Въпреки че в бъдеще повечето сървъри на бази данни (особено тези, които обработват натоварвания, подобни на OLTP) ще използват флаш-базирано хранилище, ние все още не сме там – флаш паметта все още е значително по-скъпа от традиционните твърди дискове и толкова много системи използват микс на SSD и HDD дискове. Това обаче означава, че трябва да решим как да разделим базата данни – какво трябва да отиде при въртящата се ръжда (HDD) и кой е добър кандидат за флаш памет, която е по-скъпа, но много по-добра при работа с произволен I/O.
Има решения, които се опитват да се справят автоматично с това на ниво съхранение, като автоматично използват SSD като кеш, като автоматично запазват активната част от данните на SSD. Устройствата за съхранение / SAN често правят това вътрешно, има хибридни SATA/SAS устройства с голям твърд диск и малък SSD в един пакет и разбира се има решения за това директно на хоста – например има dm-кеш в Linux, LVM също получи такава възможност (изградена върху dm-cache) през 2014 г. и разбира се ZFS има L2ARC.
Но нека игнорираме всички тези автоматични опции и да кажем, че имаме две устройства, свързани директно към системата – едното е базирано на твърди дискове, а другото е базирано на флаш. Как трябва да разделите базата данни, за да извлечете максимална полза от скъпата светкавица? Един често използван модел е да се направи това чрез тип обект, особено таблици срещу индекси. Което като цяло има смисъл, но често виждаме хора да поставят индекси в SSD хранилището, тъй като индексите са свързани с произволен I/O. Въпреки че това може да изглежда разумно, се оказва, че това е точно обратното на това, което трябва да правите.
Нека ви покажа еталон...
Позволете ми да демонстрирам това на система както с HDD съхранение (RAID10, изграден от 4x 10k SAS устройства), така и с едно SSD устройство (Intel S3700). Системата има 16GB RAM, така че нека използваме pgbench със скали 300 (=4.5GB) и 3000 (=45GB), т.е. такъв, който лесно се вписва в RAM и кратно на RAM. След това нека поставим таблици и индекси на различни системи за съхранение (чрез използване на пространства за таблици) и да измерим производителността. Клъстерът на базата данни беше разумно конфигуриран (споделени буфери, WAL ограничения и т.н.) по отношение на хардуерните ресурси. WAL беше поставен на отделно SSD устройство, прикрепено към RAID контролер, споделен със SAS устройствата.
При малкия (4,5 GB) набор от данни резултатите изглеждат така (забележете, че оста y започва от 3000 tps):
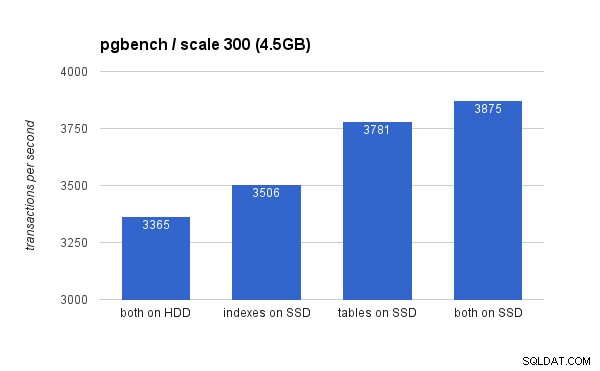
Ясно е, че поставянето на индексите на SSD дава по-ниска полза в сравнение с използването на SSD за таблици. Докато наборът от данни лесно се вписва в RAM, промените в крайна сметка трябва да бъдат записани на диска в крайна сметка и докато RAID контролерът има кеш за запис, той наистина не може да се конкурира с флаш паметта. Новите RAID контролери вероятно биха се представили малко по-добре, но също и новите SSD устройства.
При големия набор от данни разликите са много по-значителни (този път оста y започва от 0):
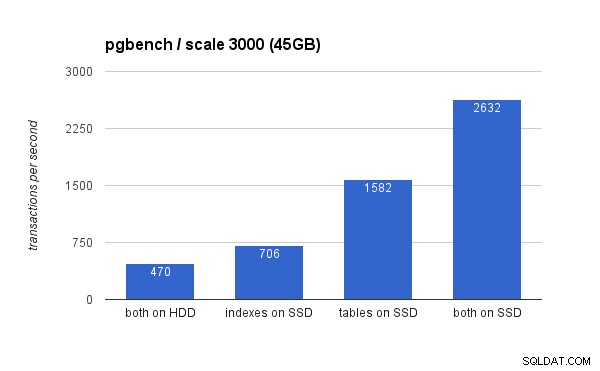
Поставянето на индексите на SSD води до значително увеличение на производителността (почти 50%, като се вземе HDD съхранение като базова линия), но преместването на таблици към SSD лесно надминава това, като печели повече от 200%. Разбира се, ако поставите и таблици, и индекс на SSD, ще подобрите още повече производителността – но ако можете да направите това, не е нужно да се притеснявате за другите случаи.
Но защо?
Получаването на по-добра производителност от поставянето на таблици на SSD може да изглежда малко противоинтуитивно, така че защо се държи така? Е, вероятно това е комбинация от няколко фактора:
- индексите обикновено са много по-малки от таблиците и по този начин се вписват по-лесно в паметта
- страниците в нивата на индекси (в дървото) обикновено са доста горещи и по този начин остават в паметта
- при сканиране и индексиране голяма част от действителните I/O са последователни по природа (особено за листни страници)
Последствието от това е, че изненадващо количество I/O срещу индекси или не се случва изобщо (благодарение на кеширането), или е последователно. От друга страна, индексите са чудесен източник на произволен I/O спрямо таблиците.
По-сложно е обаче...
Разбира се, това беше само прост пример и заключенията може да са различни за значително различни натоварвания, например. По същия начин, тъй като SSD дисковете са по-скъпи, системите обикновено имат повече дисково пространство на HDD устройства, отколкото на SSD устройства, така че таблиците може да не се поберат на SSD, докато индексите биха. В тези случаи е необходимо по-задълбочено разположение – например като се има предвид не само типа на обекта, но и колко често се използва (и само преместване на силно използваните таблици към SSD), или дори подмножества от таблици (например чрез постепенно преместване на стари данни от SSD към HDD).