Исторически погледнато, най-трудната задача при работа с PostgreSQL беше справянето с надстройките. Най-интуитивният начин за надграждане, за който можете да се сетите, е да генерирате реплика в нова версия и да извършите отказ на приложението в нея. С PostgreSQL това просто не беше възможно по естествен начин. За да постигнете надстройки, трябваше да помислите за други начини за надграждане, като например използване на pg_upgrade, изхвърляне и възстановяване или използване на някои инструменти на трети страни като Slony или Bucardo, като всички те имат свои собствени предупреждения.
Защо беше това? Поради начина, по който PostgreSQL прилага репликацията.
Вградената в PostgreSQL стрийминг репликация е това, което се нарича физическо:то ще репликира промените на ниво байт по байт, създавайки идентично копие на базата данни в друг сървър. Този метод има много ограничения, когато мислите за надграждане, тъй като просто не можете да създадете реплика в различна версия на сървъра или дори в различна архитектура.
И така, тук PostgreSQL 10 се превръща в промяна на играта. С тези нови версии 10 и 11, PostgreSQL реализира вградена логическа репликация, която, за разлика от физическата репликация, можете да репликирате между различни основни версии на PostgreSQL. Това, разбира се, отваря нова врата за надграждане на стратегии.
В този блог нека видим как можем да надстроим нашия PostgreSQL 10 до PostgreSQL 11 с нулев престой, използвайки логическа репликация. Първо, нека преминем през въведение в логическата репликация.
Какво е логическа репликация?
Логическата репликация е метод за репликиране на обекти с данни и техните промени, въз основа на тяхната идентичност на репликация (обикновено първичен ключ). Базира се на режим на публикуване и абонамент, при който един или повече абонати се абонират за една или повече публикации на възел на издател.
Публикацията е набор от промени, генерирани от таблица или група от таблици (наричани още набор за репликация). Възелът, където е дефинирана публикация, се нарича издател. Абонаментът е долната страна на логическата репликация. Възелът, където е дефиниран абонаментът, се нарича абонат и той дефинира връзката с друга база данни и набор от публикации (една или повече), за които иска да се абонира. Абонатите изтеглят данни от публикациите, за които се абонират.
Логическата репликация е изградена с архитектура, подобна на физическата поточно репликация. Реализира се чрез процеси "walsender" и "apply". Процесът на walsender стартира логическото декодиране на WAL и зарежда стандартния плъгин за логическо декодиране. Плъгинът преобразува промените, прочетени от WAL към протокола за логическа репликация и филтрира данните според спецификацията на публикацията. След това данните се прехвърлят непрекъснато с помощта на протокола за поточно репликация към работника за прилагане, който картографира данните в локални таблици и прилага отделните промени при получаването им в правилен транзакционен ред.
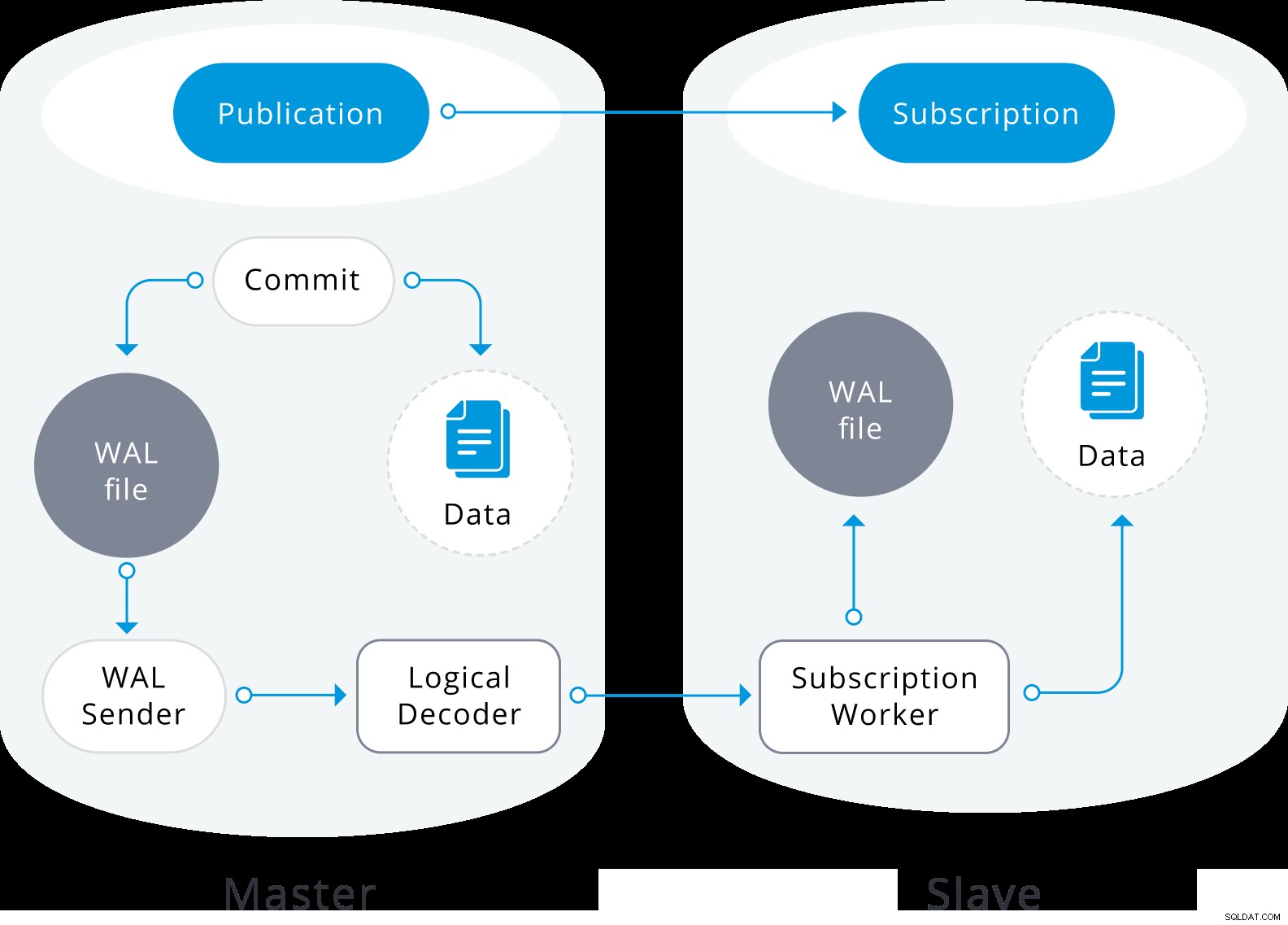 Диаграма на логическа репликация
Диаграма на логическа репликация Логическата репликация започва с правене на моментна снимка на данните в базата данни на издателя и копирането им на абоната. Първоначалните данни в съществуващите абонирани таблици се заснемат и копират в паралелен екземпляр на специален вид процес на прилагане. Този процес ще създаде свой собствен временен слот за репликация и ще копира съществуващите данни. След като съществуващите данни бъдат копирани, работникът влиза в режим на синхронизация, който гарантира, че таблицата е приведена в синхронизирано състояние с основния процес на прилагане чрез поточно предаване на всички промени, настъпили по време на първоначалното копиране на данни, като се използва стандартна логическа репликация. След като синхронизацията бъде извършена, контролът върху репликацията на таблицата се връща на основния процес на прилагане, където репликацията продължава както обикновено. Промените на издателя се изпращат на абоната, когато се извършват в реално време.
Можете да намерите повече за логическата репликация в следните блогове:
- Преглед на логическата репликация в PostgreSQL
- Поточно репликация на PostgreSQL срещу логическа репликация
Как да надстроите PostgreSQL 10 до PostgreSQL 11 с помощта на логическа репликация
И така, сега, когато знаем за какво е тази нова функция, можем да помислим как можем да я използваме, за да разрешим проблема с надстройката.
Ще конфигурираме логическа репликация между две различни основни версии на PostgreSQL (10 и 11) и разбира се, след като това работи, е само въпрос на извършване на отказ на приложение в базата данни с по-нова версия.
Ще изпълним следните стъпки, за да задействаме логическата репликация:
- Конфигуриране на възела на издателя
- Конфигуриране на абонатния възел
- Създайте абонат потребител
- Създайте публикация
- Създайте структурата на таблицата в абоната
- Създайте абонамента
- Проверете състоянието на репликация
Така че да започнем.
От страна на издателя ще конфигурираме следните параметри във файла postgresql.conf:
- listen_addresses:Какъв IP адрес(и) да слушате. Ще използваме '*' за всички.
- wal_level:Определя колко информация се записва в WAL. Ще го настроим на логично.
- max_replication_slots:Посочва максималния брой слотове за репликация, които сървърът може да поддържа. Трябва да бъде настроен поне на броя абонаменти, които се очаква да се свържат, плюс известен резерв за синхронизиране на таблицата.
- max_wal_senders:Посочва максималния брой едновременни връзки от сървъри в режим на готовност или клиенти за поточно резервно копие. Трябва да бъде настроен поне на същото като max_replication_slots плюс броя на физическите реплики, които са свързани едновременно.
Имайте предвид, че някои от тези параметри изискват рестартиране на услугата PostgreSQL, за да се приложи.
Файлът pg_hba.conf също трябва да бъде коригиран, за да позволи репликация. Трябва да позволим на потребителя за репликация да се свърже с базата данни.
Така че въз основа на това, нека конфигурираме нашия издател (в този случай нашия PostgreSQL 10 сървър) както следва:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Трябва да променим потребителя (в нашия примерен представител), който ще се използва за репликация, и IP адреса 192.168.100.144/32 за IP, който съответства на нашия PostgreSQL 11.
От страна на абоната също така изисква да бъдат зададени max_replication_slots. В този случай трябва да бъде настроен поне на броя абонаменти, които ще бъдат добавени към абоната.
Другите параметри, които също трябва да бъдат зададени тук, са:
- max_logical_replication_workers:Посочва максималния брой работници за логическа репликация. Това включва както работници за прилагане, така и работници за синхронизиране на таблици. Работниците за логическа репликация се вземат от пула, дефиниран от max_worker_processes. Трябва да бъде настроен поне на броя абонаменти, отново плюс малко резерв за синхронизиране на таблицата.
- max_worker_processes:Задава максималния брой фонови процеси, които системата може да поддържа. Може да се наложи да се коригира, за да отговаря на работниците за репликация, поне max_logical_replication_workers + 1. Този параметър изисква рестартиране на PostgreSQL.
И така, трябва да конфигурираме нашия абонат (в този случай нашия PostgreSQL 11 сървър) както следва:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Тъй като този PostgreSQL 11 скоро ще бъде нашият нов главен, трябва да помислим за добавяне на параметрите wal_level и archive_mode в тази стъпка, за да избегнем ново рестартиране на услугата по-късно.
wal_level = logical
archive_mode = onТези параметри ще бъдат полезни, ако искаме да добавим ново подчинено устройство за репликация или за използване на PITR архиви.
В издателя трябва да създадем потребителя, с който нашият абонат ще се свърже:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEРолята, използвана за връзката за репликация, трябва да има атрибут REPLICATION. Достъпът за ролята трябва да бъде конфигуриран в pg_hba.conf и трябва да има атрибута LOGIN.
За да може да се копират първоначалните данни, ролята, използвана за връзката за репликация, трябва да има привилегията SELECT в публикувана таблица.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTЩе създадем публикация pub1 в възела на издателя за всички таблици:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONПотребителят, който ще създаде публикация, трябва да има привилегията CREATE в базата данни, но за да създаде публикация, която автоматично публикува всички таблици, потребителят трябва да е суперпотребител.
За да потвърдим създадената публикация, ще използваме каталога pg_publication. Този каталог съдържа информация за всички публикации, създадени в базата данни.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tОписания на колони:
- име на публикация:Име на публикацията.
- pubowner:Собственик на публикацията.
- puballtables:Ако е истина, тази публикация автоматично включва всички таблици в базата данни, включително всички, които ще бъдат създадени в бъдеще.
- pubinsert:Ако е вярно, операциите INSERT се репликират за таблици в публикацията.
- pubupdate:Ако е вярно, операциите UPDATE се репликират за таблици в публикацията.
- pubdelete:Ако е вярно, операциите DELETE се репликират за таблиците в публикацията.
Тъй като схемата не се репликира, трябва да направим резервно копие в PostgreSQL 10 и да го възстановим в нашия PostgreSQL 11. Архивът ще бъде взет само за схемата, тъй като информацията ще бъде репликирана при първоначалното прехвърляне.
В PostgreSQL 10:
$ pg_dumpall -s > schema.sqlВ PostgreSQL 11:
$ psql -d postgres -f schema.sqlСлед като имаме нашата схема в PostgreSQL 11, създаваме абонамента, като заменяме стойностите на хост, dbname, потребител и парола с тези, които съответстват на нашата среда.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONГорното ще стартира процеса на репликация, който синхронизира първоначалното съдържание на таблицата на таблиците в публикацията и след това започва да репликира постепенни промени в тези таблици.
Потребителят, създаващ абонамент, трябва да бъде суперпотребител. Процесът на прилагане на абонамента ще се изпълнява в локалната база данни с привилегиите на суперпотребител.
За да проверим създадения абонамент, можем да използваме следния каталог pg_stat_subscription. Този изглед ще съдържа по един ред на абонамент за основния работник (с нулев PID, ако работникът не работи) и допълнителни редове за работници, обработващи първоначалното копие на данни на абонираните таблици.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Описания на колони:
- subid:OID на абонамента.
- подиме:Име на абонамента.
- pid:Идентификатор на процес на работния процес на абонамента.
- relid:OID на връзката, която работникът синхронизира; null за основния работник за прилагане.
- received_lsn:Последно получено местоположение на дневника за предварителна запис, като първоначалната стойност на това поле е 0.
- last_msg_send_time:Време за изпращане на последното съобщение, получено от източника на WAL подателя.
- last_msg_receipt_time:Час на получаване на последното съобщение, получено от източника на подателя на WAL.
- latest_end_lsn:Последното местоположение на дневника за предсрочно записване, съобщено на източника на WAL подателя.
- latest_end_time:Времето на последното местоположение на дневника с предварителна запис, съобщено на източника на WAL подателя.
За да проверим състоянието на репликацията в главния, можем да използваме pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncОписания на колони:
- pid:Идентификатор на процес на процес на изпращач на WAL.
- usesysid:OID на потребителя, влязъл в този процес на изпращач на WAL.
- usename:Име на потребителя, влязъл в този процес на изпращач на WAL.
- application_name:Име на приложението, което е свързано с този подател на WAL.
- client_addr:IP адрес на клиента, свързан с този подател на WAL. Ако това поле е нула, това показва, че клиентът е свързан чрез Unix сокет на сървърната машина.
- client_hostname:име на хост на свързания клиент, както е отчетено от обратно DNS търсене на client_addr. Това поле ще бъде ненулево само за IP връзки и само когато log_hostname е активирано.
- client_port:Номер на TCP порт, който клиентът използва за комуникация с този подател на WAL, или -1, ако се използва Unix сокет.
- backend_start:Времето, когато този процес е стартиран.
- backend_xmin:Xmin хоризонтът на този режим на готовност, докладван от hot_standby_feedback.
- състояние:Текущо състояние на изпращача на WAL. Възможните стойности са:startup, catchup, streaming, backup и stop.
- sent_lsn:Последното местоположение на дневника с предварителна запис, изпратено на тази връзка.
- write_lsn:Последно местоположение на дневника за предсрочно записване, записано на диск от този сървър в режим на готовност.
- flush_lsn:Последното местоположение на дневника с предварителна запис, изхвърлено на диск от този резервен сървър.
- replay_lsn:Последното местоположение на регистрационния файл с предварителна запис, възпроизведено в базата данни на този резервен сървър.
- write_lag:Време, изминало между локалното изчистване на скорошния WAL и получаването на известие, че този сървър в режим на готовност го е записал (но все още не го е прочистил или приложил).
- flush_lag:Времето, изминало между локалното изчистване на скорошния WAL и получаването на известие, че този сървър в режим на готовност го е написал и прочистил (но все още не го е приложил).
- replay_lag:Време, изминало между локалното изчистване на скорошния WAL и получаването на известие, че този сървър в режим на готовност го е написал, прочистил и приложил.
- sync_priority:Приоритет на този резервен сървър да бъде избран като синхронен режим на готовност в базирана на приоритет синхронна репликация.
- sync_state:Синхронно състояние на този сървър в режим на готовност. Възможните стойности са async, potencijal, sync, quorum.
За да проверим кога първоначалният трансфер е завършен, можем да видим дневника на PostgreSQL на абоната:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedИли проверка на променливата srsubstate в каталога pg_subscription_rel. Този каталог съдържа състоянието за всяка репликирана връзка във всеки абонамент.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Описания на колони:
- srsubid:Препратка към абонамента.
- srrelid:Препратка към релация.
- srsubstate:Код на състоянието:i =инициализира се, d =данните се копират, s =синхронизирани, r =готов (нормална репликация).
- srsublsn:Край на LSN за s и r състояния.
Можем да вмъкнем някои тестови записи в нашия PostgreSQL 10 и да потвърдим, че ги имаме в нашия PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)В този момент имаме всичко готово, за да насочим нашето приложение към нашия PostgreSQL 11.
За това, първо, трябва да потвърдим, че нямаме забавяне на репликацията.
На главния:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0И сега трябва само да променим нашата крайна точка от нашето приложение или балансьор на натоварване (ако имаме такъв) към новия сървър PostgreSQL 11.
Ако имаме балансьор на натоварване като HAProxy, можем да го конфигурираме, използвайки PostgreSQL 10 като активен и PostgreSQL 11 като резервно копие, по този начин:
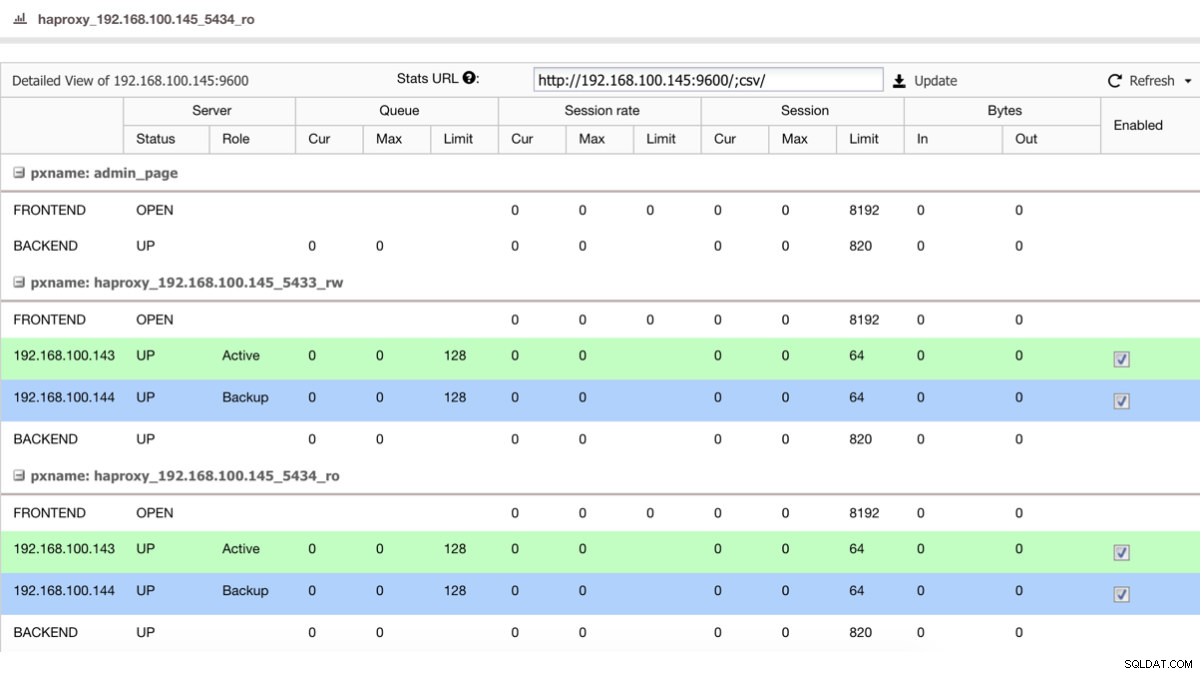 Преглед на състоянието на HAProxy
Преглед на състоянието на HAProxy Така че, ако просто изключите главния в PostgreSQL 10, резервният сървър, в този случай в PostgreSQL 11, започва да получава трафика по прозрачен начин за потребителя/приложението.
В края на миграцията можем да изтрием абонамента в нашия нов главен файл в PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONИ проверете дали е премахнат правилно:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Ограничения
Преди да използвате логическата репликация, моля, имайте предвид следните ограничения:
- Схемата на базата данни и DDL командите не се репликират. Първоначалната схема може да бъде копирана с помощта на pg_dump --schema-only.
- Данните за последователността не се репликират. Данните в колони за последователност или идентичност, подкрепени от последователности, ще бъдат репликирани като част от таблицата, но самата последователност все още ще показва началната стойност на абоната.
- Поддържа се репликация на команди TRUNCATE, но трябва да се внимава при съкращаването на групи от таблици, свързани с външни ключове. Когато репликира действие за съкращаване, абонатът ще съкрати същата група от таблици, която е била съкратена на издателя, или изрично посочена, или имплицитно събрана чрез CASCADE, минус таблици, които не са част от абонамента. Това ще работи правилно, ако всички засегнати таблици са част от един и същ абонамент. Но ако някои таблици, които трябва да бъдат съкратени на абоната, имат връзки с външен ключ към таблици, които не са част от същия (или какъвто и да е) абонамент, тогава прилагането на действието за съкращаване към абоната няма да бъде успешно.
- Големи обекти не се репликират. Няма заобиколно решение за това, освен съхраняване на данни в нормални таблици.
- Репликацията е възможна само от базови таблици към основни таблици. Тоест таблиците в публикацията и от страната на абонамента трябва да бъдат нормални таблици, а не изгледи, материализирани изгледи, основни таблици на дялове или чужди таблици. В случай на дялове, можете да репликирате йерархия на дялове едно към едно, но понастоящем не можете да репликирате към различно разделена настройка.
Заключение
Поддържането на вашия PostgreSQL сървър актуален чрез извършване на редовни надстройки беше необходима, но трудна задача до версията на PostgreSQL 10.
В този блог направихме кратко въведение в логическата репликация, функция на PostgreSQL, въведена първоначално във версия 10, и ви показахме как може да ви помогне да постигнете това предизвикателство със стратегия за нулев престой.