Базите данни на PostgreSQL имат естествен тип знаци, "сървърно кодиране". Обикновено е utf-8.
Целият текст е в това кодиране. Текст със смесено кодиране не се поддържа, освен ако се съхранява като bytea (т.е. като непрозрачни последователности от байтове).
Не можете да съхранявате "unicode" или "non-unicode" низове и PostgreSQL няма концепция за "varchar" срещу "nvarchar". С utf-8 знаците, които попадат в 7-битовия ASCII диапазон (и някои други), се съхраняват като един байт, а по-широките знаци изискват повече място за съхранение, така че е просто автоматично. utf-8 изисква повече място за съхранение от ucs-2 или utf-16 за текст, който е изцяло "широк" символ, но по-малко за текст, който е смесен.
PostgreSQL автоматично преобразува към/от текстовото кодиране на клиента, използвайки client_encoding настройка. Няма нужда да преобразувате изрично.
Ако вашият клиент е "Unicode" (което продуктите на Microsoft са склонни да казват, когато имат предвид UCS-2 или UTF-16), тогава повечето клиентски драйвери се грижат за всяко utf-8 <--> utf-16 преобразуване вместо вас.
Така че не трябва да ви пука, стига вашият клиент да извършва I/O с правилни опции за набор от символи и да задава правилно client_encoding който съвпада с данните, които действително изпраща по кабела. (Това е автоматично с повечето клиентски драйвери като PgJDBC, nPgSQL или Unicode psqlODBC драйвера).
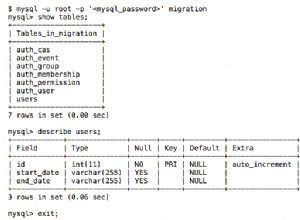
Вижте: