Не знам за функция, която да прави това веднага в PostgreSQL.
A рекурсивен CTE
ще бъде ключовият елемент за доста елегантно решение (достъпно в PostgreSQL 8.4 или по-нова).
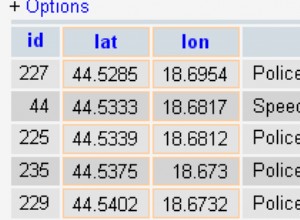
Предполагам filter на таблица за задържане на филтърните низове:
CREATE TABLE filter (f_id int, string text);
И таблица tbl за търсене на най-дългото съвпадение:
CREATE TABLE tbl(t_id int, col text);
Запитване
WITH RECURSIVE
f AS (SELECT f_id, string, length(string) AS flen FROM filter)
,t AS (SELECT t_id, col, length(col) AS tlen FROM tbl)
,x AS (
SELECT t.t_id, f.f_id, t.col, f.string
,2 AS match, LEAST(flen, tlen) AS len
FROM t
JOIN f ON left(t.col, 1) = left(f.string, 1)
UNION ALL
SELECT t_id, f_id, col, string, match + 1, len
FROM x
WHERE left(col, match) = left(string, match)
AND match <= len
)
SELECT DISTINCT
f_id
,string
,first_value(col) OVER w AS col
,first_value(t_id) OVER w AS t_id
,(first_value(match) OVER w -1) AS longest_match
FROM x
WINDOW w AS (PARTITION BY f_id ORDER BY match DESC)
ORDER BY 2,1,3,4;
Подробно обяснение как работи крайният SELECT в този свързан отговор.
Работеща демонстрация на sqlfiddle.
Не сте определили кое съвпадение да изберете от набор от еднакво дълги съвпадения. Избирам един произволен победител от равенства.
PostgreSQL 9.1 въведе CTE, модифициращи данни , така че можете да използвате това в UPDATE изявление директно.