Имах удоволствието да присъствам на PGDay UK миналата седмица – много хубаво събитие, надявам се, че ще имам шанса да се върна следващата година. Имаше много интересни разговори, но този, който привлече вниманието ми, беше Performace за заявки с групиране от Алексей Бащанов.
В миналото съм изнесъл доста подобни лекции, ориентирани към представянето, така че знам колко е трудно да се представят резултатите от сравнителните показатели по разбираем и интересен начин, а Алексей свърши доста добра работа, според мен. Така че, ако се занимавате с агрегиране на данни (т.е. BI, анализи или подобни натоварвания), препоръчвам да прегледате слайдовете и ако имате възможност да присъствате на разговора на някоя друга конференция, силно препоръчвам да го направите.
Но има един момент, в който обаче не съм съгласен с разговора. На редица места разговорът подсказва, че по принцип трябва да предпочитате HashAggregate, защото сортирането е бавно.
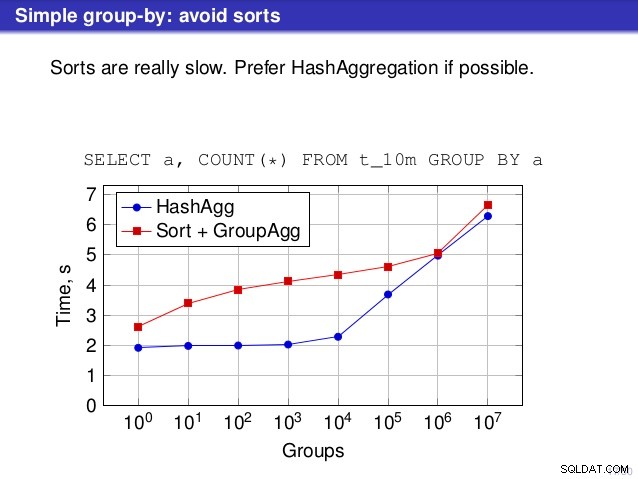
Считам това за малко подвеждащо, защото алтернатива на HashAggregate е GroupAggregate, а не Sort. Така че препоръката предполага, че всеки GroupAggregate има вложен сорт, но това не е съвсем вярно. GroupAggregate изисква сортиран вход и изричното Сортиране не е единственият начин за това – имаме също възли IndexScan и IndexOnlyScan, които елиминират разходите за сортиране и запазват другите предимства, свързани със сортираните пътища (особено IndexOnlyScan).
Позволете ми да демонстрирам как (IndexOnlyScan+GroupAggregate) се представя в сравнение с HashAggregate и (Sort+GroupAggregate) – скриптът, който използвах за измерванията, е тук. Той изгражда четири прости таблици, всяка със 100M реда и различен брой групи в колоната „branch_id“ (определяне на размера на хеш таблицата). Най-малкият има 10k групи
-- таблица с 10k групи създайте таблица t_10000 (branch_id bigint, number number); вмъкнете в t_10000 изберете mod(i, 10000), random() от generate_series(1,100000000) s(i);
и три допълнителни маси имат 100k, 1M и 5M групи. Нека изпълним тази проста заявка за агрегиране на данните:
ИЗБЕРЕТЕ клон_id, SUM(сума) ОТ t_10000 ГРУПИРАНЕ ПО 1
и след това убеди базата данни да използва три различни плана:
1) HashAggregate
SET enable_sort =off;SET enable_hashagg =on;EXPLAIN SELECT клон_id, SUM(сума) ОТ t_10000 GROUP BY 1; ПЛАН ЗА ЗАПИТВАНЕ------------------------------------------------ ---------------------------- HashAggregate (цена=2136943.00..2137067.99 реда=9999 ширина=40) Групов ключ:branch_id -> Seq Сканиране на t_10000 (цена=0,00..1636943,00 реда=100000000 ширина=19)(3 реда)
2) GroupAggregate (със сортиране)
SET enable_sort =on;SET enable_hashagg =off;EXPLAIN SELECT клон_id, SUM(сума) ОТ t_10000 GROUP BY 1; ПЛАН ЗА ЗАПИТВАНЕ------------------------------------------------ ------------------------------- GroupAggregate (цена=16975438.38..17725563.37 реда=9999 ширина=40) Групов ключ:branch_id -> Сортиране (цена=16975438.38..17225438.38 реда=100000000 ширина=19) Ключ за сортиране:branch_id -> Seq Scan on t_10000 (cost=0.00..1636943.00 реда)(0=000 rows)00 rows (0=000)3) GroupAggregate (с IndexOnlyScan)
ЗАДАДЕТЕ enable_sort =включено;ЗАДАДЕТЕ enable_hashagg =изключено;СЪЗДАЙТЕ ИНДЕКС НА t_10000 (идентификатор на клон, количество);ОБЯСНЯВАЙТЕ ИЗБЕРЕТЕ клон_id, SUM(сума) ОТ t_10000 ГРУПА ПО 1; ПЛАН ЗА ЗАПИТВАНЕ------------------------------------------------ ------------------------- GroupAggregate (цена=0,57..3983129,56 реда=9999 ширина=40) Ключ на групата:branch_id -> Сканиране само за индекс използвайки t_10000_branch_id_amount_idx на t_10000 (цена=0,57..3483004,57 реда=100000000 ширина=19)(3 реда)Резултати
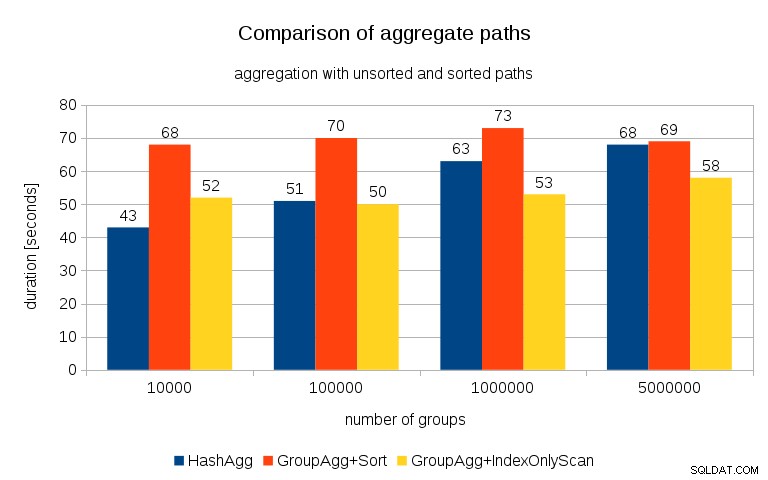
След измерване на тайминги за всеки план на всички таблици, резултатите изглеждат така:
За малки хеш таблици (вместващи се в L3 кеш, който е 16MB в този случай), пътят на HashAggregate е очевидно по-бърз от двата сортирани пътя. Но доста скоро GroupAgg+IndexOnlyScan става също толкова бърз или дори по-бърз – това се дължи на ефективността на кеша, основното предимство на GroupAggregate. Докато HashAggregate трябва да запази цялата хеш таблица в паметта наведнъж, GroupAggregate трябва да запази само последната група. И колкото по-малко памет използвате, толкова по-вероятно е тя да се вмести в L3 кеша, което е приблизително с порядък по-бързо в сравнение с обикновената RAM (за кешовете L1/L2 разликата е дори по-голяма).
Така че въпреки че има значителни режийни разходи, свързани с IndexOnlyScan (за случая 10k това е около 20% по-бавно от пътя на HashAggregate), тъй като хеш таблицата расте, съотношението на попадане в кеша L3 бързо пада и разликата в крайна сметка прави GroupAggregate по-бърз. И в крайна сметка дори GroupAggregate+Sort става наравно с пътя HashAggregate.
Може да възразите, че вашите данни обикновено имат сравнително малък брой групи и по този начин хеш таблицата винаги ще се вписва в L3 кеша. Но имайте предвид, че кешът на L3 се споделя от всички процеси, изпълнявани на процесора, а също и от всички части на плана за заявка. Така че, въпреки че в момента имаме ~20MB кеш L3 на сокет, вашата заявка ще получи само част от това и този бит ще бъде споделен от всички възли във вашата (вероятно доста сложна) заявка.
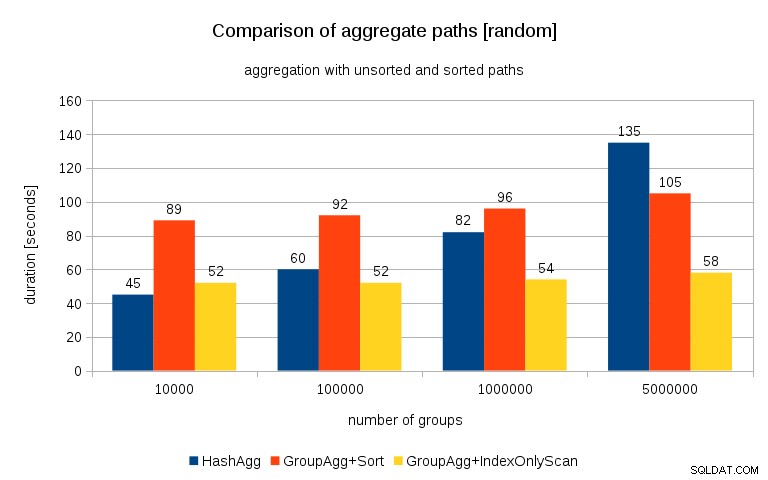
Актуализация 26/07/2016 :Както беше посочено в коментарите от Питър Геогеган, начинът, по който са генерирани данните, вероятно води до корелация – не стойностите (или по-скоро хешовете на стойностите), а разпределението на паметта. Повторих заявките с правилно рандомизирани данни, т.е. правя
вмъкнете в t_10000 select (10000*random())::bigint, random() от generate_series(1,100000000) s(i);вместо
вмъкнете в t_10000 select mod(i, 10000), random() от generate_series(1,100000000) s(i);и резултатите изглеждат така:
Сравнявайки това с предишната диаграма, мисля, че е доста ясно, че резултатите са още повече в полза на сортираните пътища, особено за набора от данни с 5M групи. Наборът от 5M данни също показва, че GroupAgg с изрично сортиране може да е по-бърз от HashAgg.
Резюме
Въпреки че HashAggregate вероятно е по-бърз от GroupAggregate с изрично сортиране (колебая се да кажа, че винаги е така), използването на GroupAggregate с IndexOnlyScan по-бързо може лесно да го направи много по-бързо от HashAggregate.
Разбира се, не можете да избирате точния план директно - плановникът трябва да направи това вместо вас. Но вие влияете върху процеса на избор чрез (а) създаване на индекси и (б) настройка на
work_mem. Ето защо понякога по-нискиwork_mem(иmaintenance_work_mem) стойностите водят до по-добра производителност.Допълнителните индекси обаче не са безплатни – те струват както процесорно време (при вмъкване на нови данни), така и дисково пространство. За IndexOnlyScans изискванията за дисково пространство може да са доста значителни, тъй като индексът трябва да включва всички колони, посочени от заявката, а обикновеният IndexScan няма да ви даде същата производителност, тъй като генерира много произволен I/O срещу таблицата (елиминира всички потенциалните печалби).
Друга хубава характеристика е стабилността на производителността – забележете как шансът за синхронизиране на HashAggregate зависи от броя на групите, докато пътищата на GroupAggregate се представят почти еднакво.