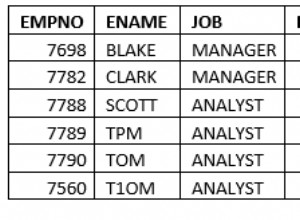
Нека създадем тестови данни на postgresl 13 с 600 набора от данни, 45k cфайла.
BEGIN;
CREATE TABLE cfiles (
id SERIAL PRIMARY KEY,
dataset_id INTEGER NOT NULL,
property_values jsonb NOT NULL);
INSERT INTO cfiles (dataset_id,property_values)
SELECT 1+(random()*600)::INTEGER AS did,
('{"Sample Names": ["'||array_to_string(array_agg(DISTINCT prop),'","')||'"]}')::jsonb prop
FROM (
SELECT 1+(random()*45000)::INTEGER AS cid,
'Samp'||(power(random(),2)*30)::INTEGER AS prop
FROM generate_series(1,45000*4)) foo
GROUP BY cid;
COMMIT;
CREATE TABLE datasets ( id INTEGER PRIMARY KEY, name TEXT NOT NULL );
INSERT INTO datasets SELECT n, 'dataset'||n FROM (SELECT DISTINCT dataset_id n FROM cfiles) foo;
CREATE INDEX cfiles_dataset ON cfiles(dataset_id);
VACUUM ANALYZE cfiles;
VACUUM ANALYZE datasets;
Вашата първоначална заявка е много по-бърза тук, но това вероятно е защото postgres 13 е просто по-интелигентен.
Sort (cost=114127.87..114129.37 rows=601 width=46) (actual time=658.943..659.012 rows=601 loops=1)
Sort Key: datasets.name
Sort Method: quicksort Memory: 334kB
-> GroupAggregate (cost=0.57..114100.13 rows=601 width=46) (actual time=13.954..655.916 rows=601 loops=1)
Group Key: datasets.id
-> Nested Loop (cost=0.57..92009.62 rows=4416600 width=46) (actual time=13.373..360.991 rows=163540 loops=1)
-> Merge Join (cost=0.56..3677.61 rows=44166 width=78) (actual time=13.350..113.567 rows=44166 loops=1)
Merge Cond: (cfiles.dataset_id = datasets.id)
-> Index Scan using cfiles_dataset on cfiles (cost=0.29..3078.75 rows=44166 width=68) (actual time=0.015..69.098 rows=44166 loops=1)
-> Index Scan using datasets_pkey on datasets (cost=0.28..45.29 rows=601 width=14) (actual time=0.024..0.580 rows=601 loops=1)
-> Function Scan on jsonb_array_elements_text sn (cost=0.01..1.00 rows=100 width=32) (actual time=0.003..0.004 rows=4 loops=44166)
Execution Time: 661.978 ms
Тази заявка първо чете голяма таблица (cfiles) и произвежда много по-малко редове поради агрегацията. Така ще бъде по-бързо да се присъедините с набори от данни, след като броят на редовете за присъединяване бъде намален, а не преди това. Нека преместим това присъединяване. Също така се отървах от CROSS JOIN, което е ненужно, когато има функция за връщане на набор в SELECT postgres ще направи това, което искате безплатно.
SELECT dataset_id, d.name, sample_names FROM (
SELECT dataset_id, string_agg(sn, '; ') as sample_names FROM (
SELECT DISTINCT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM cfiles
) f GROUP BY dataset_id
)g JOIN datasets d ON (d.id=g.dataset_id)
ORDER BY d.name;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=536207.44..536207.94 rows=200 width=46) (actual time=264.435..264.502 rows=601 loops=1)
Sort Key: d.name
Sort Method: quicksort Memory: 334kB
-> Hash Join (cost=536188.20..536199.79 rows=200 width=46) (actual time=261.404..261.784 rows=601 loops=1)
Hash Cond: (d.id = cfiles.dataset_id)
-> Seq Scan on datasets d (cost=0.00..10.01 rows=601 width=14) (actual time=0.025..0.124 rows=601 loops=1)
-> Hash (cost=536185.70..536185.70 rows=200 width=36) (actual time=261.361..261.363 rows=601 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 170kB
-> HashAggregate (cost=536181.20..536183.70 rows=200 width=36) (actual time=260.805..261.054 rows=601 loops=1)
Group Key: cfiles.dataset_id
Batches: 1 Memory Usage: 1081kB
-> HashAggregate (cost=409982.82..507586.70 rows=1906300 width=36) (actual time=244.419..253.094 rows=18547 loops=1)
Group Key: cfiles.dataset_id, jsonb_array_elements_text((cfiles.property_values -> 'Sample Names'::text))
Planned Partitions: 4 Batches: 1 Memory Usage: 13329kB
-> ProjectSet (cost=0.00..23530.32 rows=4416600 width=36) (actual time=0.030..159.741 rows=163540 loops=1)
-> Seq Scan on cfiles (cost=0.00..1005.66 rows=44166 width=68) (actual time=0.006..9.588 rows=44166 loops=1)
Planning Time: 0.247 ms
Execution Time: 269.362 ms
Това е по-добре. Но виждам ОГРАНИЧЕНИЕ в заявката ви, което означава, че вероятно правите нещо като страниране. В този случай е необходимо само да се изчисли цялата заявка за цялата таблица cfiles и след това да се изхвърлят повечето от резултатите поради LIMIT, АКО резултатите от тази голяма заявка могат да променят дали ред от набори от данни е включен в крайния резултат или не. Ако случаят е такъв, тогава редове в набори от данни, които нямат съответни cfiles, няма да се появят в крайния резултат, което означава, че съдържанието на cfiles ще повлияе на странирането. Е, винаги можем да излъжем:за да знаем дали трябва да бъде включен ред от набори от данни, всичко, което се изисква, е ЕДИН ред от cfiles да съществува с този идентификатор...
Така че, за да знаем кои редове от набори от данни ще бъдат включени в крайния резултат, можем да използваме една от тези две заявки:
SELECT id FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20;
SELECT dataset_id FROM
(SELECT id AS dataset_id, name AS dataset_name FROM datasets ORDER BY dataset_name) f1
WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = f1.dataset_id )
ORDER BY dataset_name
LIMIT 20;
Те отнемат около 2-3 милисекунди. Можем също да мамим:
CREATE INDEX datasets_name_id ON datasets(name,id);
Това го намалява до около 300 микросекунди. И така, сега имаме списък с dataset_id, който действително ще бъде използван (а не изхвърлен), така че можем да го използваме, за да извършим голямото бавно агрегиране само на редовете, които действително ще бъдат в крайния резултат, което би трябвало да спести голяма сума на ненужна работа...
WITH ds AS (SELECT id AS dataset_id, name AS dataset_name
FROM datasets WHERE EXISTS( SELECT * FROM cfiles WHERE cfiles.dataset_id = datasets.id )
ORDER BY name LIMIT 20)
SELECT dataset_id, dataset_name, sample_names FROM (
SELECT dataset_id, string_agg(DISTINCT sn, '; ' ORDER BY sn) as sample_names FROM (
SELECT dataset_id,
jsonb_array_elements_text(cfiles.property_values -> 'Sample Names') AS sn
FROM ds JOIN cfiles USING (dataset_id)
) g GROUP BY dataset_id
) h JOIN ds USING (dataset_id)
ORDER BY dataset_name;
Това отнема около 30 ms, също така поставих реда по sample_name, който бях забравил преди. Трябва да работи за вашия случай. Важен момент е, че времето за заявка вече не зависи от размера на cfiles на таблицата, тъй като то ще обработва само редовете, които действително са необходими.
Моля, публикувайте резултати;)