PostgreSQL идва с отличен набор от функции, несравним в пространството на RDBMS с отворен код. Най-вече е лесен за научаване и използване, особено за разработчиците на приложения. Някои части обаче просто не са лесни. Те изискват работа, за да се настроят и да се оправят, и обикновено също са критични за мисията.
Управление на връзките
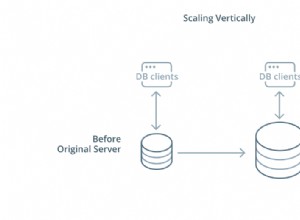
PostgreSQL стартира нов процес, наречен заден процес , за да обработва всяка връзка. Това е в контраст с модерните архитектури за обработка на връзки, базирани на цикъл на събития/threadpool, намиращи се в друг сравним сървърен софтуер. Размножаването на пълен процес отнема повече време и ресурси и се проявява като увеличени латентности на заявки в приложения, където връзките се отварят и затварят с висока скорост.
В повечето разгръщания се изисква обединяване на връзки на някакво ниво. На ниво приложение това може да бъде използването на вашия език за програмиране/библиотека. Например sql/DB.SetMaxIdleConncan може да се използва за увеличаване на повторното използване на връзката в рамките на едно приложение Go.
Често обаче ще трябва да използвате пул за връзки на трети страни или решение за балансиране на натоварването. Пуловите за връзки поддържат пул от неактивни връзки към горния Postgres сървър, които са присвоени и прокси към входящите клиентски връзки. Те обикновено анализират SQL, изпратен от клиентите, за да разпознаят границите на транзакциите и DML-ове за модифициране на данни, за да внедрят функции като обединяване на връзки на ниво транзакция и четене на реплики.
PgBouncer е популярен, лек пул с единична двоична връзка и често се изпълнява заедно с PostgreSQL в същата система.
PgPool е по-гъвкав от PgBouncer. Може също да извършва балансиране на натоварването и репликация например.
Обединяването на връзки обаче носи свой набор от главоболия. Първо, това е допълнителна подвижна част, която се поддържа във вашето разгръщане. Настройването на повторно удостоверяване също е проблем, ако имате клиенти, които използват различни идентификационни данни или механизми за удостоверяване. Някои функции на ниво връзка като LISTEN/NOTIFY, подготвени оператори, временни таблици и други подобни може да изискват допълнителна конфигурация или промени от страна на клиента, за да работят.
Нулеви надстройки по време на престой
Надстройката на PostgreSQL между второстепенни версии (13.x -> 13.y) включва инсталиране на новия пакет и рестартиране на сървърния процес. Въпреки че рестартирането на процеса на сървъра непременно ще наруши всички свързани клиенти, все пак е разумно да попитате, като се има предвид, че времето на престой е обвързано с продължителността на рестартирането на услугата.
Надстройката между основните (12.x -> 13.y) версии обаче е много по-голяма сделка. Обикновено колкото повече данни има, толкова по-болезнен е процесът.
Най-простият метод, който работи само за малки количества данни (да речем десетки GB), е да изхвърлите данните от старата версия и да ги възстановите в сървър с нова версия. Друга опция е да използвате pg_upgrade, което изисква оркестриран танц включващи двоични файлове на двете версии на Postgres.
И в двата случая базите данни ще бъдат неактивни за значителен период от време.
В идеалния случай би трябвало да е възможно да се репликира на сървър на нова версия и да се популяризира сървърът на новата версия като основен. Въпреки това, не е възможно да се направи стрийминг репликация към сървър в режим на готовност с различна основна версия. Логическата репликация, въпреки че изглежда добре подходяща за работата, има определени проблеми, които трябва да бъдат заобиколени, за да се осигури пълна репликация.
Повечето HA решения за Postgres разчитат на поточно репликация и следователно не можете да надграждате възли в клъстер един по един.
Настоящото състояние на техниката би било да се използва логическа репликация, като същевременно се заобикалят ограниченията на логическата репликация и е възможно да се включват ограничаващи функции, които приложенията могат да използват (като DDL) по време на фазата на надграждане.
Висока наличност
PostgreSQL идва с всички функции на ниско ниво, необходими за изграждане на HA решение:репликация с обратна връзка, каскадна репликация, синхронна репликация, режим на готовност, горещ режим на готовност, промоция в режим на готовност и т.н. Това обаче всъщност не предоставя HA решение от кутията. Няма рамки или инструменти за наблюдение на здравето и автоматично преминаване към режим на готовност. Няма понятие за HA клъстер с множество възли.
Ще трябва да настроите и стартирате решение на трета страна за създаване на разгръщания на Postgres с висока достъпност. Текущи фаворити arepg_auto_failoverand Patroni. Докато Patroni разчита на съществуващо високодостъпно хранилище за конфигурации като ZooKeeper или etcd, pg_auto_failover може да се справи без такъв.
Оценяването, внедряването и тестването на едно от тях в производството отнема време и усилия. Наръчниците за наблюдение, предупреждения и операции трябва да бъдат настроени и поддържани.
Управление на раздуване
MVCC архитектурата на PostgreSQL означава, че никакви данни никога не се презаписват – модифицирането на ред води само до изписване на нова версия на реда на диска. Изтриването на ред означава само запис, че редът е невидим за бъдещи транзакции. Когато версия на ред е недостъпна от текущи или бъдещи транзакции, тя вече не е от полза и се нарича „раздуване“. Процесът на събиране на този боклук се нарича „вакуум“.
Раздуването е невидимо за приложенията и се превръща единствено в главоболие на DBA. За таблици с тежки актуализации, наблюдението и управлението на раздуването е нетривиален проблем. Процесът на автоматично вакуумиране помага много, но може да се наложи праговете му да бъдат настроени на глобално или по- tablelevel, за да се гарантира, че размерите на таблицата не нарастват неуправляемо.
Индексите също се влияят от подуване, а автовакуумът не помага тук. Изтриването на редове и актуализирането на индексирани колони водят до мъртви записи в индексите. Тежките натоварвания при актуализиране с актуализации на индексирани колони могат да доведат до постоянно нарастващи и неефективни индекси. Няма еквивалент на вакуум за индекси. Единственото решение е да изградите отново целия индекс с помощта на REINDEX или да използвате VACUUM FULL върху таблицата.
Освен една стойност на таблица (pg_stat_all_tables.n_dead_tup), Postgres не предлага нищо по отношение на оценката на раздуването в таблица и изобщо нищо за индексите. Най-практичният начин все още остава изпълнението на страшно изглеждаща заявка от check_postgres.
pgmetrics включва заявката от check_postgres и може да произведе изход във формат JSON и CSV, който включва информация за размер и раздуване за всички таблици и индекси; които могат да бъдат въведени в инструменти за наблюдение или автоматизация.
pg_repack е популярна алтернатива на VACUUM FULL – може да върши същата работа, но без ключалки. Ако сте принудени да правите VACUUM FULL редовно, това е задължителен инструмент за разследване.
zheap е новият механизъм за съхранение на Postgres, който се разработва от години, който обещава да намали раздуването чрез актуализации на място.
Управление на план за заявки
Core PostgreSQL предлага само два елементарни инструмента в това пространство:
- pg_stat_statements разширение за анализ на заявки – това дава общата и средната стойност на времето за планиране и изпълнение на заявки, използване на диск и памет
- auto_explain разширение, което може да отпечатва планове за изпълнение на заявка в дестинацията на журнала на Postgres
Докато статистическите данни, предоставени от pg_stat_statements, са достатъчни, за да се справите, с помощта на auto_explain да принуди плановете в регистрационни файлове и след това да извлечете темата не повече от хак, особено в сравнение с търговските конкуренти на Postgres, които предлагат история на планове, базови характеристики и функции за управление.
Текущото състояние на техниката с Postgres е да копаете регистрационния файл за планове за заявка и да ги съхранявате другаде. Но може би най-неблагоприятният проблем е невъзможността да се свърже планът на заявката със съответните аналитични данни от pg_stat_statements. Начинът, по който pgDash прави това, е да анализира и двата текста на SQL заявката от pg_stat_statements и auto_explain изхода, да коригира за манипулирането, извършено от pg_stat_statements, и да се опита да съпостави двете. Изисква пълен анализатор на PostgreSQL на диалектен SQL.
Понастоящем базовото изравняване, настройката на политики за избор на план и т.н. просто не са възможни в основния PostgreSQL.
Има няколко разширения, които са основно подобрени версии на pg_stat_statements, но допълнителните стъпки, свързани с използването на разширение на трета страна, го правят предизвикателство за повечето хора, особено ако използват управляван доставчик на Postgres.
Настройка
PostgreSQL има множество опции за настройка, като се започне от настройката under-configured-by-defaultshared_bufferssetting. Някои са лесни за разбиране и настройка, като броя на паралелните работници за различни операции (max_worker_processes, max_parallel_* и т.н.). Други области са малко неясни (wal_compression, random_page_cost и т.н.), но като цяло са полезни. Най-досадните обаче са тези, които се нуждаят от количествено измерима информация за натоварването.
Например, ако work_mem е твърде нисък, заявките може да използват временни дискови файлове; ако са твърде високи и има достатъчно едновременни заявки, задните процеси на Postgres може да бъдат убити OOM. И така, как да разберете какъв номер да го зададете?
На практика, особено при OLTP работни натоварвания и натоварвания на уеб приложения, е невъзможно да се предвиди какво ще бъде пиковото търсене на памет за заявки. Най-добрият ви залог е да го зададете на разумна стойност, след което да наблюдавате заявките, за да видите дали някой от тях би могъл да се възползва от по-висока стойност на work_mem.
И как го правиш? Ще трябва да получите разширението auto_explain за да регистрирате плановете за изпълнение на заявката на всяка заявка, извлечете ги от регистрационните файлове на Postgres, разгледайте всеки план на заявка, за да видите дали използва базирани на диск външни сливания или растерно сканиране на купчина с блокове със загуби.
Не невъзможно, просто трудно.