Има две причини row y не се връща се дължи на условието:
b.start > a.startозначава, че ред никога няма да се съедини със себе си- GROUP BY ще върне само един запис на
APP_nmстойност, но всички редове имат една и съща стойност.
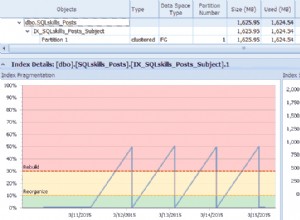
Има обаче допълнителни логически грешки в заявката, които няма да бъдат обработени успешно. Например, как знае кога започва "нова" сесия?
Логиката, която търсите, може да бъде постигната в нормален PostgreSQL с помощта на DISTINCT ON функция, която показва един ред на входна стойност в конкретна колона. Въпреки това, DISTINCT ON не се поддържа от Redshift.
Някои потенциални решения:DISTINCT ON like функционалност за Redshift
Резултатът, който търсите, би бил тривиален при използване на език за програмиране (който може да преминава през резултатите и да съхранява променливи), но е труден за прилагане към SQL заявка (която е проектирана да работи с редове с резултати). Бих препоръчал да извлечете данните и да ги стартирате чрез прост скрипт (напр. в Python), който след това може да изведе началните и крайните комбинации, които търсите.
Това е отличен случай за използване на функция за поточно предаване на Hadoop , които успешно съм прилагал в миналото. Той ще приеме записите като вход, след това ще „запомни“ началния час и ще изведе запис само когато е изпълнена желаната крайна логика.