Аз сам отговарям на въпрос 1:Изглежда, че проблемът е свързан повече с Postgresql (или по-скоро базите данни като цяло). Като се вземат предвид точките, направени в тази статия:https://use-the- index-luke.com/sql/dml/insert Намерих следното:
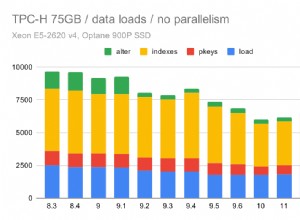
1) Премахването на всички индекси от целевата таблица доведе до изпълнение на заявката за 9 секунди. Повторното изграждане на индексите (в postgresql) отне още 12 секунди, така че все още доста под другите времена.
2) При наличие само на първичен ключ, вмъкването на редове, подредени по колоните на първичния ключ, намали необходимото време до около една трета. Това има смисъл, тъй като трябва да има малко или никакво разместване на необходимите индексни редове. Също така проверих, че това е причината моето декартово съединение в postgresql да е по-бързо на първо място (т.е. редовете бяха подредени по индекса, чисто случайно), поставяйки същите редове във временна таблица (неподредена) и вмъквайки от това всъщност отне много повече време.
3) Опитах подобни експерименти на нашите mysql системи и открих същото увеличение на скоростта на вмъкване при премахване на индекси. С mysql обаче изглеждаше, че възстановяването на индексите изразходва всяко спечелено време.
Надявам се това да помогне на всеки друг, който попадне на този въпрос при търсене.
Все още се чудя дали е възможно да премахна стъпката за запис в csv в python (Q2 по-горе), тъй като вярвам, че след това мога да напиша нещо в python, което би било по-бързо от чистия postgresql.
Благодаря, Джайлс