Мониторингът е една от основните задачи във всяка система. Може да ни помогне да открием проблеми и да предприемем действия или просто да знаем текущото състояние на нашите системи. Използването на визуални дисплеи може да ни направи по-ефективни, тъй като можем по-лесно да откриваме проблеми с производителността.
В този блог ще видим как да използваме SCUMM за наблюдение на нашите PostgreSQL бази данни и какви показатели можем да използваме за тази задача. Ще разгледаме и наличните табла за управление, за да можете лесно да разберете какво наистина се случва с вашите PostgreSQL екземпляри.
Какво е SCUMM?
На първо място, нека видим какво е SCUMM (Unified Monitoring and Management Severalnines ClusterControl).
Това е ново базирано на агенти решение с агенти, инсталирани на възлите на базата данни.
Агентите на SCUMM са износители на Prometheus, които експортират показатели от услуги като PostgreSQL като метрики на Prometheus.
Сървър на Prometheus се използва за извличане и съхраняване на данни от времеви серии от агентите на SCUMM.
Prometheus е инструментариум за мониторинг и предупреждение с отворен код, първоначално създаден в SoundCloud. Вече е самостоятелен проект с отворен код и се поддържа независимо.
Prometheus е проектиран за надеждност, за да бъде системата, към която отивате по време на прекъсване, за да ви позволи бързо да диагностицирате проблеми.
Как да използвам SCUMM?
Когато използваме ClusterControl, когато избираме клъстер, можем да видим преглед на нашите бази данни, както и някои основни показатели, които могат да се използват за идентифициране на проблем. В таблото за управление по-долу можем да видим настройка главен-подчинен с един главен и 2 подчинени, с HAProxy и Keepalived.
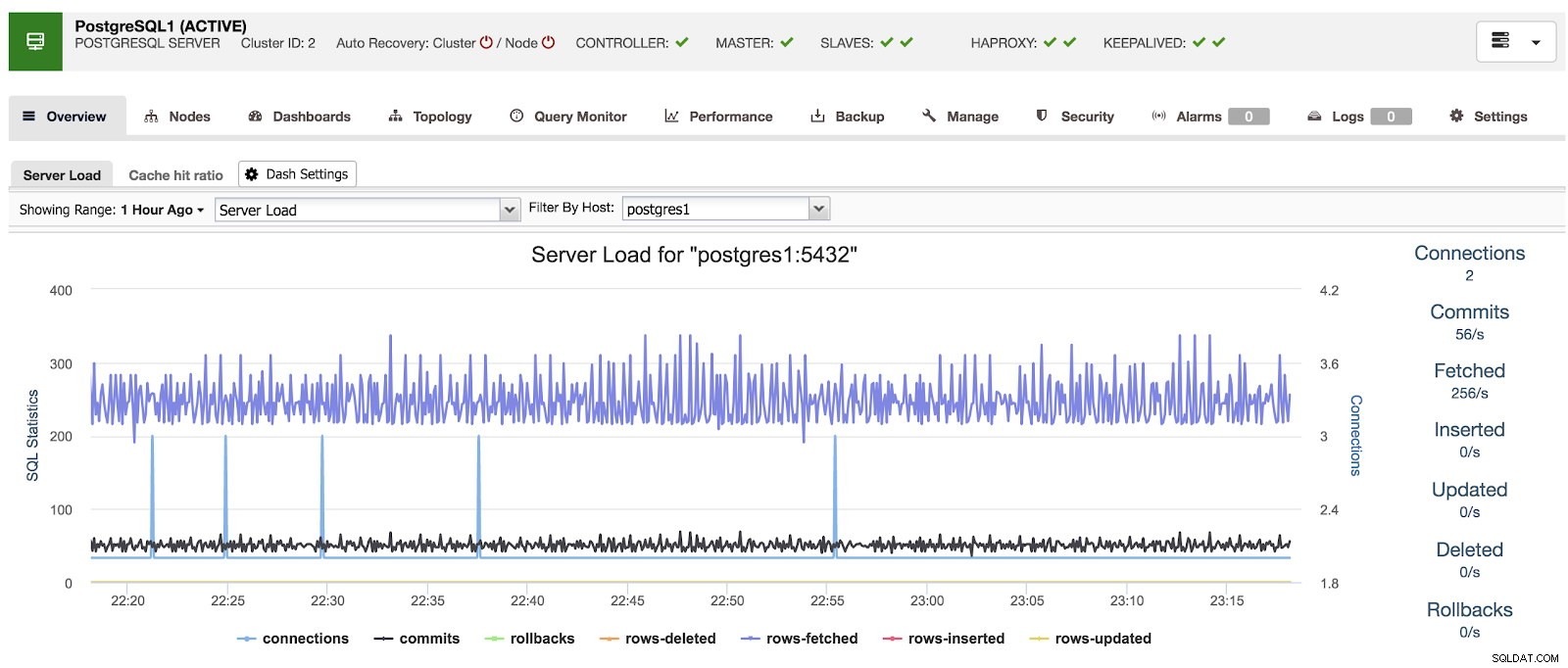 Преглед на ClusterControl
Преглед на ClusterControl Ако отидем на опцията „Табла за управление“, можем да видим съобщение като следното.
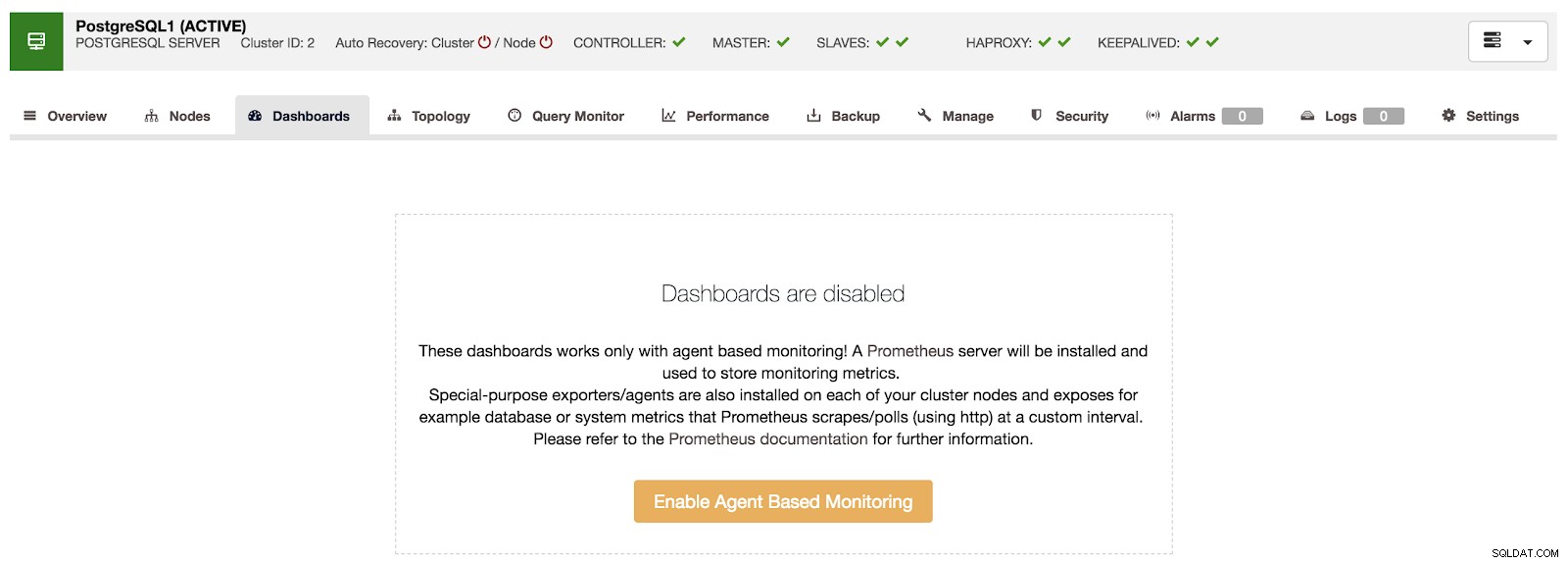 Таблата за управление на ClusterControl са деактивирани
Таблата за управление на ClusterControl са деактивирани За да използваме тази функция, трябва да активираме агента, споменат по-горе. За целта трябва само да натиснете бутона „Активиране на мониторинг, базиран на агенти“ в този раздел.
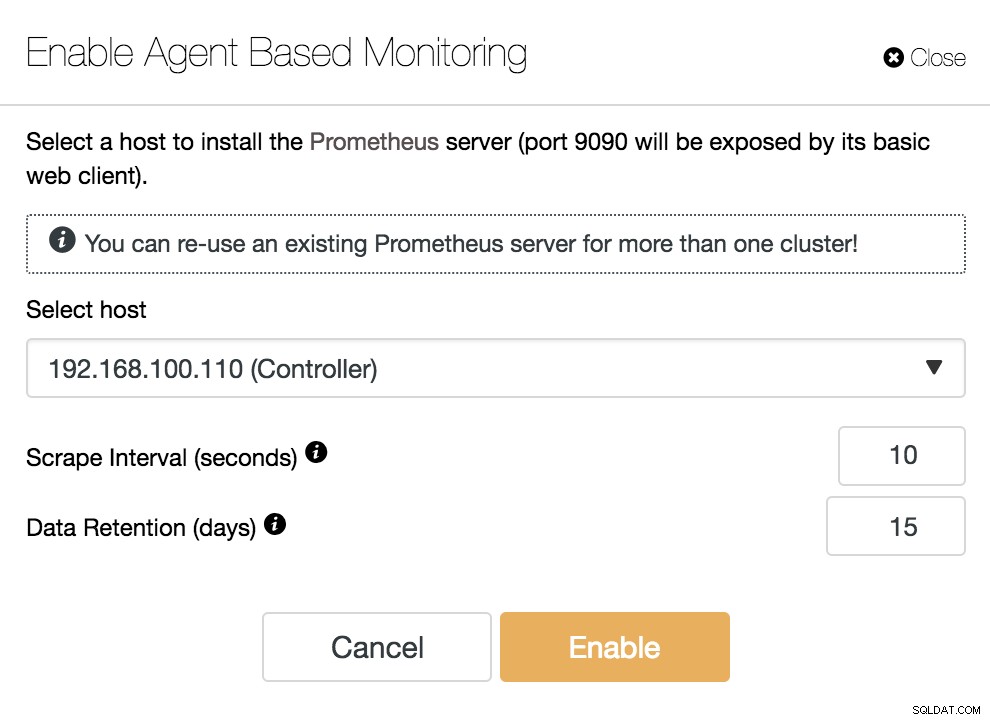 ClusterControl Активиране на мониторинг, базиран на агент
ClusterControl Активиране на мониторинг, базиран на агент За да активираме нашия агент, трябва да посочим хоста, където ще инсталираме нашия сървър Prometheus, който, както виждаме в примера, може да бъде нашия ClusterControl сървър.
Трябва също да посочим:
- Интервал за изстъргване (секунди):Задайте колко често възлите да се изстъргват за показатели. По подразбиране е 10 секунди.
- Запазване на данни (дни):Задайте колко време се съхраняват показателите, преди да бъдат премахнати. По подразбиране е 15 дни.
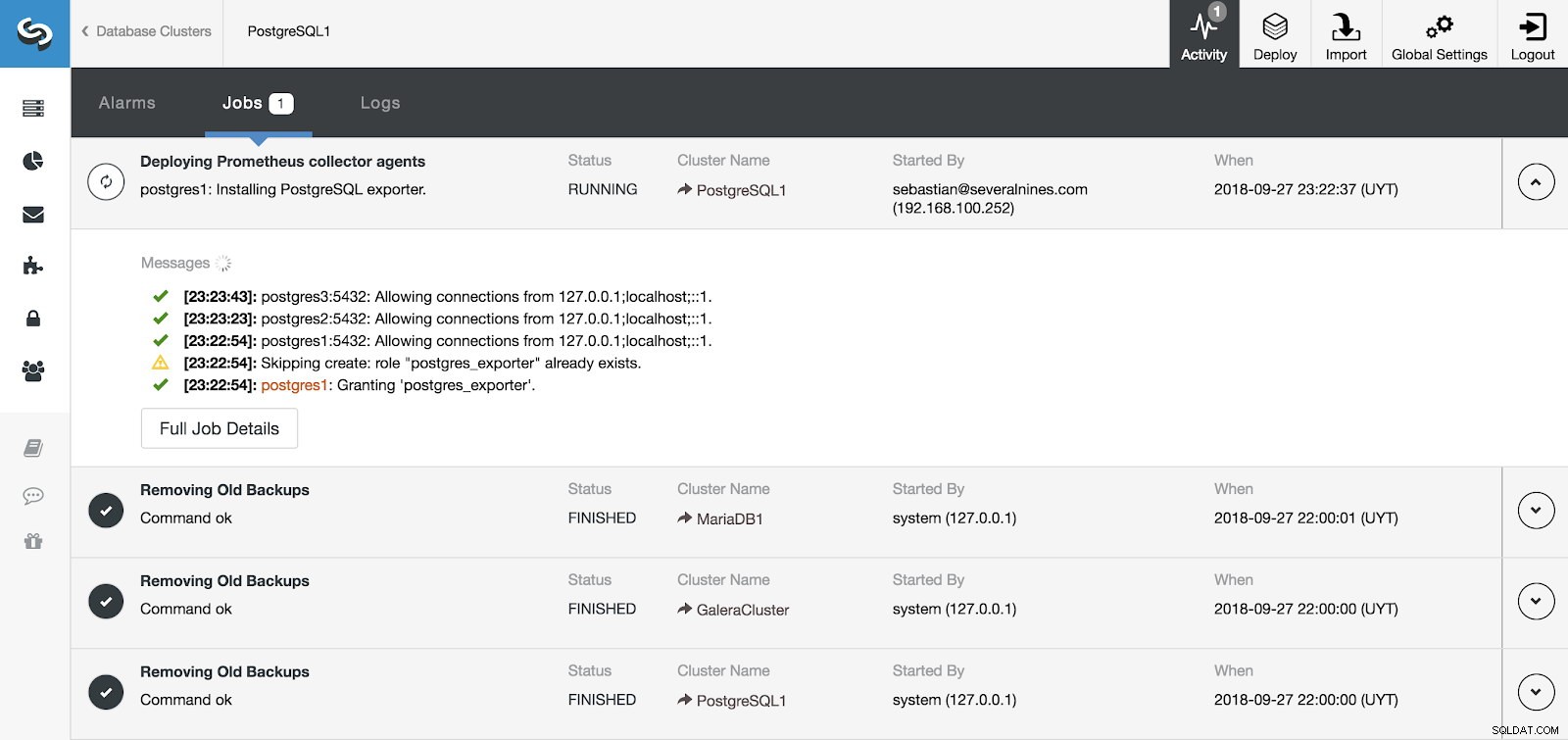 Раздел за активност на ClusterControl
Раздел за активност на ClusterControl Можем да наблюдаваме инсталирането на нашия сървър и агенти от секцията за активност в ClusterControl и след като приключи, можем да видим нашия клъстер с активирани агенти от главния екран на ClusterControl.
 Агентите на ClusterControl са активирани
Агентите на ClusterControl са активирани Табла за управление
Ако нашите агенти са активирани, ако отидем в секцията Табла за управление, ще видим нещо подобно:
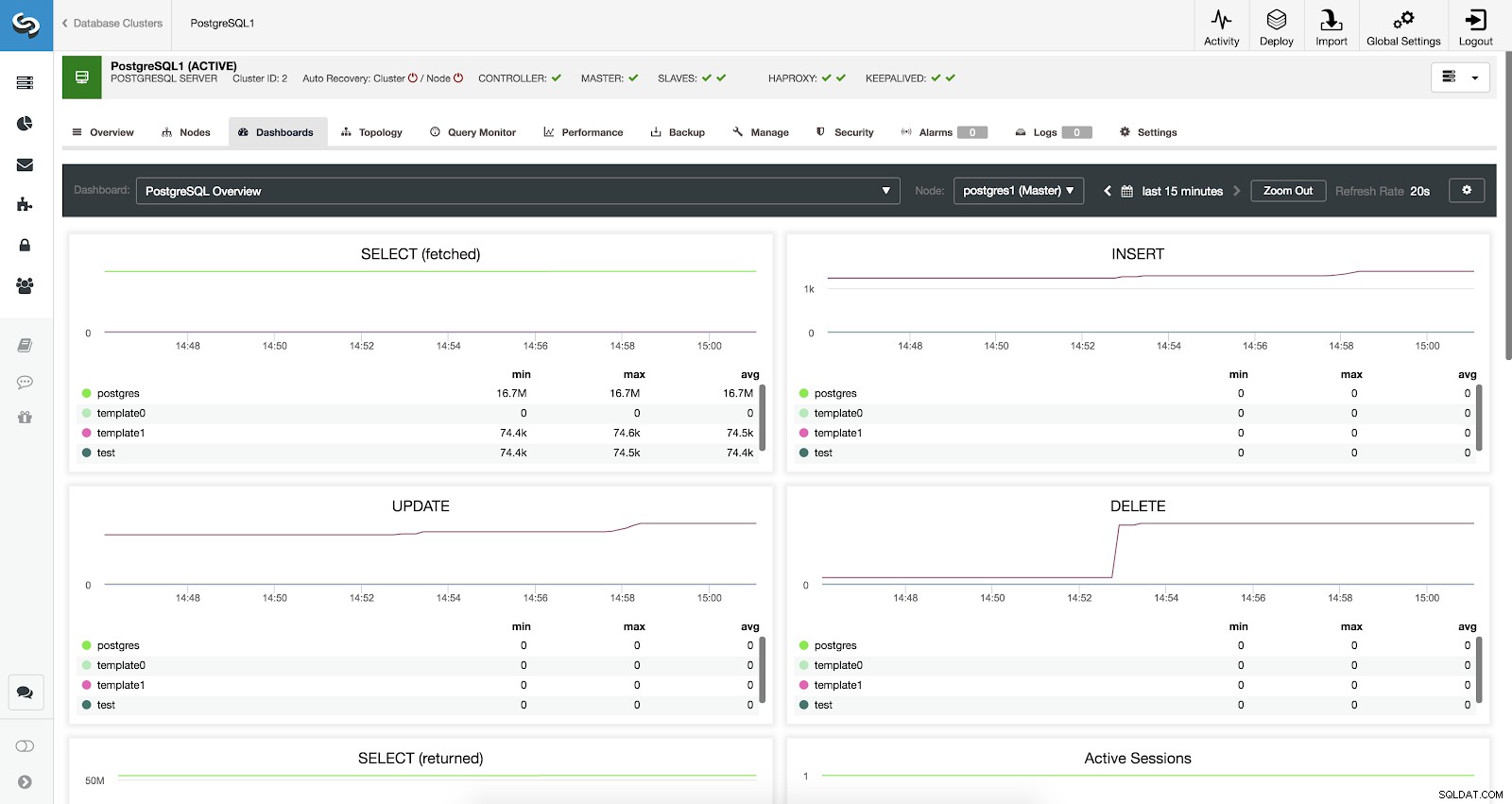 Активирани табла за управление на ClusterControl
Активирани табла за управление на ClusterControl Имаме налични три различни вида табла за управление, преглед на системата, кръстосани сървърни графики и преглед на PostgreSQL. Последното е това, което виждаме по подразбиране, когато влизаме в този раздел.
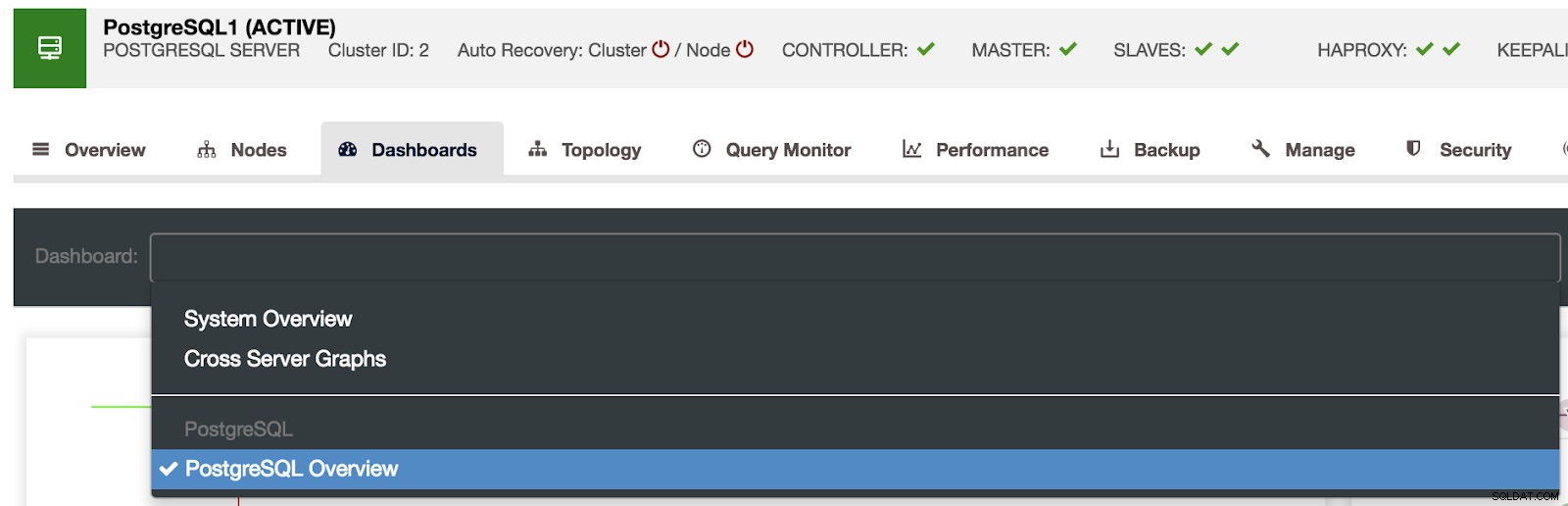 Избор на табла за управление на ClusterControl
Избор на табла за управление на ClusterControl Тук можем също да посочим кой възел да наблюдаваме, времевия диапазон и честотата на опресняване.
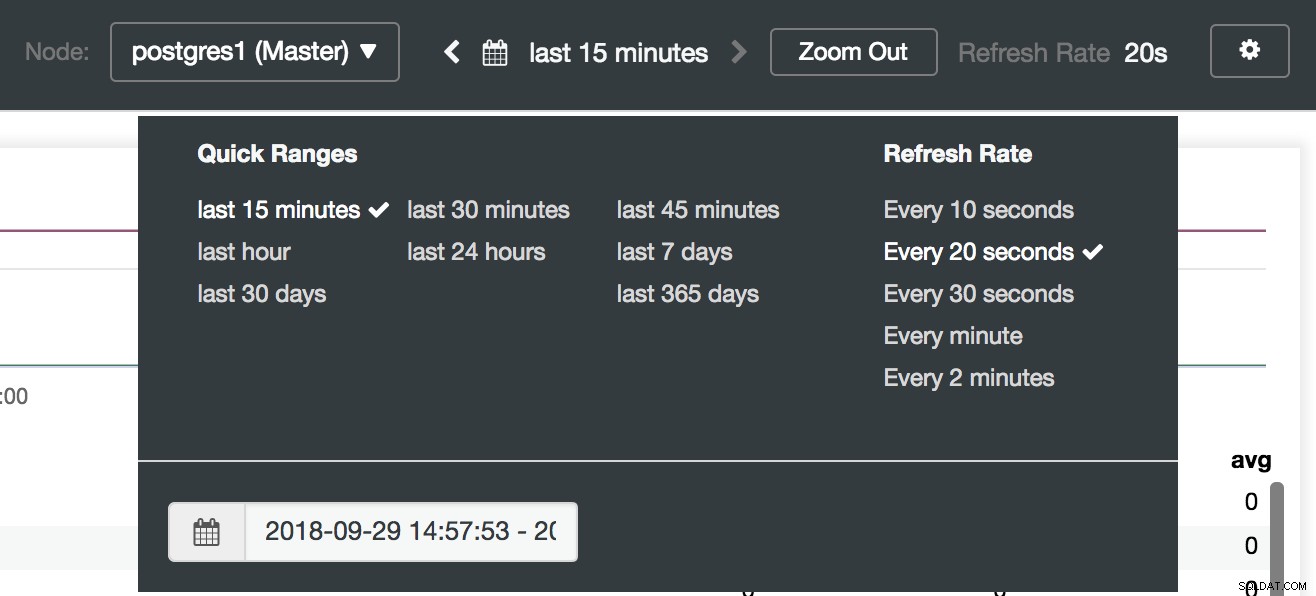 Опции на таблото за управление на ClusterControl
Опции на таблото за управление на ClusterControl В секцията за конфигурация можем да активираме или деактивираме нашите агенти (експортери), да проверим състоянието на агентите и да проверим версията на нашия сървър Prometheus.
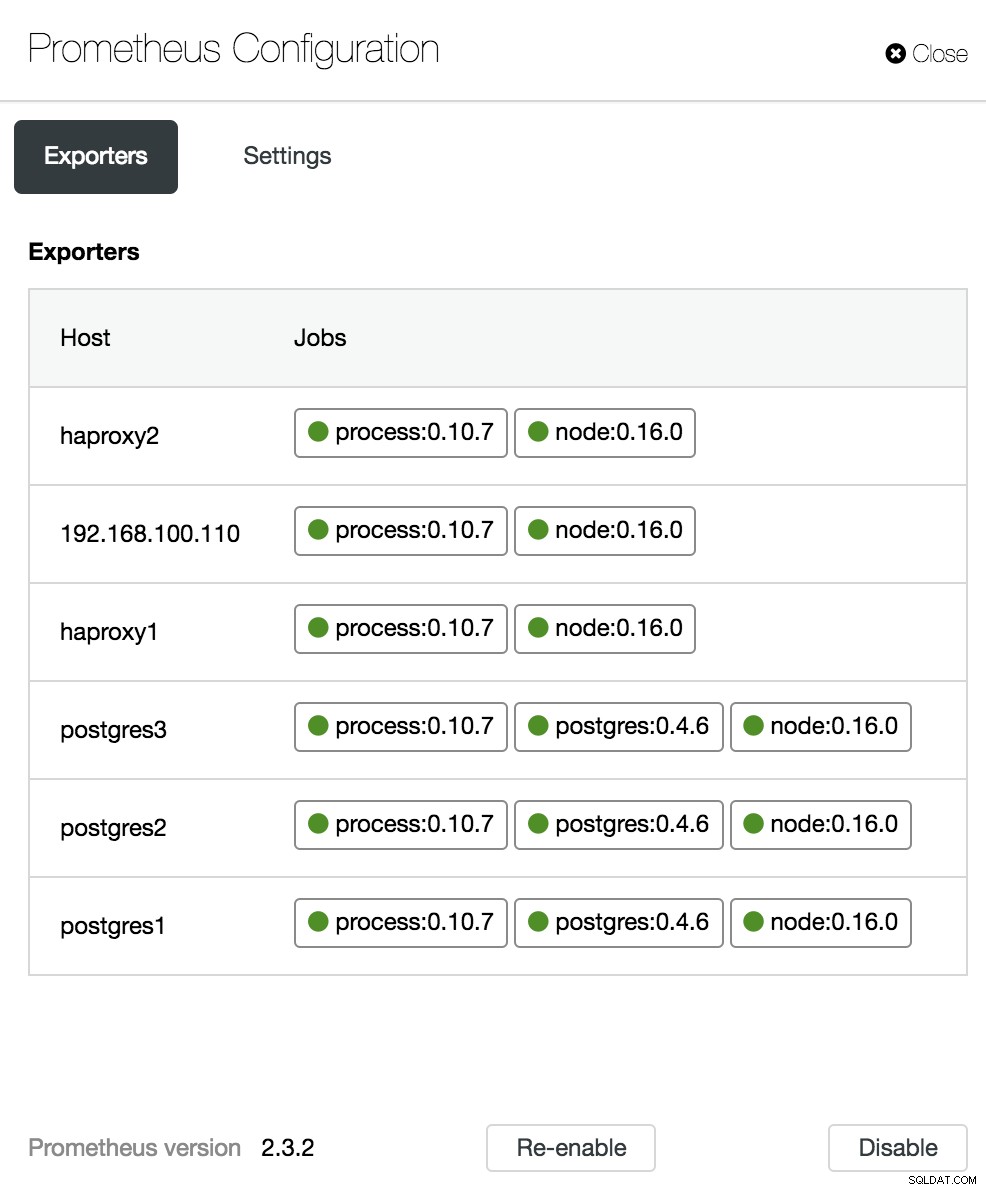 Конфигурация на таблото за управление на ClusterControl
Конфигурация на таблото за управление на ClusterControl Показатели за общ преглед на PostgreSQL
Нека видим сега какви показатели разполагаме за всяка една от нашите PostgreSQL бази данни (всички за избрания възел).
- ИЗБИРАНЕ (извлечено):Количество избрани (извлечени) редове за всяка база данни. Извлечените редове се отнасят до живи редове, извлечени от таблицата.
- ИЗБИРАНЕ (Върнато):Количество избрани (върнати) редове за всяка база данни. Върнатите редове се отнасят до всички редове, прочетени от таблицата, която включва мъртви редове и все още неангажирани редове (за разлика от извлечените редове, които отчитат само живите кортежи).
- INSERT:Брой редове, вмъкнати за всяка база данни.
- АКТУАЛИЗИРАНЕ:Брой редове, актуализирани за всяка база данни.
- ИЗТРИВАНЕ:Количество изтрити редове за всяка база данни.
- Активни сесии:Брой активни сесии (мин., макс. и среден) за всяка база данни.
- Неактивни сесии:Брой неактивни сесии (мин., макс. и средно) за всяка база данни.
- Таблици за заключване:Количество заключвания (мин., макс. и средно), разделени по тип за всяка база данни.
- Използване на IO на диск:Използване на IO на диск на сървъра.
- Използване на диск:Процент на използване на диск на сървъра (мин., макс. и среден).
- Закъснение на диска:Закъснение на диска на сървъра.
Общ преглед на ClusterControl PostgreSQL Показатели за общ преглед на системата
За да наблюдаваме нашата система, имаме налични за всеки сървър следните показатели (всички за избрания възел):
- System Uptime:Време, откакто сървърът работи.
- CPU:Количество CPU.
- RAM:Количество RAM памет.
- Налична памет:Процент налична RAM памет.
- Средно зареждане:Мин., максимално и средно натоварване на сървъра.
- Памет:Налична, обща и използвана памет на сървъра.
- Използване на CPU:Информация за минимална, максимална и средна употреба на CPU на сървъра.
- Разпределение на паметта:Разпределение на паметта (буфер, кеш, свободна и използвана) на избрания възел.
- Показатели за насищане:Минимално, максимално и средно на натоварването на IO и CPU на избрания възел.
- Разширени подробности за паметта:Подробности за използването на паметта, като страници, буфер и други, на избрания възел.
- Разклонения:Брой процеси на разклонения. Разклонението е операция, при която процесът създава собствено копие. Обикновено това е системно извикване, реализирано в ядрото.
- Процеси:Брой процеси, които се изпълняват или чакат в операционната система.
- Превключватели на контекст:Превключвателят на контекста е действието за съхраняване на състоянието на процес или на нишка.
- Прекъсвания:Количество прекъсвания. Прекъсването е събитие, което променя нормалния поток на изпълнение на програма и може да бъде генерирано от хардуерни устройства или дори от самия процесор.
- Мрежов трафик:Входящ и изходящ мрежов трафик в KBytes в секунда на избрания възел.
- Използване на мрежата на час:Изпратен и получен трафик през последния ден.
- Размяна:Размяна на използване (безплатно и използвано) на избрания възел.
- Дейност при размяна:Чете и записва данни при размяна.
- Входно-изходна дейност:Влизане и излизане на страница на IO.
- Файлови дескриптори:Разпределени и ограничени файлови дескриптори.
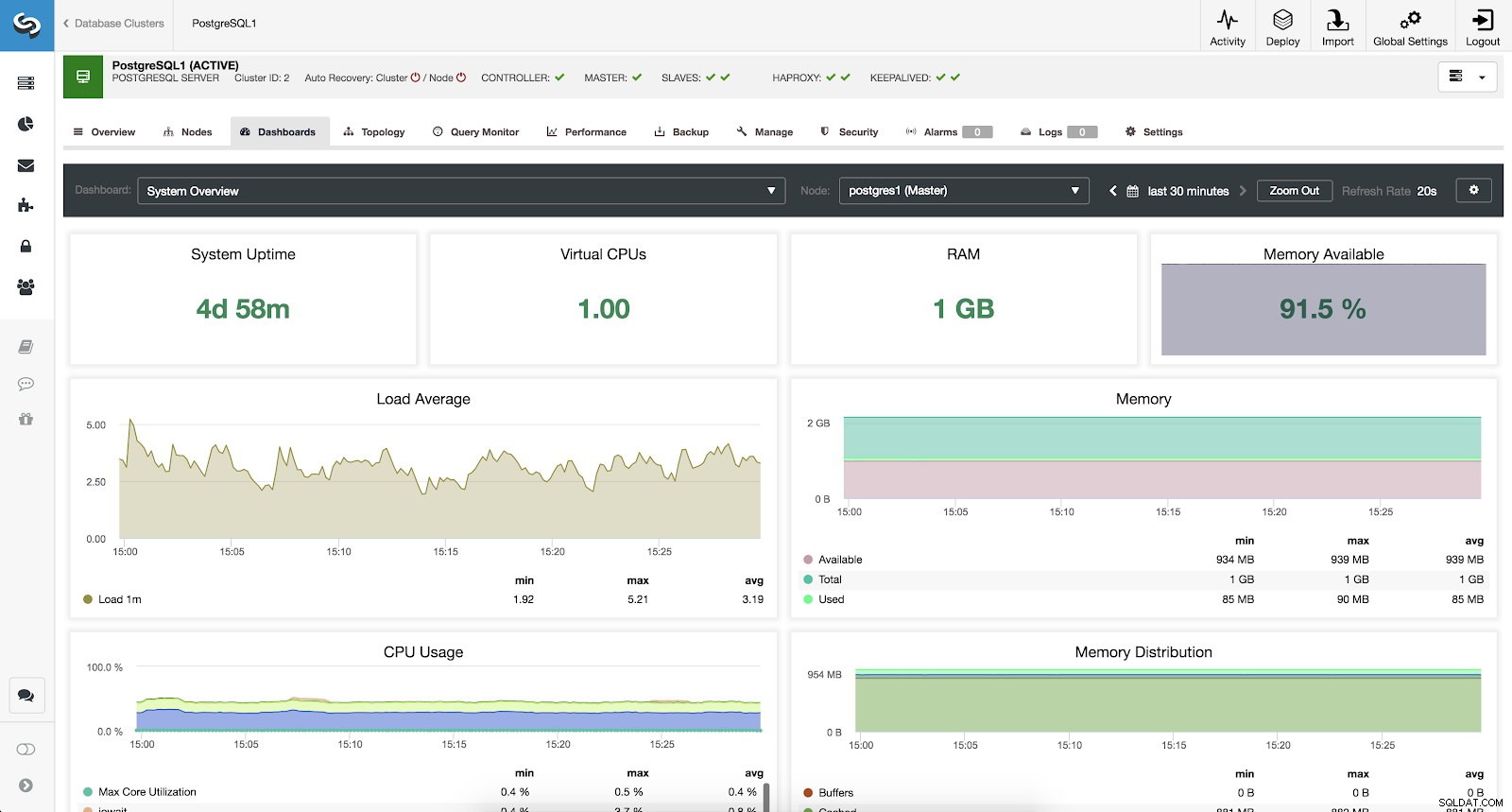 Показатели за преглед на системата ClusterControl
Показатели за преглед на системата ClusterControl Показатели за кръстосани сървърни графики
Ако искаме да видим общото състояние на всички наши сървъри, можем да използваме това табло със следните показатели:
- Средно зареждане:Сървърите зареждат средно за всеки сървър.
- Използване на паметта:Процент на използване на паметта за всеки сървър.
- Мрежов трафик:Минимален, максимален и среден килобайт мрежов трафик в секунда.
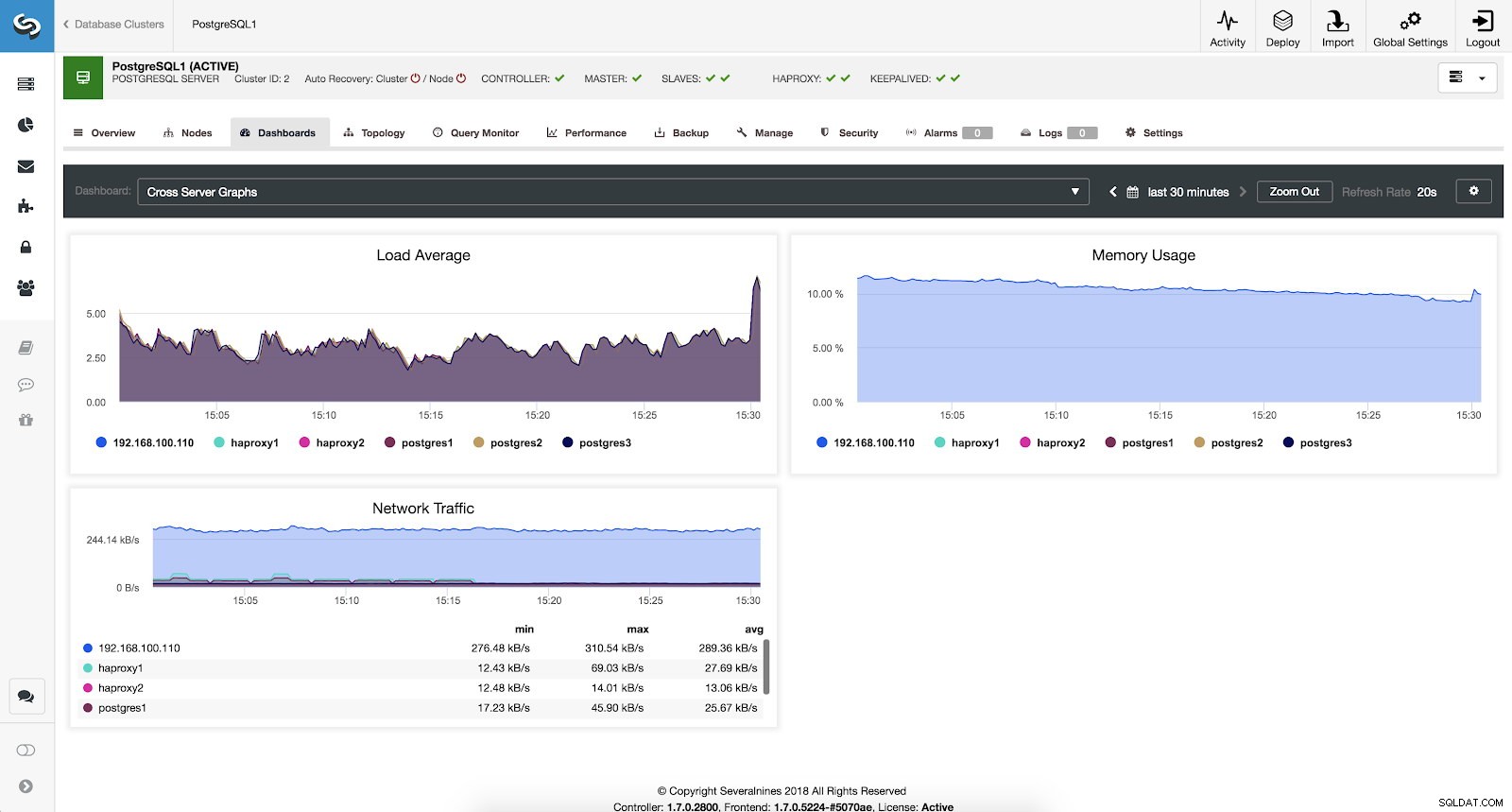 ClusterControl Cross Server Graphs Metrics
ClusterControl Cross Server Graphs Metrics Заключение
Има няколко начина за наблюдение на PostgreSQL. ClusterControl осигурява мониторинг без агенти и сега базиран на агенти чрез Prometheus. Той предоставя данни за мониторинг с по-висока разделителна способност, както и различни табла за управление, за да се разбере производителността на базата данни. ClusterControl може също да се интегрира с външни инструменти като Slack или PagerDuty за предупреждение.