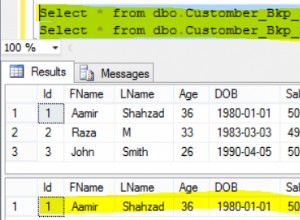
Вярвам, че това ще го направи, използвайки дублиран ключ + ifnull():
create table tmp like yourtable;
alter table tmp add unique (text1, text2);
insert into tmp select * from yourtable
on duplicate key update text3=ifnull(text3, values(text3));
rename table yourtable to deleteme, tmp to yourtable;
drop table deleteme;
Трябва да е много по-бързо от всичко, което изисква групиране по или отделно, или подзаявка, или дори подреждане по. Това дори не изисква сортиране на файлове, което ще убие производителността на голяма временна таблица. Все пак ще е необходимо пълно сканиране на оригиналната таблица, но това не може да се избегне.