Всички съвременни системи за бази данни поддържат модул за оптимизиране на заявки за автоматично идентифициране на най-ефективната стратегия за изпълнение на SQL заявките. Ефективната стратегия се нарича „План“ и се измерва като цена, която е право пропорционална на „Време за изпълнение на заявка/отговор“. Планът е представен под формата на дървовиден изход от оптимизатора на заявки. Възлите на плановото дърво могат да бъдат разделени основно на следните 3 категории:
- Сканиране на възли :Както беше обяснено в предишния ми блог „Преглед на различните методи за сканиране в PostgreSQL“, той указва начина, по който трябва да бъдат извлечени данните от основната таблица.
- Присъединяване на възли :Както беше обяснено в предишния ми блог „Преглед на методите JOIN в PostgreSQL“, той показва как две таблици трябва да бъдат обединени, за да се получи резултатът от две таблици.
- Възли за материализация :Нарича се още като спомагателни възли. Предишните два вида възли бяха свързани с това как да се извличат данни от основна таблица и как да се обединяват данни, извлечени от две таблици. Възлите в тази категория се прилагат върху извлечените данни с цел по-нататъшен анализ или подготовка на отчет и т.н. Сортиране на данните, съвкупност от данни и др.
Помислете за прост пример за заявка като...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Да предположим, че е генериран план, съответстващ на заявката по-долу:
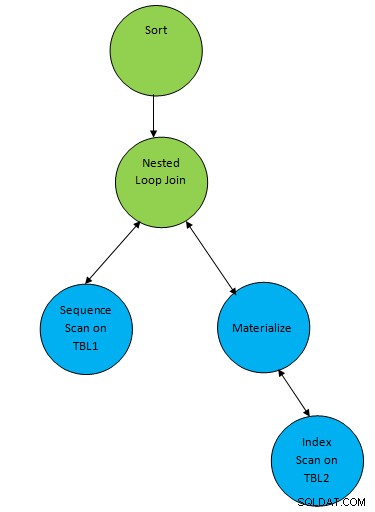
Така че тук един спомагателен възел „Сортиране“ е добавен върху резултата на присъединяване, за да сортирате данните в необходимия ред.
Някои от помощните възли, генерирани от оптимизатора на заявки PostgreSQL, са както следва:
- Сортиране
- Агрегат
- Групиране по агрегат
- Ограничение
- Уникален
- LockRows
- SetOp
Нека разберем всеки един от тези възли.
Сортиране
Както подсказва името, този възел се добавя като част от планово дърво, когато има нужда от сортирани данни. Сортираните данни могат да се изискват изрично или имплицитно, както следва в два случая:
Потребителският сценарий изисква сортирани данни като изход. В този случай възелът за сортиране може да бъде върху извличането на цялата информация, включително цялата друга обработка.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Забележка: Въпреки че потребителят изисква краен изход в сортиран ред, възелът за сортиране може да не бъде добавен в крайния план, ако има индекс в съответната таблица и колона за сортиране. В този случай той може да избере индексно сканиране, което ще доведе до имплицитно сортиран ред на данните. Например, нека създадем индекс в горния пример и да видим резултата:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Както беше обяснено в предишния ми блог Преглед на методите JOIN в PostgreSQL, Merge Join изисква и двете данни на таблицата да бъдат сортирани преди присъединяването. Така че може да се случи, че Merge Join е по-евтин от всеки друг метод на присъединяване, дори с допълнителна цена за сортиране. Така че в този случай възелът за сортиране ще бъде добавен между метода за присъединяване и сканиране на таблицата, така че сортираните записи да могат да бъдат предадени на метода за присъединяване.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Агрегат
Агрегатният възел се добавя като част от планово дърво, ако има агрегатна функция, използвана за изчисляване на единични резултати от множество входни редове. Някои от използваните агрегатни функции са COUNT, SUM, AVG (СРЕДНА), MAX (МАКСИМУМ) и MIN (МИНИМУМ).
Агрегиран възел може да дойде върху сканиране на базова релация или (и) при свързване на релации. Пример:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Тези видове възли са разширения на възела „Агрегат“. Ако агрегатните функции се използват за комбиниране на множество входни редове според тяхната група, тогава тези видове възли се добавят към планово дърво. Така че, ако заявката има използвана агрегатна функция и заедно с това има клауза GROUP BY в заявката, тогава към дървото на плана ще бъде добавен възел HashAggregate или GroupAggregate.
Тъй като PostgreSQL използва Cost Based Optimizer за генериране на оптимално дърво на плановете, е почти невъзможно да се отгатне кой от тези възли ще бъде използван. Но нека разберем кога и как се използва.
HashAggregate
HashAggregate работи чрез изграждане на хеш таблицата на данните, за да ги групира. Така че HashAggregate може да се използва от агрегат на ниво група, ако агрегатът се случва върху несортиран набор от данни.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Тук данните за схемата на таблицата demo1 са според примера, показан в предишния раздел. Тъй като има само 1000 реда за групиране, така че ресурсът, необходим за изграждане на хеш таблица, е по-малък от цената на сортирането. Инструментът за планиране на заявки решава да избере HashAggregate.
GroupAggregate
GroupAggregate работи върху сортирани данни, така че не изисква никаква допълнителна структура от данни. GroupAggregate може да се използва от агрегат на ниво група, ако агрегирането е върху сортиран набор от данни. За да се групират върху сортирани данни, той може да сортира изрично (чрез добавяне на възел за сортиране), или може да работи върху данни, извлечени от индекс, в който случай се сортира имплицитно.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Тук данните за схемата на таблицата demo2 са според примера, показан в предишния раздел. Тъй като тук има 100 000 реда за групиране, така че ресурсът, необходим за изграждане на хеш таблица, може да бъде по-скъп от цената на сортирането. Така че плановникът на заявки решава да избере GroupAggregate. Наблюдавайте тук записите, избрани от таблицата „demo2“, са изрично сортирани и за които има добавен възел в дървото на плана.
Вижте по-долу друг пример, където вече данните се извличат, сортирани поради сканиране на индекса:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Вижте по-долу още един пример, който въпреки че има индексно сканиране, все пак трябва изрично да сортира като колоната, на която индексът там и колоната за групиране не са еднакви. Така че все пак трябва да се сортира според колоната за групиране.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Забележка: GroupAggregate/HashAggregate може да се използва за много други непреки заявки, въпреки че агрегирането с група не е налице в заявката. Зависи от това как планиращият интерпретира заявката. напр. Да кажем, че трябва да получим различна стойност от таблицата, тогава тя може да се види като група от съответната колона и след това да вземем една стойност от всяка група.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Така че тук HashAggregate се използва, въпреки че няма агрегиране и групиране по участващи.
Ограничение
Ограничените възли се добавят към дървото на плана, ако клаузата „limit/offset“ се използва в заявката SELECT. Тази клауза се използва за ограничаване на броя на редовете и по избор предоставяне на отместване, за да започне четене на данни. Пример по-долу:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Уникален
Този възел се избира, за да получи различна стойност от основния резултат. Имайте предвид, че в зависимост от заявката, селективността и друга информация за ресурса, отделната стойност може да бъде извлечена с помощта на HashAggregate/GroupAggregate също без използване на уникален възел. Пример:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)Заключващи редове
PostgreSQL предоставя функционалност за заключване на всички избрани редове. Редовете могат да бъдат избрани в режим „Споделен“ или „Изключителен“ режим в зависимост от клаузата „ЗА СПОДЕЛЯНЕ“ и „ЗА АКТУАЛИЗИРАНЕ“ съответно. Нов възел „LockRows“ се добавя към дървото на плановете за постигане на тази операция.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL предоставя функционалност за комбиниране на резултатите от две или повече заявки. Така че, тъй като типът на възела Join се избира за свързване на две таблици, подобен тип възел SetOp се избира, за да комбинира резултатите от две или повече заявки. Например, помислете за таблица със служители с техния идентификационен номер, име, възраст и заплата, както е по-долу:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Сега нека вземем служители на възраст над 25 години:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Сега нека вземем служители със заплата над 95 милиона:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Сега, за да получим служители на възраст над 25 години и заплата над 95 милиона, можем да напишем по-долу запитване за пресичане:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) И така, тук се добавя нов вид възел HashSetOp за оценка на пресечната точка на тези две отделни заявки.
Обърнете внимание, че тук има добавени други два вида нов възел:
Добавяне
Този възел се добавя, за да комбинира множество набори резултати в един.
Сканиране на подзаявка
Този възел се добавя, за да оцени всяка подзаявка. В горния план подзаявката се добавя, за да се оцени една допълнителна константна стойност на колоната, която показва кой входен набор е допринесъл за конкретен ред.
HashedSetop работи, използвайки хеша на основния резултат, но е възможно да се генерира базирана на сортиране SetOp операция от оптимизатора на заявки. Възелът Settop, базиран на сортиране, се обозначава като „Setop“.
Забележка:Възможно е да се постигне същият резултат, както е показано в горния резултат с една заявка, но тук той е показан с помощта на intersect само за лесна демонстрация.
Заключение
Всички възли на PostgreSQL са полезни и се избират въз основа на естеството на заявката, данните и т.н. Много от клаузите са съпоставени една към една с възли. За някои клаузи има множество опции за възли, които се решават въз основа на изчисленията на разходите за основните данни.