Извличането на този резултат рекурсивно е трудно (въпреки че е възможно). Въпреки това, обикновено не е много ефективен и има много по-добър начин за решаване на този проблем.
По принцип вие допълвате таблицата с допълнителна колона, която проследява дървото до върха - ще го нарека "Upchain". Това е просто дълъг низ, който изглежда нещо подобно:
<пре>name | id | parent_id | upchain
root1 | 1 | NULL | 1:
root2 | 2 | NULL | 2:
root1sub1 | 3 | 1 | 1:3:
root1sub2 | 4 | 1 | 1:4:
root2sub1 | 5 | 2 | 2:5:
root2sub2 | 6 | 2 | 2:6:
root1sub1sub1 | 7 | 3 | 1:3:7:
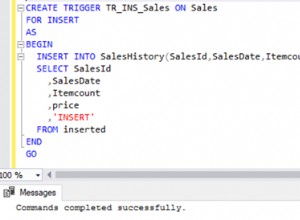
Много е лесно да поддържате това поле актуализирано, като използвате тригер в таблицата. (Извинения за терминологията, но винаги съм правил това с SQL Server). Всеки път, когато добавяте или изтривате запис, или актуализирате полето parent_id, просто трябва да актуализирате полето upchain в тази част от дървото. Това е тривиална работа, защото просто вземате upchain на родителския запис и добавяте id на текущия запис. Всички дъщерни записи се идентифицират лесно с помощта на LIKE за проверка за записи с начален низ в тяхната upchain.
Това, което правите ефективно, е да размените малко допълнителна дейност по писане за голямо запазване, когато дойдете да прочетете данните.
Когато искате да изберете пълен клон в дървото, това е тривиално. Да предположим, че искате клона под възел 1. Възел 1 има upchain '1:', така че знаете, че всеки възел в клона на дървото под този възел трябва да има upchain, започващ '1:...'. Така че просто правете това:
SELECT *
FROM table
WHERE upchain LIKE '1:%'
Това е изключително бързо (разбира се, индексирайте upchain полето). Като бонус също прави много дейности изключително лесни, като намиране на частични дървета, ниво в дървото и т.н.
Използвал съм това в приложения, които проследяват големи йерархии на докладване на служители, но можете да го използвате за почти всяка дървовидна структура (разбивка на части и т.н.)
Бележки (за всеки, който се интересува):
- Не съм описал стъпка по стъпка SQL кода, но след като разберете принципа, той е доста лесен за изпълнение. Не съм добър програмист, така че говоря от опит.
- Ако вече имате данни в таблицата, трябва да направите еднократна актуализация, за да синхронизирате upchains първоначално. Отново, това не е трудно, тъй като кодът е много подобен на кода UPDATE в тригерите.
- Тази техника също е добър начин за идентифициране на кръгови препратки, които иначе могат да бъдат трудни за забелязване.