Когато трябва да внедрите система за анализ за дадена компания, често възниква въпросът къде трябва да се съхраняват данните. Не винаги има перфектен вариант за всички изисквания и зависи от бюджета, количеството данни и нуждите на компанията.
PostgreSQL, като най-модерната база данни с отворен код, е толкова гъвкава, че може да служи като проста релационна база данни, база данни от времеви серии и дори като ефективно, евтино решение за съхранение на данни. Можете също да го интегрирате с няколко инструмента за анализ.
Ако търсите широко съвместимо, евтино и ефективно хранилище за данни, най-добрата опция за база данни може да бъде PostgreSQL, но защо? В този блог ще видим какво е склад за данни, защо е необходим и защо PostgreSQL може да бъде най-добрият вариант тук.
Какво е склад за данни
Склад за данни е система от стандартизирана, последователна и интегрирана, която съдържа текущи или исторически данни от един или повече източници, които се използват за отчитане и анализ на данни. Счита се за основен компонент на бизнес разузнаването, което е стратегията и технологията, използвани от една компания за по-добро разбиране на нейния търговски контекст.
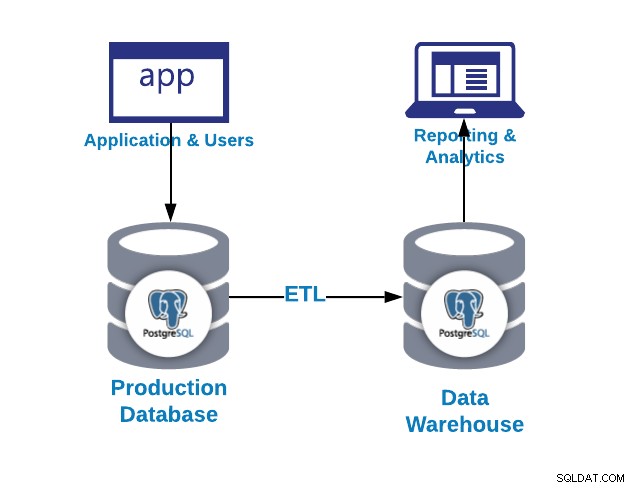
Първият въпрос, който може да зададете, е защо ми е необходим склад за данни?
- Интеграция:Интегрирайте/централизирайте данни от множество системи/бази данни
- Стандартизиране:Стандартизирайте всички данни в един и същ формат
- Анализ:Анализирайте данните в исторически контекст
Някои от предимствата на склад за данни могат да бъдат...
- Интегрирайте данни от множество източници в една база данни
- Избягвайте заключването или натоварването на продукцията поради продължителни заявки
- Съхранявайте историческа информация
- Преструктурирайте данните, за да отговарят на изискванията за анализ
Както видяхме в предишното изображение, можем да използваме PostgreSQL както за OLAP, така и за OLTP предложения. Да видим разликата.
- OLTP:Онлайн обработка на транзакции. Като цяло има голям брой кратки онлайн транзакции (INSERT, UPDATE, DELETE), генерирани от активността на потребителя. Тези системи наблягат на много бърза обработка на заявки и поддържане на целостта на данните в среди с множествен достъп. Тук ефективността се измерва с броя на транзакциите в секунда. OLTP бази данни съдържат подробни и актуални данни.
- OLAP:Онлайн аналитична обработка. Като цяло има малък обем сложни транзакции, генерирани от големи отчети. Времето за реакция е мярка за ефективност. Тези бази данни съхраняват обобщени исторически данни в многоизмерни схеми. OLAP бази данни се използват за анализиране на многоизмерни данни от множество източници и гледни точки.
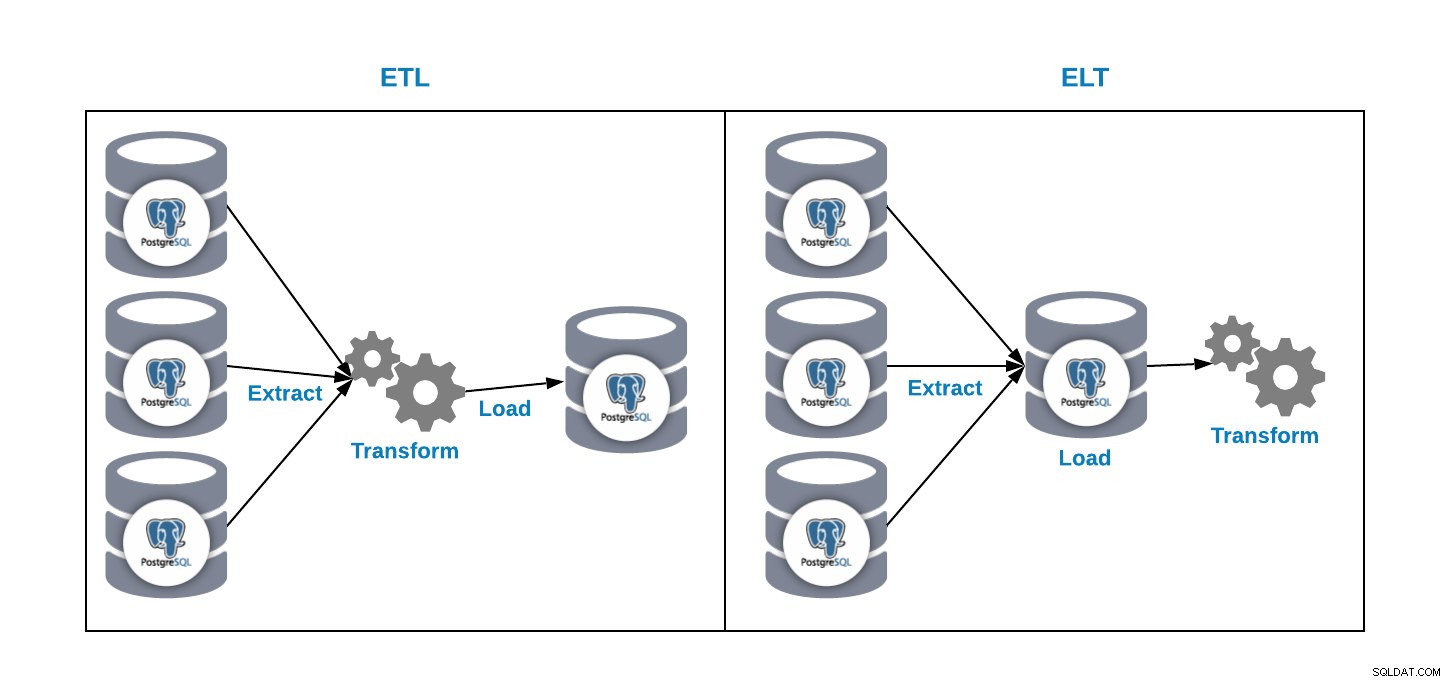
Имаме два начина да заредим данни в нашата база данни за анализ:
- ETL:Извличане, трансформиране и зареждане. Това е начинът да генерираме нашето хранилище за данни. Първо извлечете данните от производствената база данни, трансформирайте данните според нашите изисквания и след това заредете данните в нашето хранилище за данни.
- ELT:Извличане, зареждане и трансформиране. Първо извлечете данните от производствената база данни, заредете ги в базата данни и след това трансформирайте данните. Този начин се нарича Data Lake и е нова концепция за управление на нашите големи данни.
И сега, вторият въпрос, защо трябва да използвам PostgreSQL за моето хранилище за данни?
Предимства на PostgreSQL като хранилище за данни
Нека разгледаме някои от предимствата на използването на PostgreSQL като склад за данни...
- Разходи:Ако използвате локална среда, цената за самия продукт ще бъде $0, дори ако използвате някакъв продукт в облака, вероятно цената на продукт, базиран на PostgreSQL, ще бъде по-малка от останалите продукти.
- Мащаб:Можете да го мащабирате по прост начин, като добавите толкова възли-реплика, колкото искате.
- Ефективност:С правилна конфигурация, PostgreSQL има наистина добра производителност при различни escenarios.
- Съвместимост:Можете да интегрирате PostgreSQL с външни инструменти или приложения за извличане на данни, OLAP и отчитане.
- Разширяемост:PostgreSQL има дефинирани от потребителя типове данни и функции.
Има и някои функции на PostgreSQL, които могат да ни помогнат да управляваме информацията за нашето хранилище на данни...
- Временни таблици:Това е краткотрайна таблица, която съществува по време на сесия на база данни. PostgreSQL автоматично премахва временните таблици в края на сесия или транзакция.
- Съхранени процедури:Можете да го използвате за създаване на процедури или функции на множество езици (PL/pgSQL, PL/Perl, PL/Python и т.н.).
- Разделяне на дялове:Това е наистина полезно за поддръжка на база данни, заявки, използващи ключ на дял и производителност INSERT.
- Материализиран изглед:Резултатите от заявката се показват като таблица.
- Пространства за таблици:Можете да промените местоположението на данните на друг диск. По този начин ще имате паралелен достъп до диска.
- Съвместим с PITR:Можете да създавате резервни копия, съвместими с възстановяване по време, така че в случай на неуспех можете да възстановите състоянието на базата данни за определен период от време.
- Огромна общност:И не на последно място, PostgreSQL има огромна общност, където можете да намерите подкрепа по много различни въпроси.
Конфигуриране на PostgreSQL за използване на хранилище за данни
Няма най-добра конфигурация, която да се използва във всички случаи и във всички технологии за бази данни. Зависи от много фактори като хардуер, употреба и системни изисквания. По-долу са дадени няколко съвета за конфигуриране на вашата PostgreSQL база данни да работи като склад за данни по правилния начин.
На базата на памет
- max_connections:Като база данни за хранилище на данни нямате нужда от голямо количество връзки, защото това ще се използва за отчитане и анализиране, така че можете да ограничите максималния брой връзки с помощта на този параметър.
- shared_buffers:Задава количеството памет, което сървърът на базата данни използва за споделени буфери на паметта. Разумна стойност може да бъде от 15% до 25% от RAM паметта.
- effective_cache_size:Тази стойност се използва от планировщика на заявки, за да вземе предвид планове, които могат или не могат да се поберат в паметта. Това се взема предвид в оценките на разходите за използване на индекс; висока стойност прави по-вероятно да се използват индексни сканирания, а ниската стойност прави по-вероятно да се използват последователни сканирания. Разумна стойност би била около 75% от RAM паметта.
- work mem:Указва количеството памет, което ще се използва от вътрешните операции на ORDER BY, DISTINCT, JOIN и хеш таблиците, преди да се запише във временните файлове на диска. Когато конфигурираме тази стойност, трябва да вземем предвид, че няколко сесии изпълняват тези операции едновременно и всяка операция ще може да използва толкова памет, колкото е посочена от тази стойност, преди да започне да записва данни във временни файлове. Разумна стойност може да бъде около 2% от RAM паметта.
- maintenance_work_mem:Посочва максималния обем памет, който операциите по поддръжката ще използват, като ВАКУУМ, СЪЗДАВАНЕ НА ИНДЕКС и ПРОМЕНЯНЕ НА ТАБЛИЦАТА, ДОБАВЯНЕ НА ВЪНШЕН КЛЮЧ. Разумна стойност може да бъде около 15% от RAM паметта.
Базиран на процесора
- Max_worker_processes:Задава максималния брой фонови процеси, които системата може да поддържа. Разумна стойност може да бъде броят на процесорите.
- Max_parallel_workers_per_gather:Задава максималния брой работници, които могат да бъдат стартирани от един възел Gather или Gather Merge. Разумна стойност може да бъде 50% от броя на процесора.
- Max_parallel_workers:Задава максималния брой работници, които системата може да поддържа за паралелни заявки. Разумна стойност може да бъде броят на процесорите.
Тъй като данните, заредени в нашето хранилище за данни, не трябва да се променят, можем също да изключим Autovacuum, за да избегнем допълнително натоварване на вашата PostgreSQL база данни. Процесите Вакуум и Анализ могат да бъдат част от процеса на пакетно зареждане.
Заключение
Ако търсите широко съвместимо, евтино и високопроизводително хранилище за данни, определено трябва да обмислите PostgreSQL като опция за вашата база данни за склад за данни. PostgreSQL има много предимства и функции, полезни за управлението на нашето хранилище за данни, като разделяне, съхранени процедури и дори повече.



