В тази 3-та част на Сравнителен анализ на управлявани PostgreSQL облачни решения , се възползвах от безплатното ниво на GCP на Google. Беше полезно преживяване и като системен администратор, прекарващ по-голямата част от времето си на конзолата, не можех да пропусна възможността да изпробвам облачната обвивка, една от функциите на конзолата, която отличава Google от доставчика на облак, с който съм по-запознат , Amazon Web Services.
За да обобщя бързо, в част 1 разгледах наличните инструменти за сравнителен анализ и обясних защо избрах AWS Benchmark Procedure за Aurora. Също така направих сравнителен анализ на Amazon Aurora за PostgreSQL версия 10.6. В част 2 прегледах AWS RDS за PostgreSQL версия 11.1.
По време на този кръг тестовете, базирани на AWS Benchmark Procedure за Aurora, ще се изпълняват срещу Google Cloud SQL за PostgreSQL 9.6, тъй като версията 11.1 все още е в бета версия.
Облачни екземпляри
Предварителни условия
Както беше споменато в предишните две статии, избрах да оставя настройките на PostgreSQL при техните облачни GUC по подразбиране, освен ако не пречат на тестовете да се изпълняват (вижте по-долу). Припомнете си от предишни статии, че предположението беше, че нестандартният доставчик на облак трябва да има конфигуриран екземпляр на базата данни, за да осигури разумна производителност.
Корекцията за синхронизиране на AWS pgbench за PostgreSQL 9.6.5 се прилага ясно към версията на Google Cloud на PostgreSQL 9.6.10.
Използвайки информацията, която Google публикува в своя блог Google Cloud for AWS Professionals, съпоставих спецификациите за клиента и целевите екземпляри по отношение на компонентите Compute, Storage и Networking. Например, Google Cloud еквивалент на AWS Enhanced Networking се постига чрез оразмеряване на изчислителния възел въз основа на формулата:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Когато става въпрос за настройка на целевия екземпляр на базата данни, подобно на AWS, Google Cloud не позволява реплики, но съхранението е криптирано в състояние на покой и няма опция за деактивирането му.
И накрая, за да се постигне най-добра производителност на мрежата, клиентът и целевите екземпляри трябва да се намират в една и съща зона на наличност.
Клиент
Спецификациите на клиентския екземпляр, съответстващи на най-близкия екземпляр на AWS, са:
- vCPU:32 (16 ядра x 2 нишки/ядро)
- RAM:208 GiB (максимум за 32 vCPU екземпляр)
- Съхранение:постоянен диск на Compute Engine
- Мрежа:16 Gbps (макс. от [32 vCPU x 2 Gbps/vCPU] и 16 Gbps)
Подробности за екземпляра след инициализация:
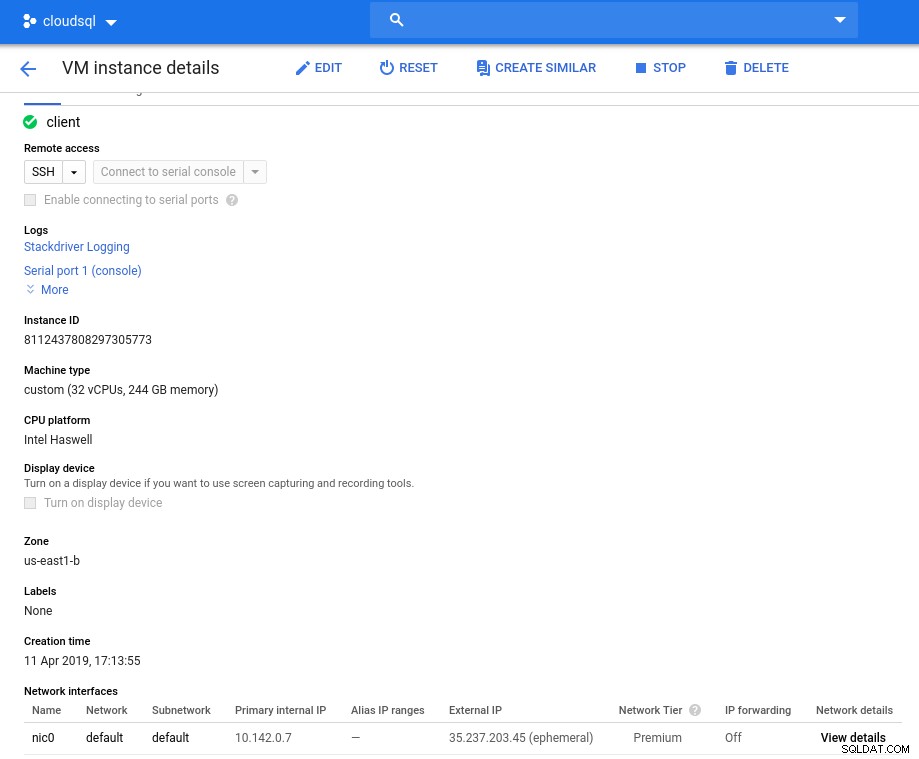 Клиентски екземпляр:Компютър и мрежа
Клиентски екземпляр:Компютър и мрежа Забележка:Инстанциите по подразбиране са ограничени до 24 vCPU. Техническата поддръжка на Google трябва да одобри увеличението на квотата до 32 vCPU на екземпляр.

Въпреки че такива заявки обикновено се обработват в рамките на 2 работни дни, трябва да дам палец на услугите за поддръжка на Google, че са изпълнили заявката ми само за 2 часа.
За любопитните, формулата за скорост на мрежата се основава на документацията за изчислителния двигател, посочена в този блог на GCP.
DB клъстер
По-долу са спецификациите на екземпляра на базата данни:
- vCPU:8
- RAM:52 GiB (максимум)
- Съхранение:144 MB/s, 9 000 IOPS
- Мрежа:2000 MB/s
Имайте предвид, че максималната налична памет за 8 vCPU екземпляр е 52 GiB. Повече памет може да бъде разпределена чрез избор на по-голям екземпляр (повече vCPU):
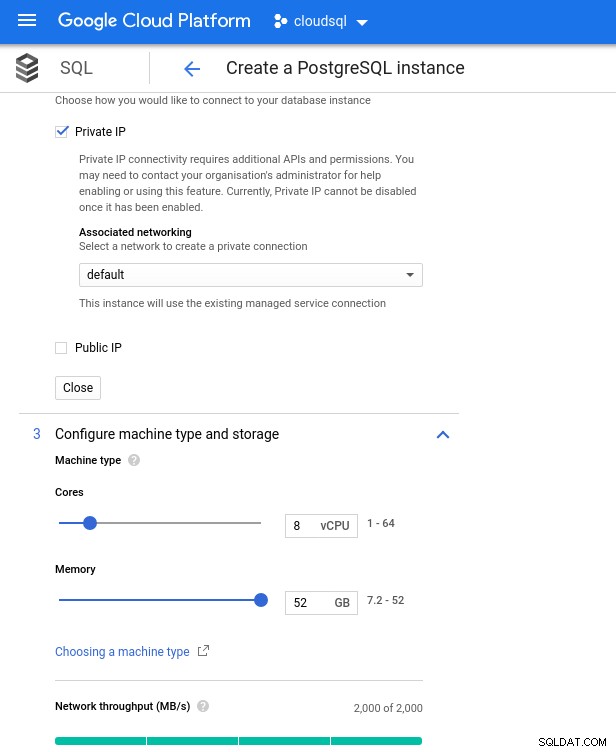 Оразмеряване на процесора и паметта на базата данни
Оразмеряване на процесора и паметта на базата данни Въпреки че Google SQL може автоматично да разшири основното хранилище, което между другото е наистина страхотна функция, аз избрах да деактивирам опцията, за да бъда в съответствие с набора от функции на AWS и да избегна потенциално въздействие на входно/изходно устройство по време на операцията за преоразмеряване. („потенциал“, защото не би трябвало да има никакво отрицателно въздействие, но според моя опит преоразмеряването на всеки тип основно хранилище увеличава I/O, дори и за няколко секунди).
Припомнете си, че екземплярът на базата данни на AWS беше подкрепен от оптимизирано EBS съхранение, което осигуряваше максимум:
- 1700 Mbps честотна лента
- 212,5 MB/s пропускателна способност
- 12 000 IOPS
С Google Cloud постигаме подобна конфигурация, като коригираме броя на vCPU (вижте по-горе) и капацитета за съхранение:
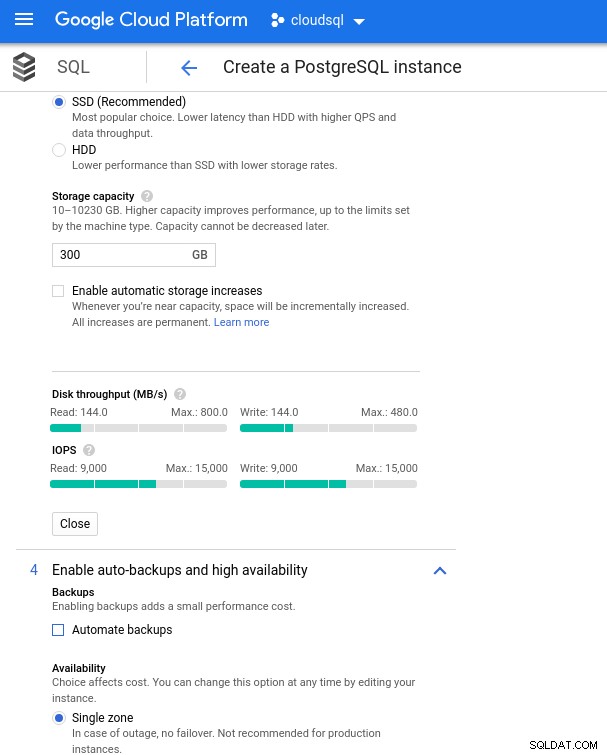 Конфигуриране на база данни за съхранение и настройки за архивиране
Конфигуриране на база данни за съхранение и настройки за архивиране Изпълнение на бенчмарковете
Настройка
След това инсталирайте инструментите за сравнителен анализ, pgbench и sysbench, като следвате инструкциите в ръководството на Amazon, адаптирано към PostgreSQL версия 9.6.10.
Инициализирайте променливите на средата на PostgreSQL в .bashrc и задайте пътищата към двоични файлове и библиотеки на PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libКонтролен списък преди полета:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)И ние сме готови за излитане:
pgbench
Инициализирайте базата данни pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…и няколко минути по-късно:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Както вече сме свикнали, размерът на базата данни трябва да бъде 160GB. Нека проверим това:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)След завършване на всички приготовления започнете теста за четене/запис:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsОпа! Какъв е максимумът?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Така че, докато AWS задава до голяма степен достатъчно max_connections, тъй като не се сблъсках с този проблем, Google Cloud изисква малка настройка... Обратно към облачната конзола, актуализирайте параметъра на базата данни, изчакайте няколко минути и след това проверете:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Рестартирането на теста изглежда, че всичко работи добре:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...но има и друга уловка. Бях в изненада, когато се опитах да отворя нова psql сесия, за да преброя броя на връзките:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsВъзможно ли е superuser_reserved_connections да не е по подразбиране?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Това е по подразбиране, тогава какво друго може да бъде?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Бинго! Друг удар на max_connections се грижи за това, но изискваше да рестартирам pgbench теста. И това е, хора, историята зад очевидното дублиране в графиките по-долу.
И накрая, резултатите са в:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Попълване на базата данни:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareИзход:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...И сега стартирайте теста:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runИ резултатите:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Показатели за сравнителен анализ
Приставката PostgreSQL за Stackdriver е остаряла от 28 февруари 2019 г. Въпреки че Google препоръчва Blue Medora, за целите на тази статия избрах да премахна създаването на акаунт и да разчитам на наличните показатели на Stackdriver.
- Използване на процесора:
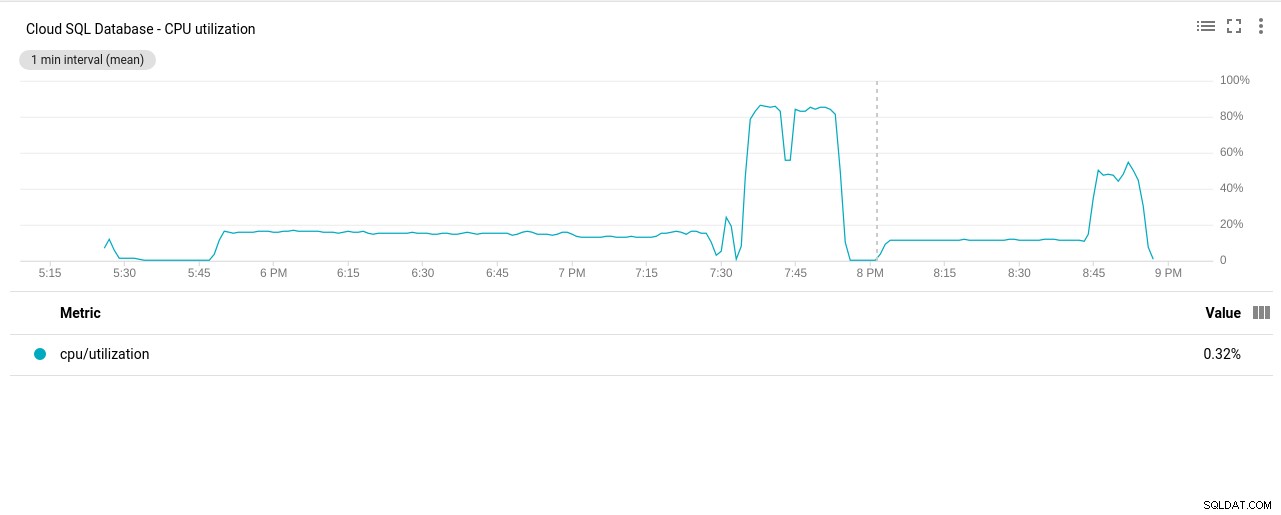 Автор на снимки Google Cloud SQL:Използване на процесора PostgreSQL
Автор на снимки Google Cloud SQL:Използване на процесора PostgreSQL - Операции за четене/запис на диск:
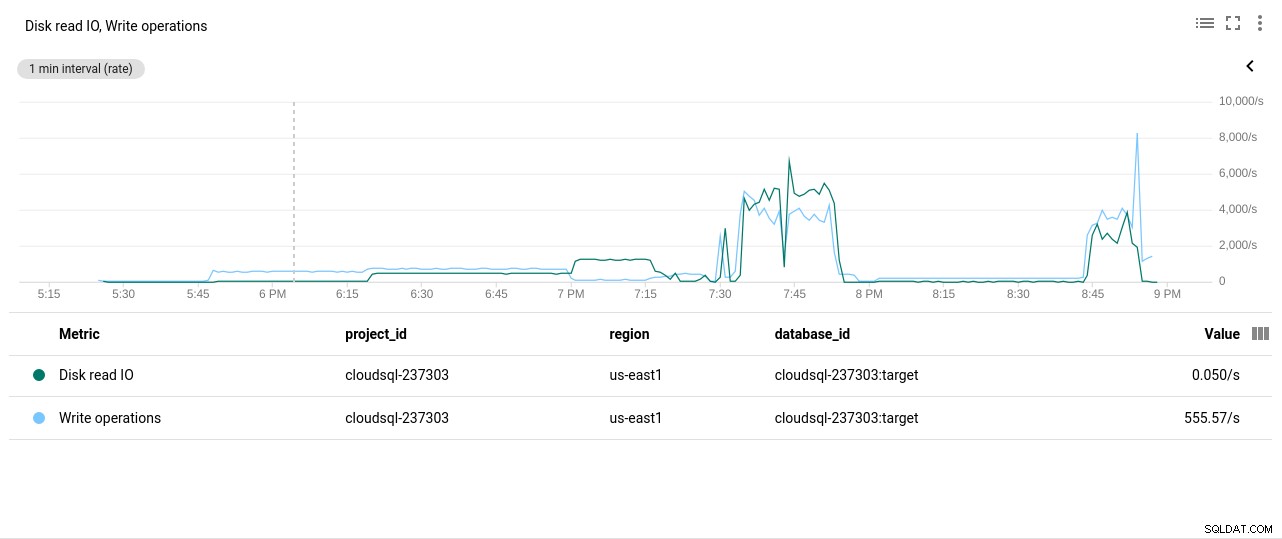 Автор на снимки Google Cloud SQL:PostgreSQL операции за четене/запис на диск
Автор на снимки Google Cloud SQL:PostgreSQL операции за четене/запис на диск - Мрежови изпратени/получени байтове:
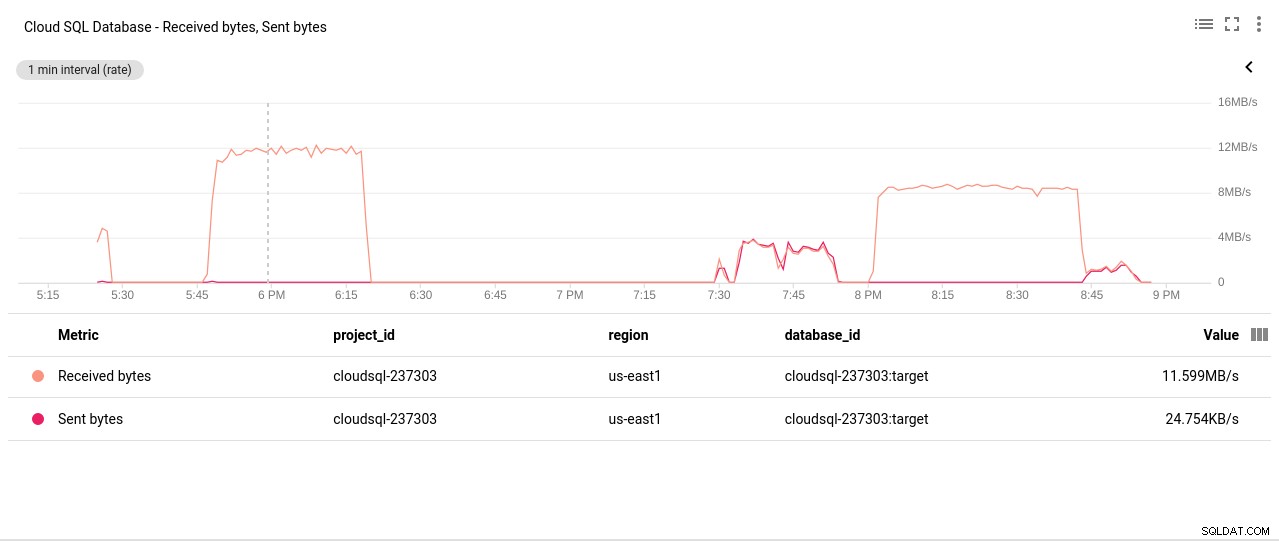 Автор на снимки Google Cloud SQL:PostgreSQL Network Sent/Received байтове
Автор на снимки Google Cloud SQL:PostgreSQL Network Sent/Received байтове - Брой връзки на PostgreSQL:
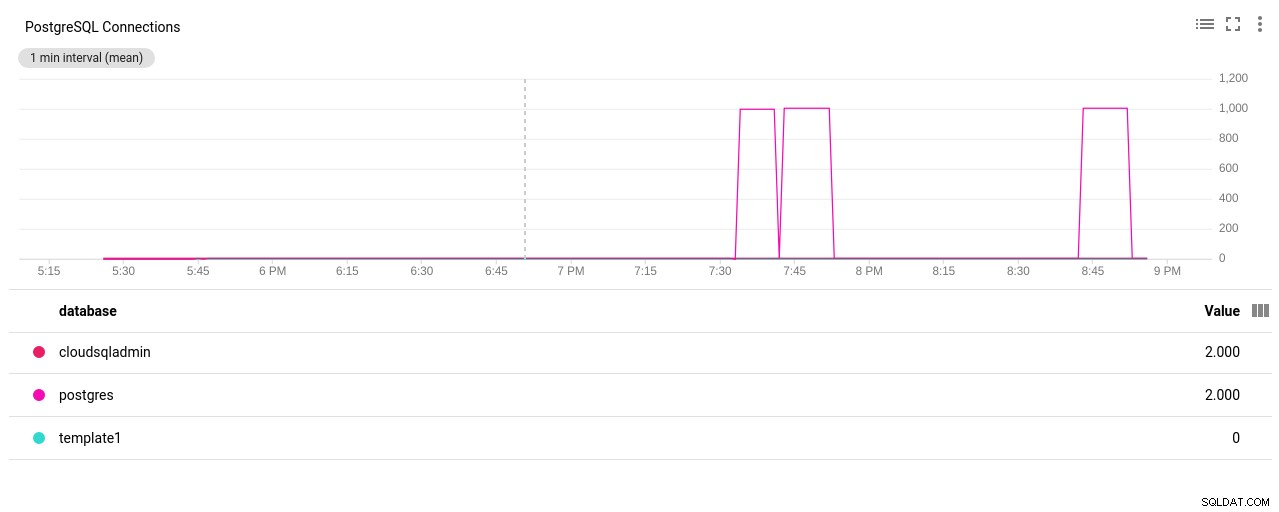 Автор на снимки Google Cloud SQL:PostgreSQL Connections Count
Автор на снимки Google Cloud SQL:PostgreSQL Connections Count
Резултати от сравнителния анализ
Инициализация на pgbench
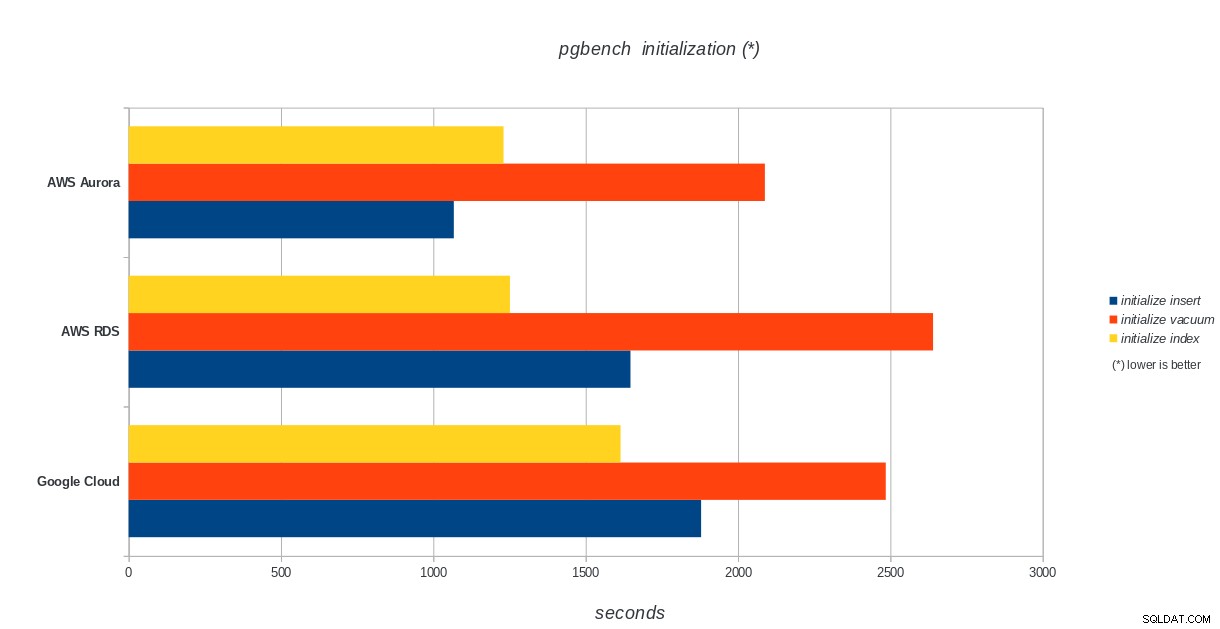 AWS Aurora, AWS RDS, Google Cloud SQL:Резултати от инициализация на PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:Резултати от инициализация на PostgreSQL pgbench pgbench run
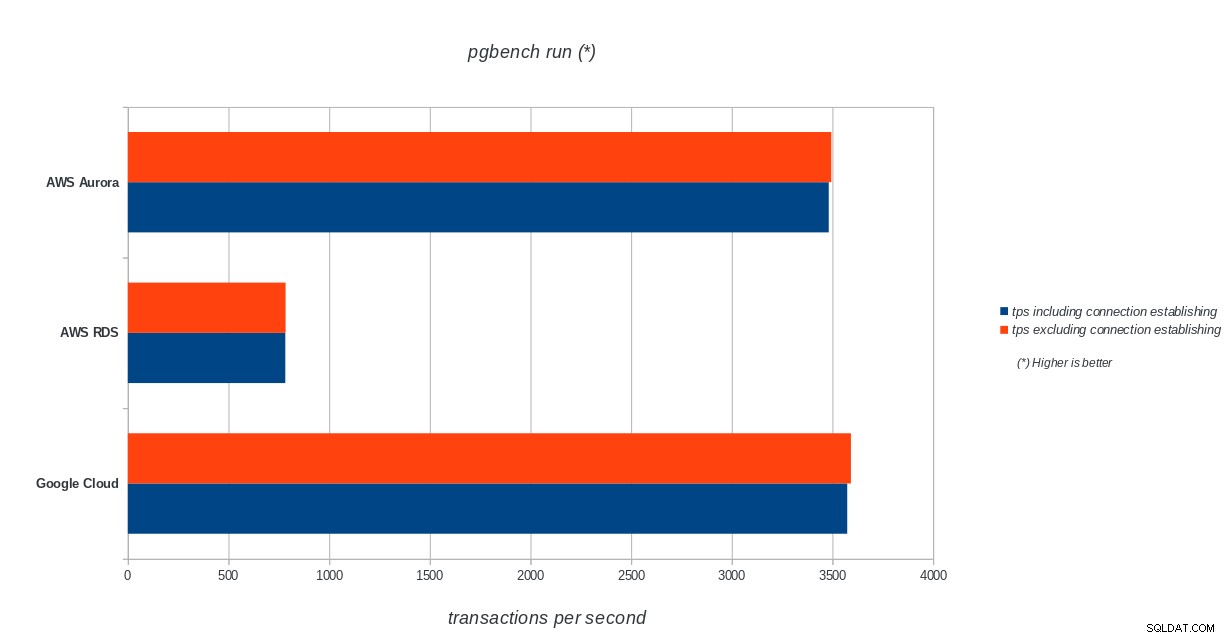 AWS Aurora, AWS RDS, Google Cloud SQL:Резултати от изпълнение на PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:Резултати от изпълнение на PostgreSQL pgbench sysbench
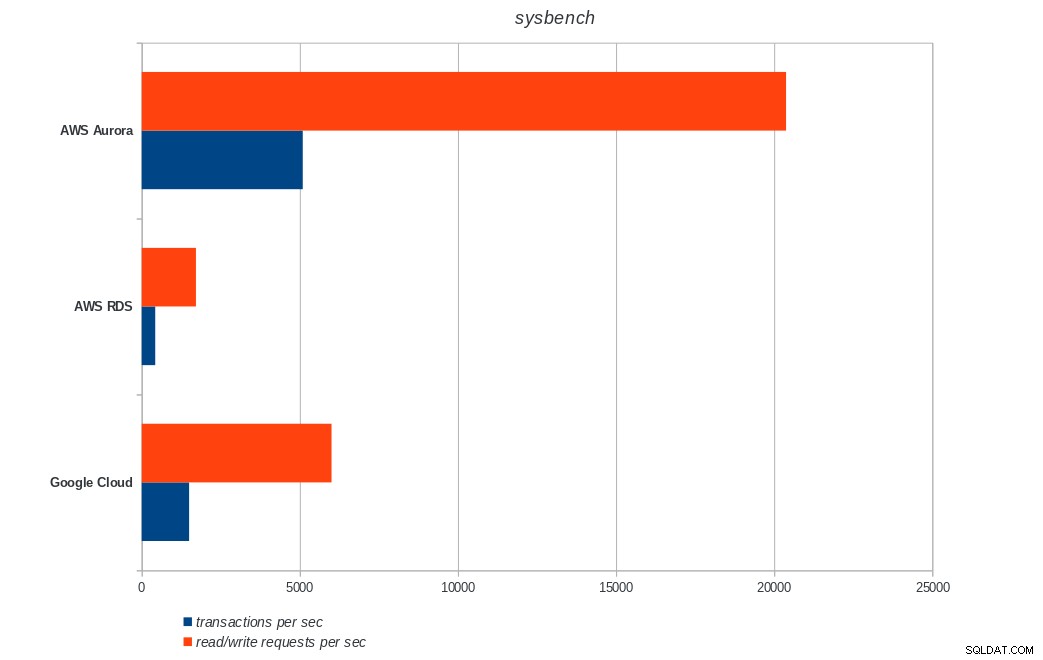 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench резултати
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench резултати Заключение
Amazon Aurora е на първо място в тежките тестове за писане (sysbench), като същевременно е наравно с Google Cloud SQL в тестовете за четене/запис на pgbench. Тестът за натоварване (инициализация на pgbench) поставя Google Cloud SQL на първо място, следван от Amazon RDS. Въз основа на бегъл поглед върху моделите на ценообразуване за AWS Aurora и Google Cloud SQL, бих се рискувал да кажа, че първоначално Google Cloud е по-добър избор за обикновения потребител, докато AWS Aurora е по-подходящ за среди с висока производителност. След завършване на всички сравнителни показатели ще последват още анализи.
Следващата и последна част от тази серия от сравнителни показатели ще бъде на Microsoft Azure PostgreSQL.
Благодаря за четенето и моля, коментирайте по-долу, ако имате обратна връзка.