опашки и т.н.). Тези редове не могат да се актуализират по-често от веднъж на мрежово двупосочно пътуване. За клъстери, обхващащи целия свят, това лесно може да означава, че няма да можете да актуализирате един ред по-често от 2 - 3 пъти в секунда. Ако това се превърне в ограничение за вас, това може да означава, че клъстерът Galera не е подходящ за конкретното ви работно натоварване.
Прокси слой в Multi-DC Galera Cluster
Не е достатъчно да имате клъстер на Galera, обхващащ множество центрове за данни, все още се нуждаете от вашето приложение за достъп до тях. Един от популярните методи за скриване на сложността на слоя на базата данни от приложение е да се използва прокси. Прокси сървърите се използват като входна точка към базите данни, те проследяват състоянието на възлите на базата данни и винаги трябва да насочват трафика само към наличните възли. В този раздел ще се опитаме да предложим дизайн на прокси слой, който може да се използва за мулти-DC клъстер Galera. Ще използваме ProxySQL, който ви дава доста гъвкавост при работа с възли на базата данни, но можете да използвате друг прокси, стига да може да проследява състоянието на възлите на Galera.
Къде да намеря прокситата?
Накратко, тук има два общи модела:можете или да разположите ProxySQL на отделни възли, или можете да ги разположите на хостовете на приложението. Нека да разгледаме плюсовете и минусите на всяка от тези настройки.
Прокси слой като отделен набор от хостове
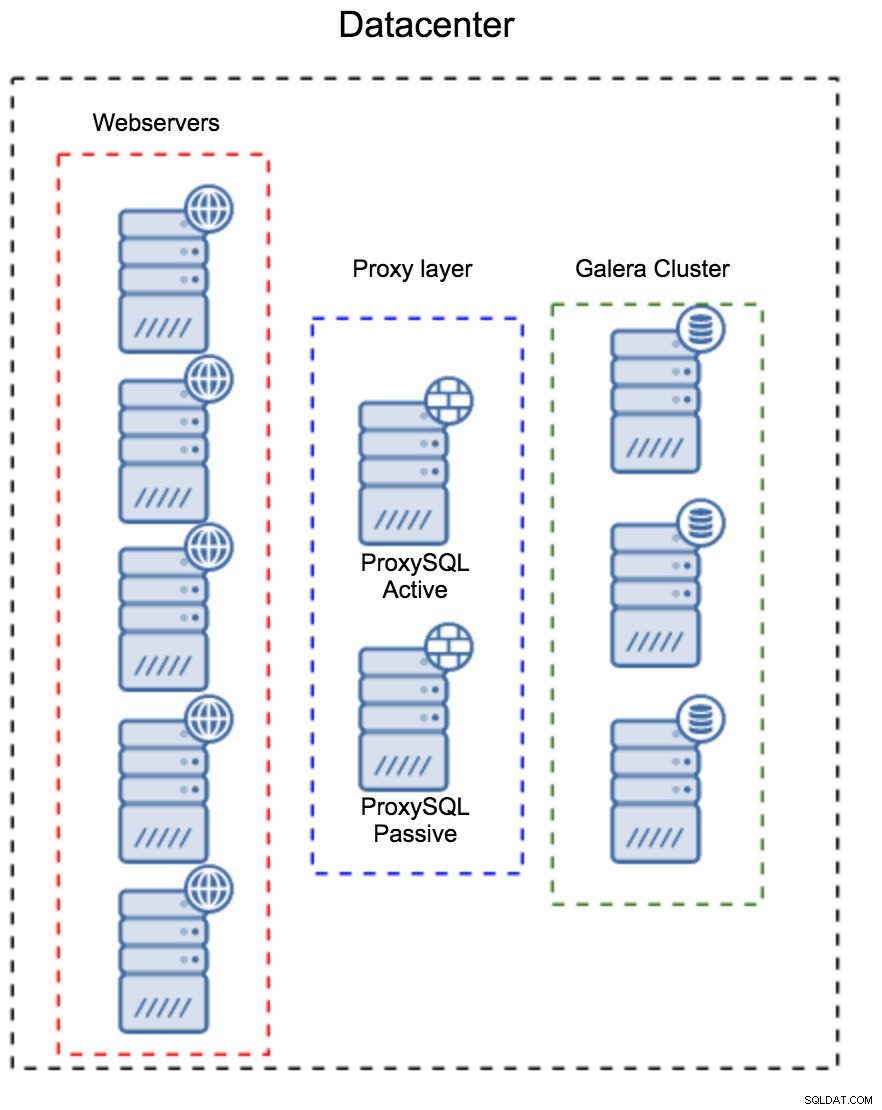
Първият модел е да се изгради прокси слой с помощта на отделни, специализирани хостове. Можете да разположите ProxySQL на няколко хоста и да използвате виртуален IP и поддържане на активност, за да поддържате висока наличност. Едно приложение ще използва VIP за свързване с базата данни и VIP ще гарантира, че заявките винаги ще бъдат насочени към наличен ProxySQL. Основният проблем с тази настройка е, че използвате най-много един от екземплярите на ProxySQL - всички резервни възли не се използват за маршрутизиране на трафика. Това може да ви принуди да използвате по-мощен хардуер, отколкото обикновено използвате. От друга страна е по-лесно да поддържате настройката - ще трябва да приложите промени в конфигурацията на всички възли на ProxySQL, но ще има само шепа от тях. Можете също да използвате опцията на ClusterControl за синхронизиране на възлите. Такава настройка ще трябва да се дублира във всеки център за данни, който използвате.
Прокси, инсталиран на екземпляри на приложение
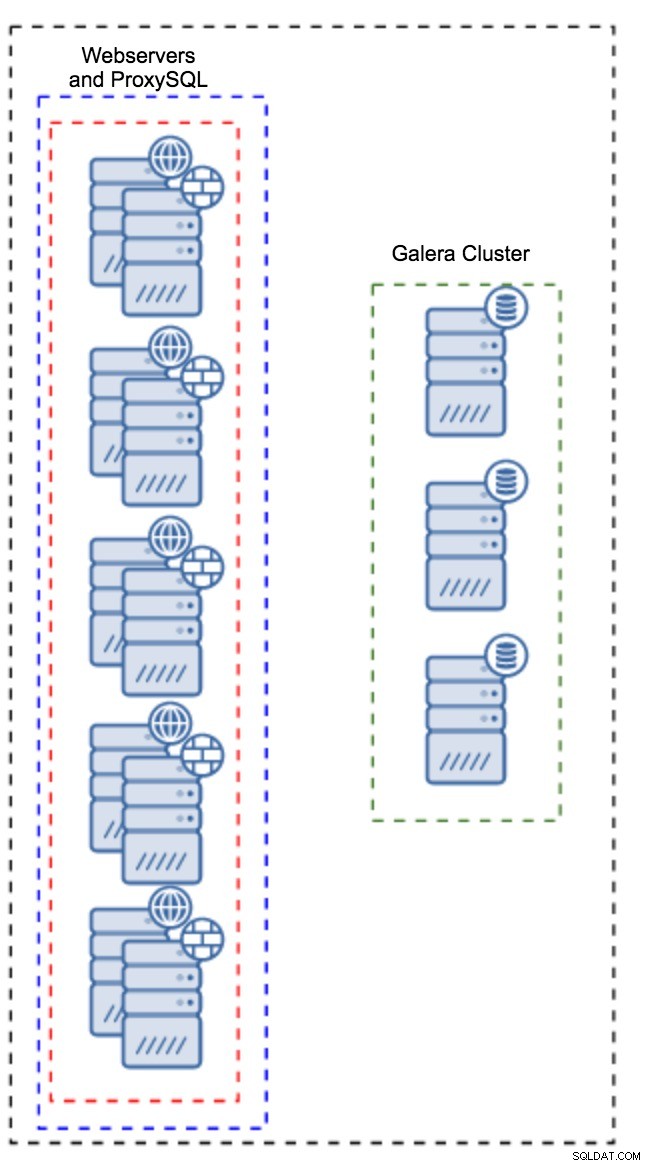
Вместо да има отделен набор от хостове, ProxySQL може също да бъде инсталиран на хостовете на приложението. Приложението ще се свърже директно с ProxySQL на localhost, то дори може да използва unix сокет, за да сведе до минимум излишните разходи за TCP връзката. Основното предимство на такава настройка е, че имате голям брой копия на ProxySQL и натоварването е равномерно разпределено между тях. Ако един от тях се повреди, ще бъде засегнат само този хост на приложението. Останалите възли ще продължат да работят. Най-сериозният проблем е управлението на конфигурацията. С голям брой възли на ProxySQL е от решаващо значение да се измисли автоматизиран метод за синхронизиране на техните конфигурации. Можете да използвате ClusterControl или инструмент за управление на конфигурацията като Puppet.
Настройка на Galera в WAN среда
Настройките по подразбиране на Galera са предназначени за локална мрежа и ако искате да я използвате в WAN среда, е необходима известна настройка. Нека обсъдим някои от основните настройки, които можете да направите. Моля, имайте предвид, че точната настройка изисква производствени данни и трафик – не можете просто да направите някои промени и да приемете, че са добри, трябва да направите правилен сравнителен анализ.
Конфигурация на операционната система
Нека започнем с конфигурацията на операционната система. Не всички модификации, предложени тук, са свързани с WAN, но винаги е добре да си напомняме коя е добра отправна точка за всяка инсталация на MySQL.
vm.swappiness = 1Swappiness контролира колко агресивно ще използва суап операционната система. Не трябва да се настройва на нула, тъй като в по-новите ядра това не позволява на ОС изобщо да използва swap и може да причини сериозни проблеми с производителността.
/sys/block/*/queue/scheduler = deadline/noopПланировчикът за блоковото устройство, което MySQL използва, трябва да бъде настроен на краен срок или на noop. Точният избор зависи от бенчмарковете, но и двете настройки трябва да осигуряват подобна производителност, по-добра от планировчика по подразбиране, CFQ.
За MySQL трябва да обмислите използването на EXT4 или XFS, в зависимост от ядрото (производителността на тези файлови системи се променя от една версия на ядрото в друга). Извършете някои сравнителни показатели, за да намерите по-добрия вариант за вас.
В допълнение към това може да искате да разгледате мрежовите настройки на sysctl. Няма да ги обсъждаме подробно (можете да намерите документация тук), но общата идея е да се увеличат буферите, натрупванията и изчакванията, за да се улесни приспособяването на застой и нестабилна WAN връзка.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0В допълнение към настройката на операционната система, трябва да помислите за настройване на настройки, свързани с мрежата на Galera.
evs.suspect_timeout
evs.inactive_timeoutМоже да помислите за промяна на стойностите по подразбиране на тези променливи. И двете изчаквания управляват как клъстерът изхвърля неуспешни възли. Подозрително изчакване настъпва, когато всички възли не могат да достигнат до неактивния член. Неактивното изчакване определя твърд лимит за това колко дълго възел може да остане в клъстера, ако не отговаря. Обикновено ще откриете, че стойностите по подразбиране работят добре. Но в някои случаи, особено ако стартирате своя клъстер Galera през WAN (например между региони на AWS), увеличаването на тези променливи може да доведе до по-стабилна производителност. Бихме предложили да настроите и двете на PT1M, за да се намали вероятността нестабилността на WAN връзката да изхвърли възел извън клъстера.
evs.send_window
evs.user_send_windowТези променливи, evs.send_window и evs.user_send_window , дефинирайте колко пакета могат да бъдат изпратени чрез репликация едновременно (evs.send_window ) и колко от тях може да съдържат данни (evs.user_send_window ). За връзки с висока латентност може да си струва да увеличите значително тези стойности (например 512 или 1024).
evs.inactive_check_periodГорната променлива също може да бъде променена. evs.inactive_check_period , по подразбиране, е настроена на една секунда, което може да е твърде често за настройка на WAN. Препоръчваме ви да го настроите на PT30S.
gcs.fc_factor
gcs.fc_limitТук искаме да сведем до минимум шансовете, че контролът на потока ще започне, затова предлагаме да зададете gcs.fc_factor до 1 и увеличете gcs.fc_limit до, например, 260.
gcs.max_packet_sizeТъй като работим с WAN връзката, където латентността е значително по-висока, искаме да увеличим размера на пакетите. Добра отправна точка би била 2097152.
Както споменахме по-рано, практически е невъзможно да се даде проста рецепта за това как да зададете тези параметри, тъй като това зависи от твърде много фактори - ще трябва да направите свои собствени показатели, като използвате данни възможно най-близо до вашите производствени данни, преди да може да каже, че системата ви е настроена. Като се има предвид това, тези настройки трябва да ви дадат отправна точка за по-прецизна настройка.
Това е засега. Galera работи доста добре в WAN среди, така че опитайте и ни уведомете как се справяте.