„Опитвам се да намеря надежден метод за съпоставяне на дублирани лични записи в базата данни.“
Уви няма такова нещо. Най-много, на което можете да се надявате, е система с разумен елемент на съмнение.
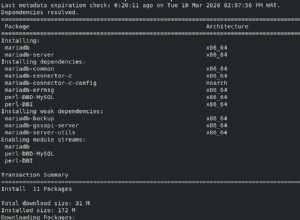
SQL> select n1
, n2
, soundex(n1) as sdx_n1
, soundex(n2) as sdx_n2
, utl_match.edit_distance_similarity(n1, n2) as ed
, utl_match.jaro_winkler_similarity(n1, n2) as jw
from t94
order by n1, n2
/
2 3 4 5 6 7 8 9
N1 N2 SDX_ SDX_ ED JW
-------------------- -------------------- ---- ---- ---------- ----------
MARK MARKIE M620 M620 67 93
MARK MARKS M620 M620 80 96
MARK MARKUS M620 M622 67 93
MARKY MARKIE M620 M620 67 89
MARSK MARKS M620 M620 60 95
MARX AMRX M620 A562 50 91
MARX M4RX M620 M620 75 85
MARX MARKS M620 M620 60 84
MARX MARSK M620 M620 60 84
MARX MAX M620 M200 75 93
MARX MRX M620 M620 75 92
11 rows selected.
SQL> SQL> SQL>
Голямото предимство на SOUNDEX е, че токенизира низа. Това означава, че ви дава нещо, което може да бъде индексирано :това е невероятно ценно, когато става въпрос за големи количества данни. От друга страна е стара и груба. Наоколо има по-нови алгоритми, като метафон и двоен метафон. Трябва да можете да намерите PL/SQL имплементации чрез Google.
Предимството на точкуването е, че те позволяват известна степен на размита; така че можете да намерите всички редове where name_score >= 90% . Смазващият недостатък е, че резултатите са относителни и затова не можете да ги индексирате. Този вид сравнение ви убива с големи обеми.
Това означава:
- Имате нужда от комбинация от стратегии. Никой един алгоритъм няма да реши проблема ви.
- Почистването на данни е полезно. Сравнете резултатите за MARX спрямо MRX и M4RX:премахването на числа от имена подобрява процента на попадане.
- Не можете да спечелите големи обеми от имена в движение. Използвайте токенизиране и предварително оценяване, ако можете. Използвайте кеширане, ако нямате много churn. Използвайте разделяне, ако можете да си го позволите.
- Използвайте Oracle Text (или подобен), за да създадете речник от прякори и варианти.
- Oracle 11g въведе специфична функционалност за търсене на имена в Oracle Text. Научете повече.
- Създайте таблица с канонични имена за оценяване и свържете действителните записи с данни с това.
- Използвайте други стойности на данни, особено индексируеми, като дата на раждане, за предварително филтриране на големи обеми от имена или за повишаване на увереността в предложените съвпадения.
- Имайте предвид, че други стойности на данни идват със свои собствени проблеми:някой роден на 31/01/11 е на единадесет месеца или на осемдесет години?
- Не забравяйте, че имената са трудни, особено когато трябва да имате предвид имена, които са били романизирани:има над четиристотин различни начина за изписване на Моамар Кадафи (в латинската азбука) – и дори Google не може да се съгласи кой вариант е най-канонични.
Според моя опит свързването на токените (собствено име, фамилия) е смесена благословия. Той решава определени проблеми (като например дали името на пътя се появява в адресен ред 1 или адресен ред 2), но причинява други проблеми:помислете за оценка на GRAHAM OLIVER срещу OLIVER GRAHAM срещу оценка OLIVER срещу OLIVER, GRAHAM срещу GRAHAM, OLIVER срещу GRAHAM и GRAHAM срещу OLIVER .
Каквото и да правите, все пак ще завършите с фалшиви положителни резултати и пропуснати попадения. Никой алгоритъм не е доказателство срещу печатни грешки (въпреки че Jaro Winkler се справи доста добре с MARX срещу AMRX).