Този блог е втората част от Внедряване на настройка на множество центрове за данни за PostgreSQL. В този удар ще покажем как да внедрите PostgreSQL в този тип среда и как да преминете при отказ в случай на главен отказ, като използвате функцията за автоматично възстановяване на ClusterControl.
В този момент ще приемем, че имате свързаност между центровете за данни (както видяхме в първата част на този блог) и имате необходимите сървъри за тази задача (както също споменахме в предишна част).
Разгръщане на PostgreSQL клъстер
Ще използваме ClusterControl за тази задача, така че ще приемем, че сте го инсталирали (може да бъде инсталиран на същия сървър на Load Balancer, но ако можете да използвате друг, още по-добре).
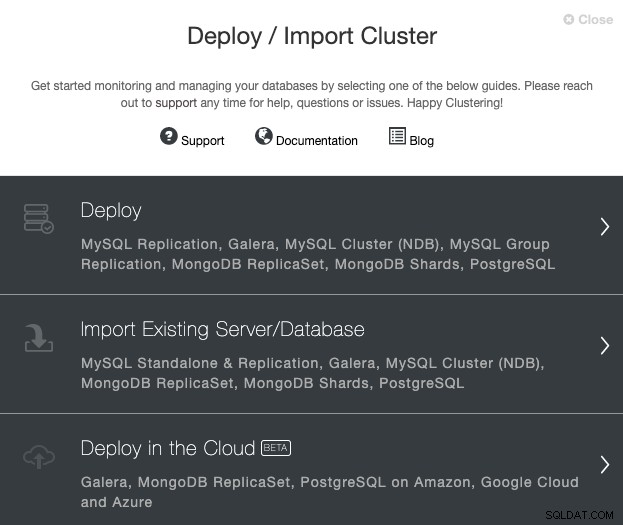
Отидете на вашия сървър ClusterControl и изберете опцията „Разгръщане“. Ако вече имате работещ екземпляр на PostgreSQL, тогава трябва да изберете „Импортиране на съществуващ сървър/база данни“.
Когато избирате PostgreSQL, трябва да посочите потребител, ключ или парола и порт за свържете се чрез SSH към нашите PostgreSQL хостове. Освен това имате нужда от името за вашия нов клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
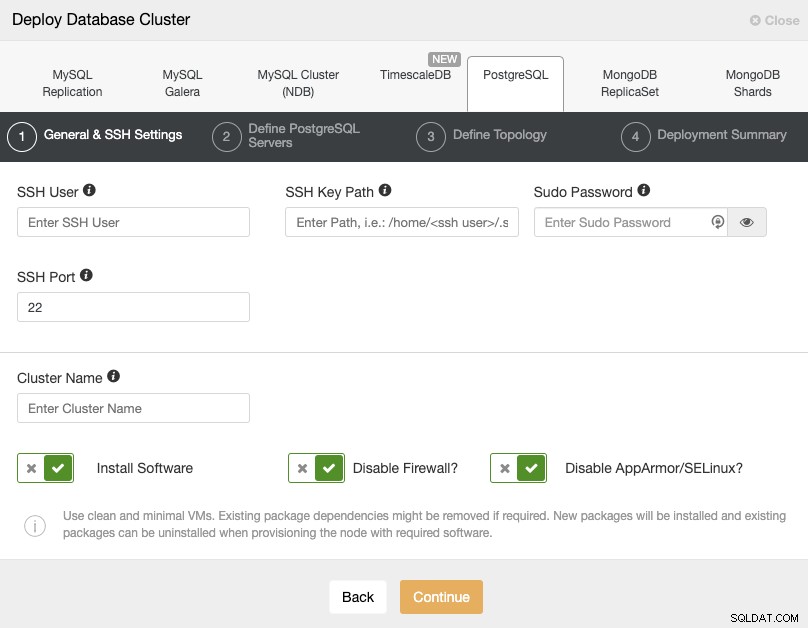
Моля, проверете потребителските изисквания на ClusterControl за тази задача тук, но ако сте следвали в предишния блог, трябва да използвате „отдалечения“ потребител тук и правилния SSH порт (както споменахме, се препоръчва да използвате различен, ако използвате публичния IP адрес за достъп до него вместо VPN).
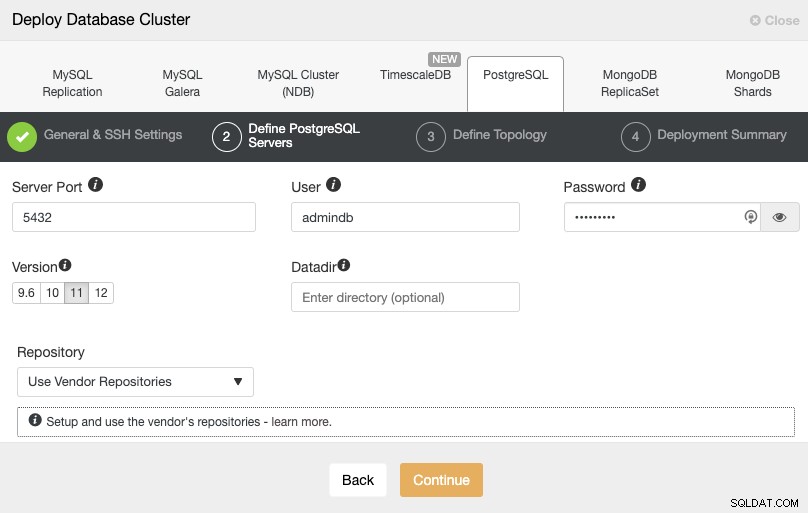
След като настроите информацията за SSH достъп, трябва да дефинирате потребителя на базата данни, версия и datadir (по избор). Можете също да посочите кое хранилище да използвате. В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете.
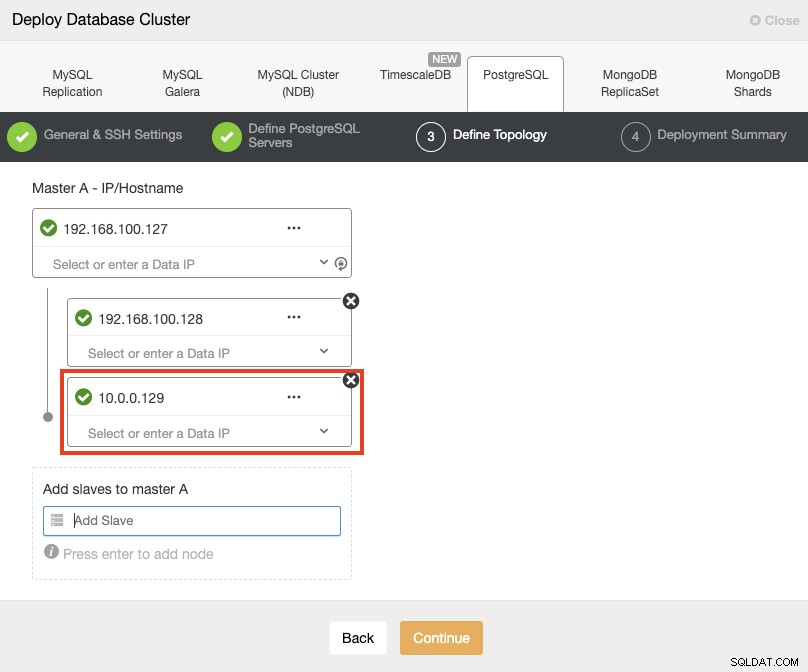
Когато добавяте вашите сървъри, можете да въведете IP или име на хост. В тази част ще използвате публичните IP адреси на вашите сървъри и както можете да видите в червеното поле, използвам различна мрежа за втория възел в режим на готовност. ClusterControl няма ограничения относно мрежата, която ще се използва. Единственото изискване за това е да имате SSH достъп до възела.
Следвайки предишния ни пример, тези IP адреси трябва да бъдат:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)В последната стъпка можете да изберете дали вашата репликация ще бъде синхронна или асинхронна.
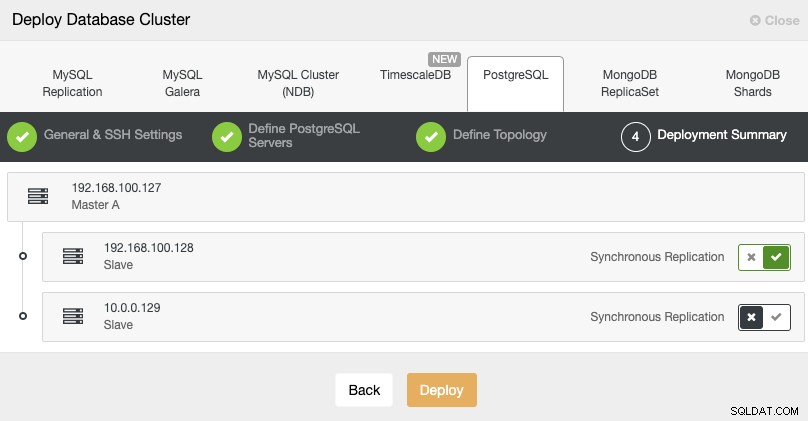
В този случай е важно да използвате асинхронна репликация за вашия отдалечен възел , ако не, вашият клъстер може да бъде засегнат от забавяне или проблеми с мрежата.
Можете да наблюдавате състоянието на създаването на вашия нов клъстер от монитора на активността на ClusterControl.
След като задачата приключи, можете да видите своя нов PostgreSQL клъстер в основен екран на ClusterControl.

Добавяне на PostgreSQL Load Balancer (HAProxy)
След като създадете своя клъстер, можете да изпълнявате няколко задачи върху него, като добавяне на балансьор на натоварване (HAProxy) или нова реплика.
За да последваме предишния ни пример, нека добавим балансьор на натоварване, който, както споменахме, ще ви помогне да управлявате вашата HA среда. За това отидете на ClusterControl -> Изберете PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer.
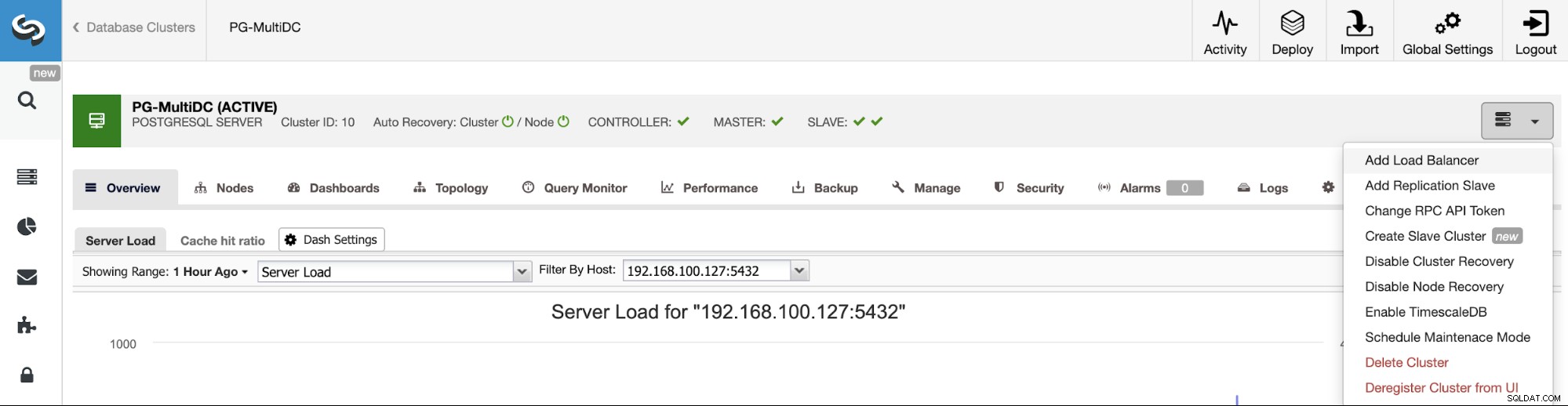
Тук трябва да добавите информацията, която ClusterControl ще използва за инсталиране и конфигуриране на HAProxy балансиране на натоварването. Този Load Balancer може да бъде инсталиран в същия сървър на ClusterControl, но ако можете да използвате друг, още по-добре.
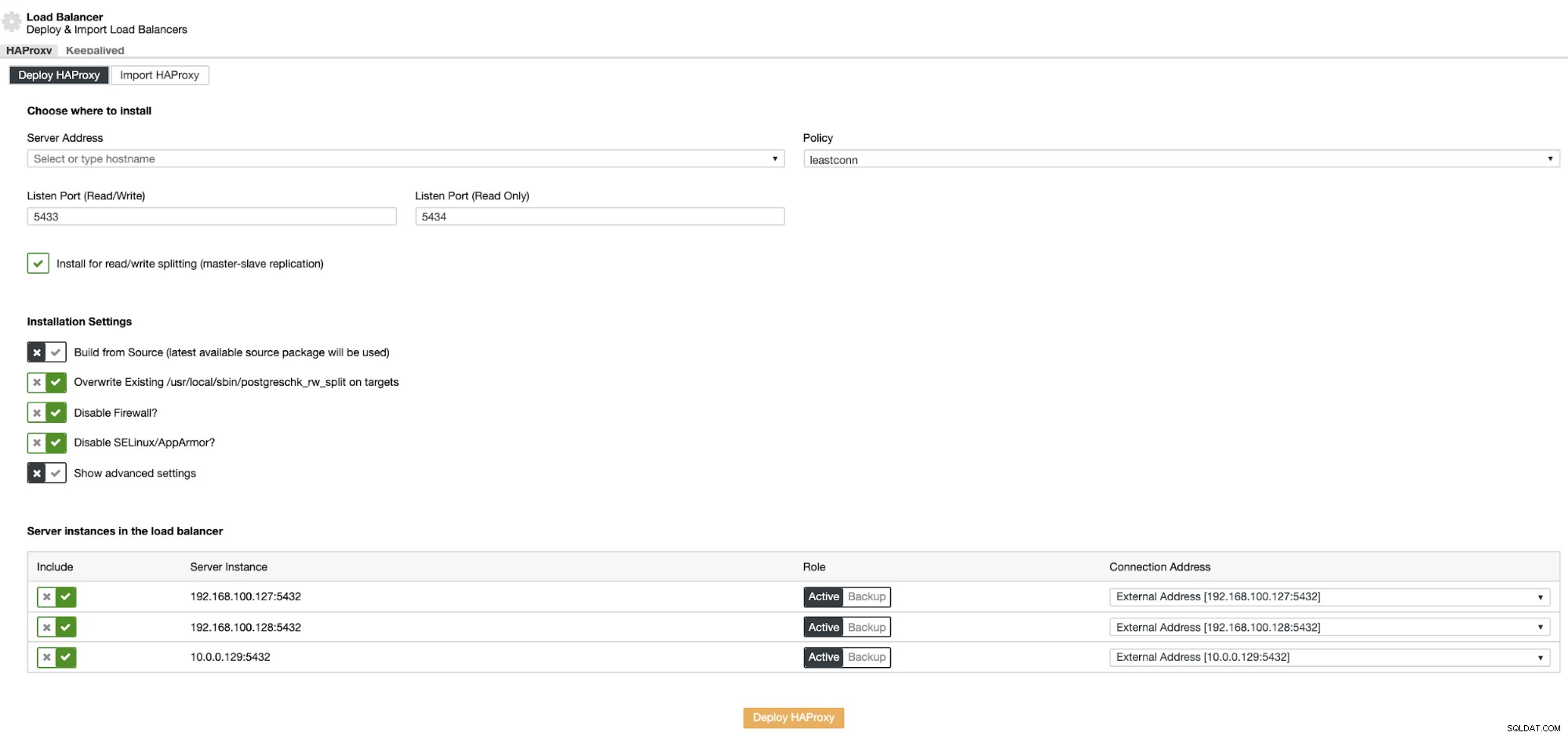
Информацията, която трябва да представите, е:
Действие:Разгръщане или импортиране.
Адрес на сървъра:IP адрес за вашия HAProxy сървър (може да бъде същият IP адрес на ClusterControl).
Порт за слушане (четене/запис):Порт за режим на четене/запис.
Порт за слушане (само за четене):Порт за режим само за четене.
Политика:Може да бъде:
- leastconn:Сървърът с най-малък брой връзки получава връзката.
- последователно:Всеки сървър се използва на свой ред, според теглото му.
- източник:IP адресът на източника се хешира и се разделя на общото тегло на работещите сървъри, за да се определи кой сървър ще получи заявката.
Инсталиране за разделяне на четене/запис:За репликация главен-подчинен.
Създаване от източник:Можете да изберете Инсталиране от мениджър на пакети или компилиране от източник.
И трябва да изберете кои сървъри искате да добавите към конфигурацията на HAProxy.
Освен това можете да конфигурирате разширени настройки като администратор на потребител, име на бекенда, изчакване и други.
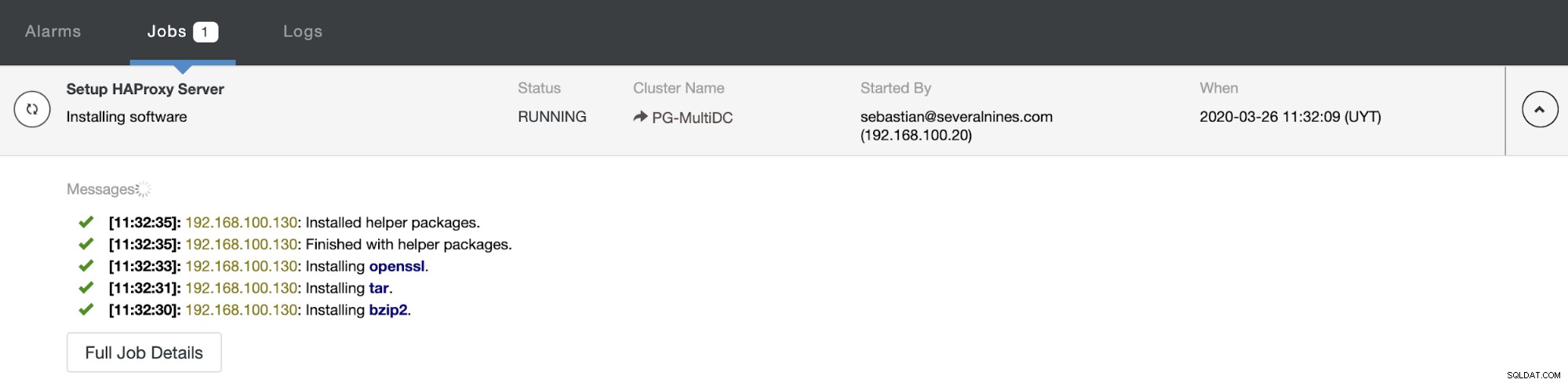
Когато завършите конфигурацията и потвърдите внедряването, можете да проследите напредъка в секцията Активност на потребителския интерфейс на ClusterControl.
И когато това приключи, можете да отидете на ClusterControl -> Nodes -> HAProxy възел и проверете текущото състояние.
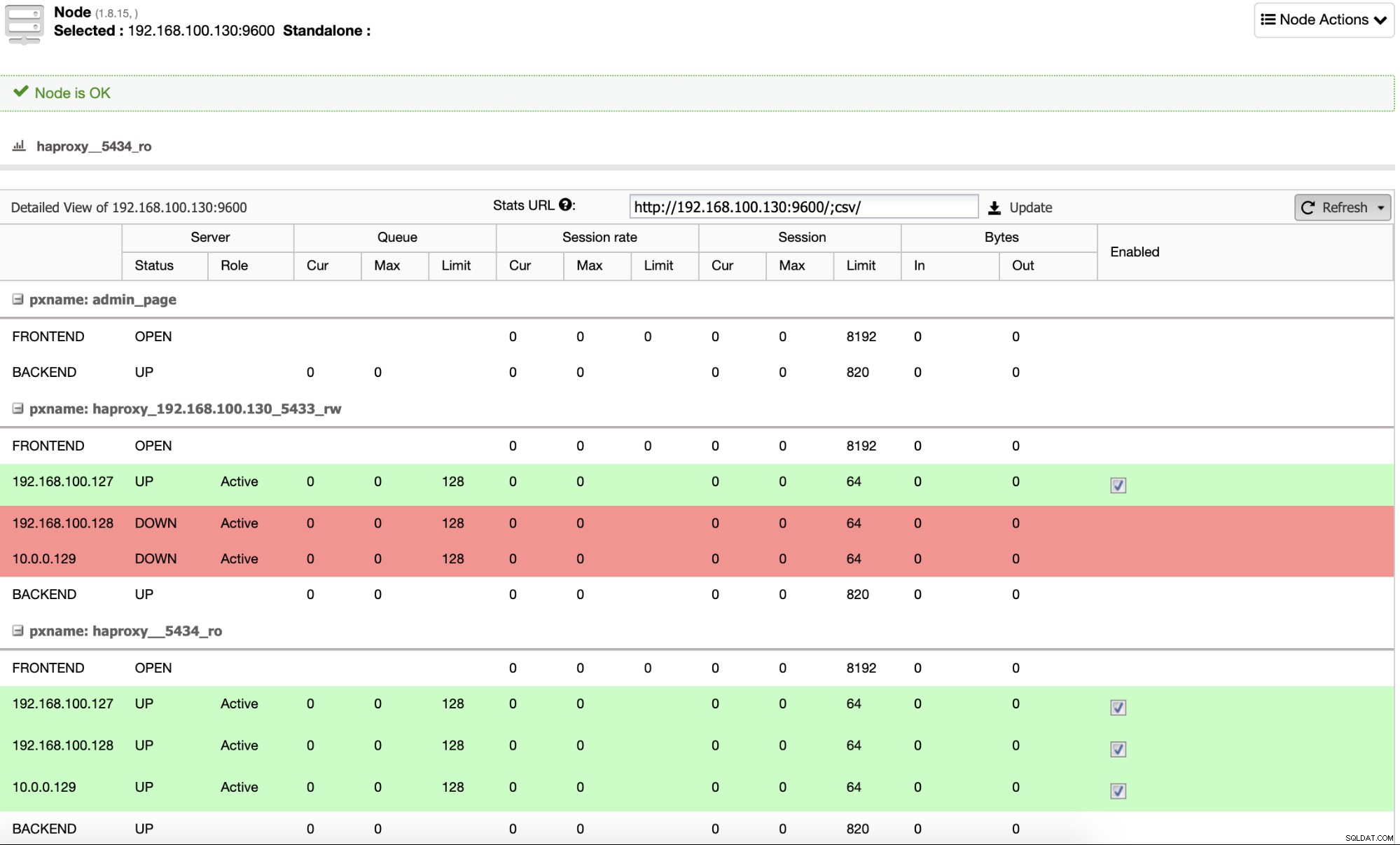
По подразбиране ClusterControl конфигурира HAProxy с два различни порта, единият за Read- Write, който ще се използва за приложението или потребителя за запис (и четене) на данни, и друг за Read-Only, който ще се използва за балансиране на трафика за четене между всички възли. В порта Read-Write е активиран само главният възел и в случай на повреда на главния, ClusterControl ще повиши най-модерния подчинен към главен и ще преконфигурира този порт, за да деактивира стария главен и да активира новия. По този начин вашето приложение все още може да работи в случай на повреда на главната база данни, тъй като трафикът се пренасочва от Load Balancer към правилния възел.
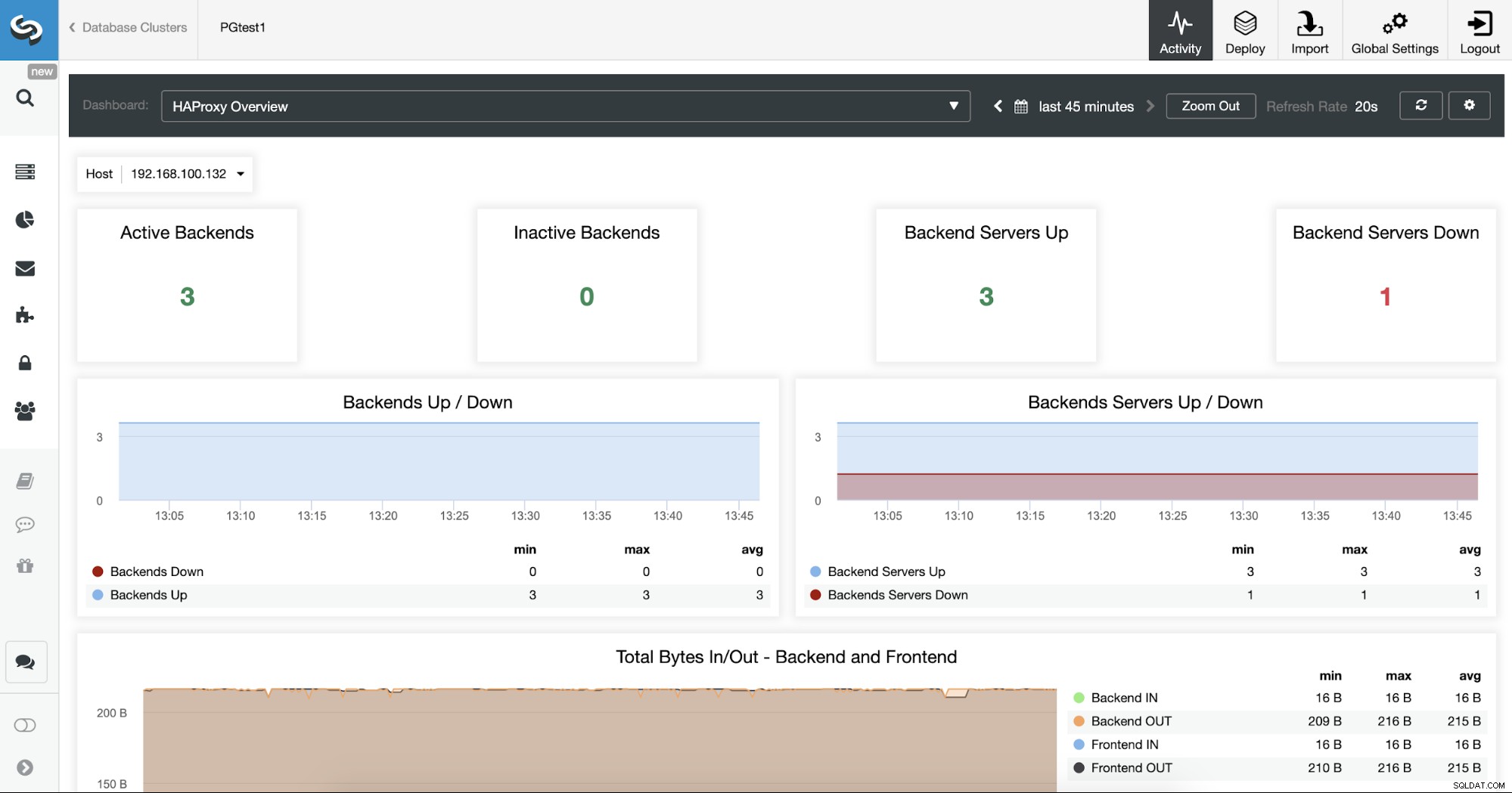
Можете също да наблюдавате своите HAProxy сървъри, като проверявате секцията Табло за управление.
Сега можете да подобрите своя дизайн на HA, като добавите нов HAProxy възел в отдалечен център за данни и конфигуриране на услугата Keepalived между тях. Keepalived ще ви позволи да използвате виртуален IP адрес, който е присвоен на активния възел на Load Balancer. Ако този възел не успее, този виртуален IP ще бъде мигриран към вторичния HAProxy възел, така че конфигурирането на този IP във вашето приложение ще ви позволи да поддържате всичко да работи в случай на проблем с Load Balancer.
Цялата тази конфигурация може да се извърши с помощта на ClusterControl.
Заключение
Като следвате този блог от две части, можете да внедрите настройка с множество центрове за данни за PostgreSQL с висока достъпност и SSH свързаност между центъра за данни, за да избегнете сложността на конфигурацията на VPN.
Използвайки асинхронна репликация за отдалечения възел, вие ще избегнете всеки проблем, свързан с латентността и производителността на мрежата, а с помощта на ClusterControl ще имате автоматично (или ръчно) преминаване на отказ в случай на повреда (наред с други няколко функции). Това може да е най-простият начин за достигане до тази топология и се надяваме, че това ще ви бъде полезно.