Това е доста често срещан проблем.
Обикновено B-Tree индексите не са добри за заявки като тази:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
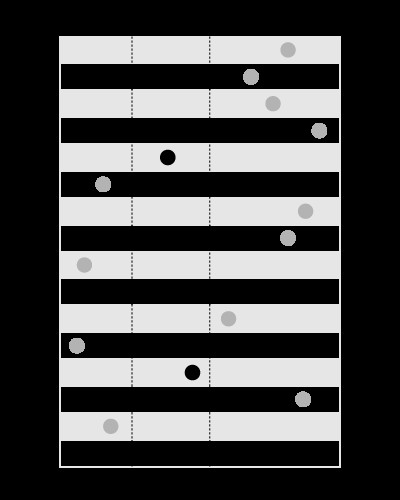
Индексът е добър за търсене на стойностите в дадените граници, като това:
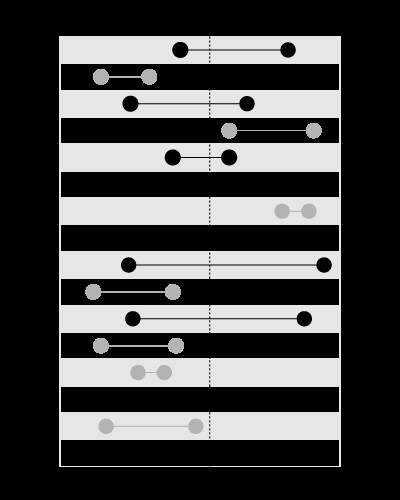
, но не и за търсене в границите, съдържащи дадената стойност, като това:
Тази статия в моя блог обяснява проблема по-подробно:
(моделът на вложените множества работи с подобен тип предикат).
Можете да направите индекса на time , по този начин intervals ще бъде водещ в съединяването, диапазонираното време ще се използва вътре във вложените цикли. Това ще изисква сортиране по time .
Можете да създадете пространствен индекс на intervals (наличен в MySQL използвайки MyISAM съхранение), което ще включва start и end в една геометрична колона. По този начин measures може да води в съединяването и няма да е необходимо сортиране.
Пространствените индекси обаче са по-бавни, така че това ще бъде ефективно само ако имате малко мерки, но много интервали.
Тъй като имате малко интервали, но много мерки, просто се уверете, че имате индекс на measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Актуализация:
Ето примерен скрипт за тестване:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Тази заявка:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
използва NESTED LOOPS и се връща в 1.7 секунди.
Тази заявка:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
използва MERGE JOIN и трябваше да го спра след 5 минути.
Актуализация 2:
Най-вероятно ще трябва да принудите двигателя да използва правилния ред на таблиците в съединението, като използвате подсказка като тази:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle Оптимизаторът на не е достатъчно умен, за да види, че интервалите не се пресичат. Ето защо най-вероятно ще използва measures като водеща таблица (което би било мъдро решение, ако интервалите се пресичат).
Актуализация 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Тази заявка разделя времевата ос на диапазони и използва HASH JOIN за присъединяване на мерките и времевите клейма към стойностите на диапазона, с фино филтриране по-късно.
Вижте тази статия в моя блог за по-подробни обяснения как работи: