Работейки в ИТ индустрията, вероятно сме чували думата „failover“ много пъти, но тя може също да повдигне въпроси като:Какво всъщност е отказ? За какво можем да го използваме? Важно ли е да го има? Как можем да го направим?
Въпреки че може да изглеждат доста основни въпроси, важно е да ги вземете предвид във всяка среда на база данни. И по-често не се съобразяваме с основните неща...
За да започнем, нека разгледаме някои основни понятия.
Какво е Failover?
Отказът е способността на системата да продължи да функционира, дори ако възникне някаква повреда. Това предполага, че функциите на системата се поемат от вторични компоненти, ако основните компоненти се повредят.
В случая с PostgreSQL има различни инструменти, които ви позволяват да внедрите клъстер от база данни, който е устойчив на неуспехи. Един механизъм за резервиране, наличен в PostgreSQL, е репликацията. И новостта в PostgreSQL 10 е внедряването на логическа репликация.
Какво е репликация?
Това е процес на копиране и поддържане на данните актуализирани в един или повече възли на базата данни. Той използва концепция за главен възел, който получава модификациите, и подчинени възли, където те се репликират.
Имаме няколко начина за категоризиране на репликацията:
- Синхронна репликация:Няма загуба на данни, дори ако нашият главен възел е загубен, но комитациите в главния трябва да изчакат потвърждение от подчинения, което може да повлияе на производителността.
- Асинхронна репликация:Има възможност за загуба на данни в случай, че загубим нашия главен възел. Ако репликата по някаква причина не бъде актуализирана по време на инцидента, информацията, която не е копирана, може да бъде загубена.
- Физическа репликация:Дисковите блокове се копират.
- Логическа репликация:Поточно предаване на промените в данните.
- Подчинени устройства с топъл режим на готовност:Те не поддържат връзки.
- Горещи резервни подчинени устройства:Поддържат връзки само за четене, полезни за отчети или заявки.
За какво се използва Failover?
Има няколко възможни приложения на отказ. Нека видим някои примери.
Миграция
Ако искаме да мигрираме от един център за данни към друг, като минимизираме времето за престой, можем да използваме отказ.
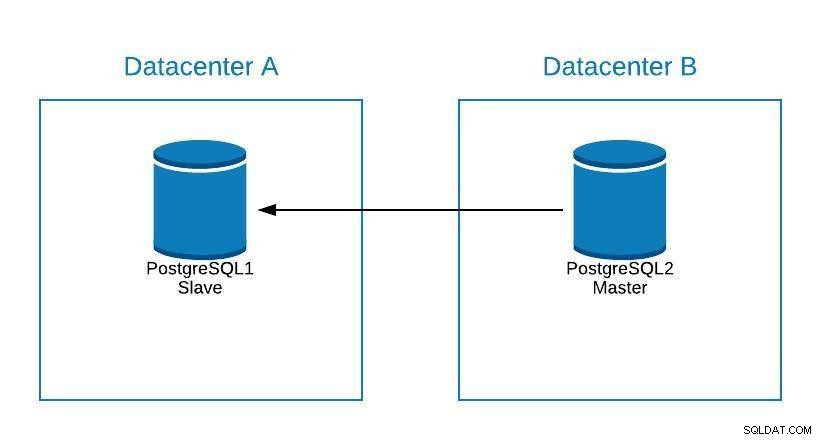
Да предположим, че нашият господар е в център за данни A и искаме да мигрираме нашите системи към център за данни B.
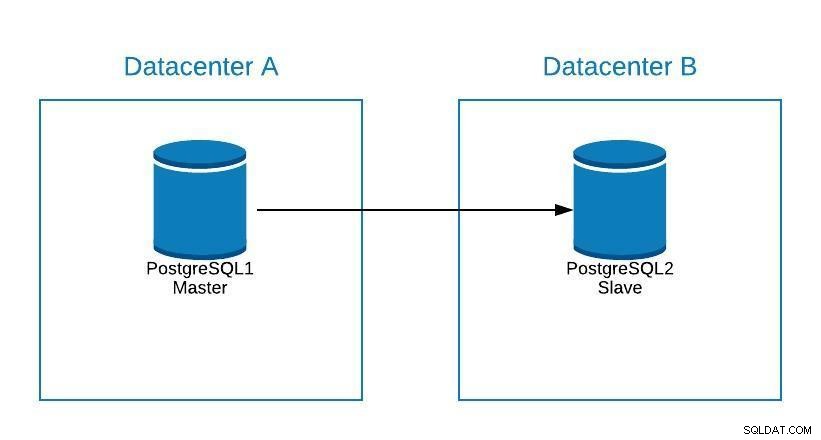 Диаграма на миграция 1
Диаграма на миграция 1 Можем да създадем реплика в център за данни B. След като бъде синхронизирана, трябва да спрем нашата система, да популяризираме нашата реплика до нов главен и да преминем при отказ, преди да насочим системата си към новия главен файл в център за данни B.
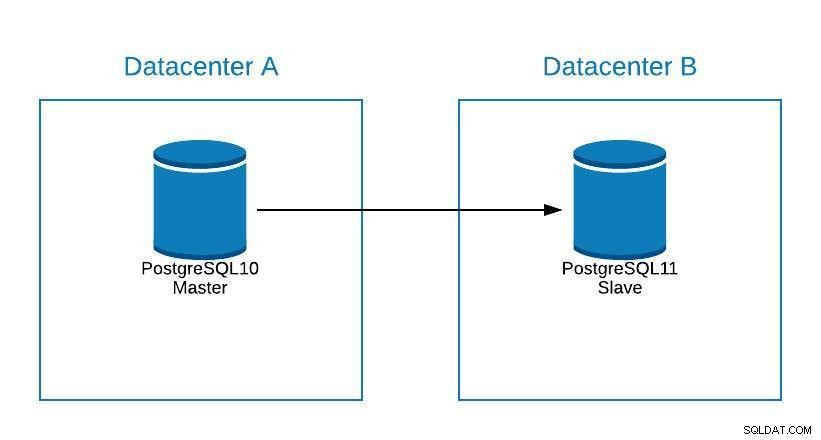
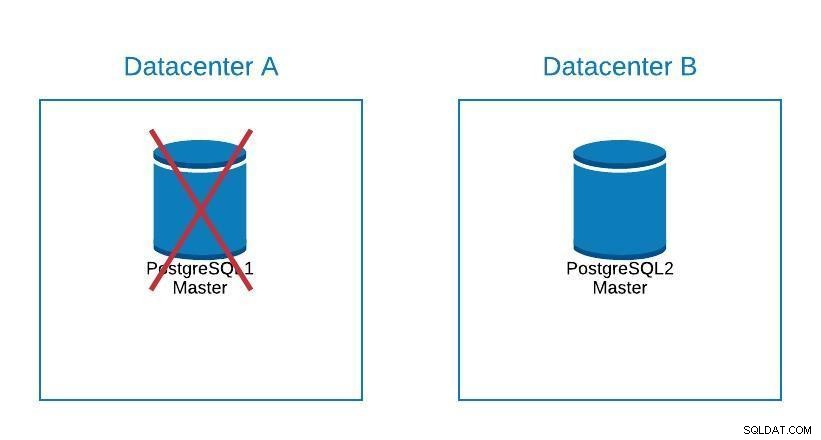 Диаграма на миграция 2
Диаграма на миграция 2 Отказът не се отнася само за базата данни, но и за приложението(ата). Как знаят към коя база данни да се свържат? Със сигурност не искаме да модифицираме нашето приложение, тъй като това само ще удължи времето ни за престой. Така че можем да конфигурираме балансьор на натоварване, така че когато свалим нашия главен, той автоматично ще сочи към следващия сървър, който е повишен.
Друг вариант е използването на DNS. Чрез популяризиране на главната реплика в новия център за данни, ние директно променяме IP адреса на името на хоста, което сочи към главния. По този начин избягваме да се налага да модифицираме нашето приложение и въпреки че това не може да се направи автоматично, това е алтернатива, ако не искаме да внедрим балансьор на натоварването.
Наличието на един екземпляр за балансиране на натоварването не е страхотно, тъй като може да се превърне в единична точка на повреда. Следователно, можете също да приложите отказ за балансиране на натоварването, като използвате услуга като keepalived. По този начин, ако имаме проблем с нашия първичен балансьор на натоварване, keepalived е отговорен за мигрирането на IP към нашия вторичен балансьор на натоварването и всичко продължава да работи прозрачно.
Поддръжка
Ако трябва да извършим каквато и да е поддръжка на нашия главен сървър на база данни postgreSQL, можем да повишим нашия подчинен, да изпълним задачата и да реконструираме подчинен на нашия стар главен.
 Диаграма за поддръжка 1
Диаграма за поддръжка 1 След това можем да повишим отново стария главен и да повторим процеса на реконструкция на подчинения, връщайки се в първоначалното състояние.
Диаграма за поддръжка 2 По този начин бихме могли да работим на нашия сървър, без да рискуваме да бъдем офлайн или да загубим информация, докато извършваме поддръжка.
Надстройване
Въпреки че PostgreSQL 11 все още не е наличен, технически би било възможно да се надстрои от PostgreSQL версия 10, като се използва логическа репликация, както може да се направи с други машини.
Стъпките биха били същите като при мигриране към нов център за данни (вижте раздел Миграция), само че нашият подчинен ще бъде в PostgreSQL 11.
 Диаграма за надстройка 1
Диаграма за надстройка 1 Проблеми
Най-важната функция на отказоустойчивостта е да сведе до минимум времето за престой или да избегне загуба на информация, когато имаме проблем с основната ни база данни.
Ако по някаква причина загубим нашата главна база данни, можем да извършим отказ, като повишим нашия подчинен до главен и да поддържаме системите си да работят.
За да направим това, PostgreSQL не ни предоставя никакво автоматизирано решение. Можем да го направим ръчно или да го автоматизираме с помощта на скрипт или външен инструмент.
За да повишите нашия роб в господар:
-
Изпълнете pg_ctl promote
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Създайте файл trigger_file, който трябва да сме добавили в recovery.conf на нашата директория с данни.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
За да приложим стратегия за преодоляване на срив, трябва да я планираме и задълбочено да тестваме чрез различни сценарии за отказ. Тъй като неуспехите могат да се случат по различни начини и в идеалния случай решението трябва да работи за повечето от често срещаните сценарии. Ако търсим начин да автоматизираме това, можем да разгледаме какво може да предложи ClusterControl.
ClusterControl за отказ на PostgreSQL
ClusterControl има редица функции, свързани с репликацията на PostgreSQL и автоматичното преминаване при отказ.
Добавяне на подчинен
Ако искаме да добавим подчинен в друг център за данни, било като непредвиден случай, или за да мигрираме вашите системи, можем да отидем на Cluster Actions и да изберем Add Replication Slave.
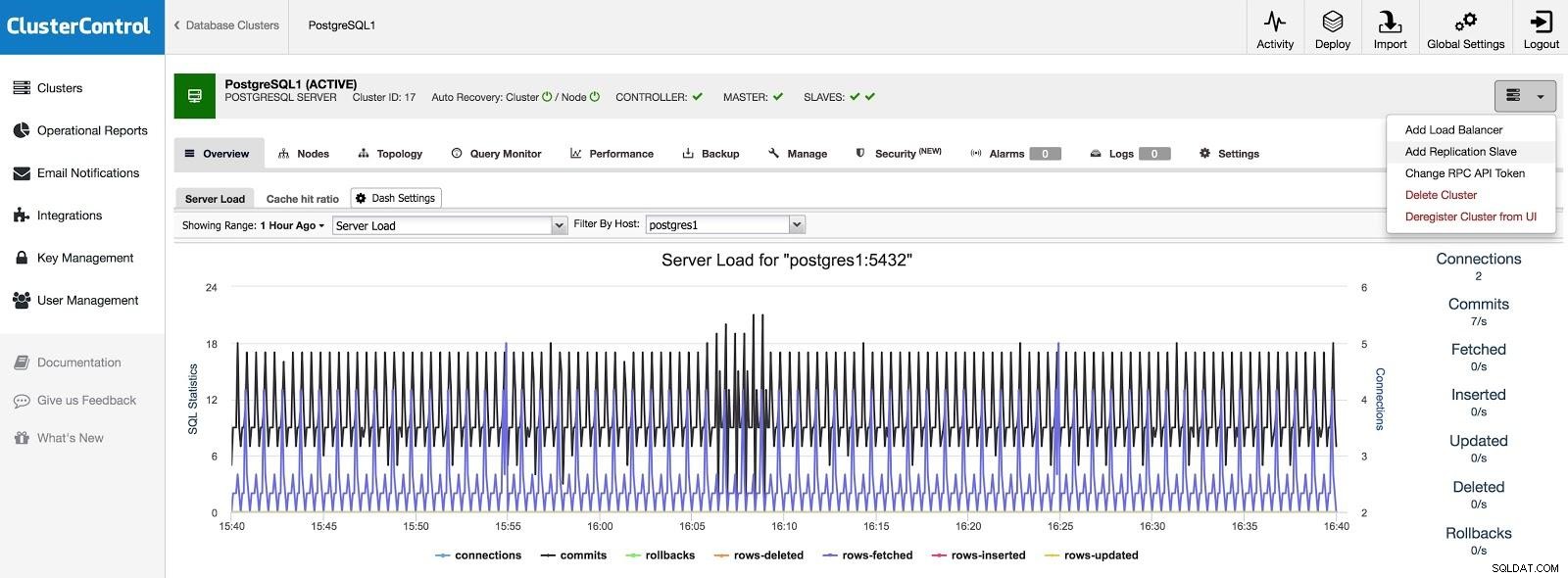 ClusterControl Добавяне на подчинен 1
ClusterControl Добавяне на подчинен 1 Ще трябва да въведете някои основни данни, като IP или име на хост, директория с данни (по избор), синхронен или асинхронен подчинен. След няколко секунди трябва да задействаме нашия роб.
В случай на използване на друг център за данни, препоръчваме да създадете асинхронен подчинен, тъй като в противен случай забавянето може да повлияе значително на производителността.
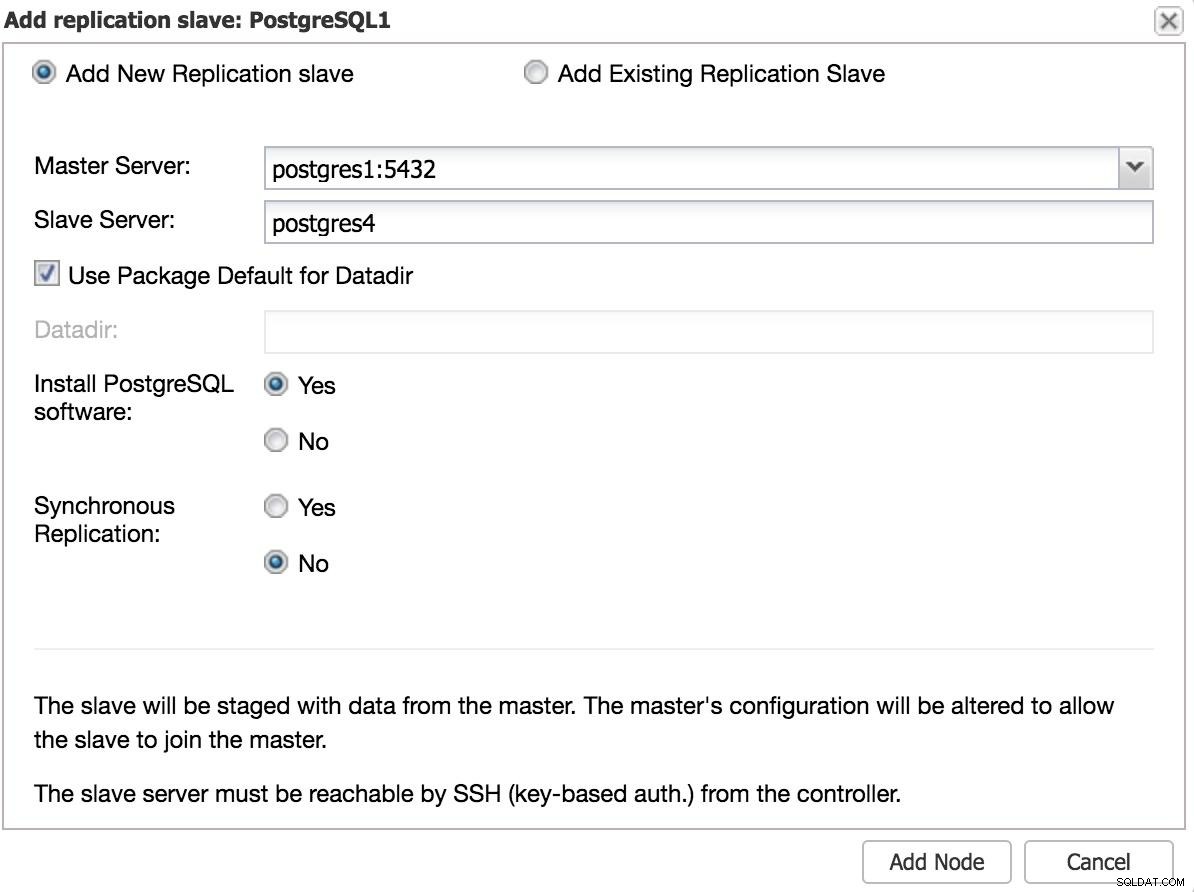 ClusterControl Добавяне на подчинен 2
ClusterControl Добавяне на подчинен 2 Ръчно превключване при отказ
С ClusterControl преминаването при отказ може да се извърши ръчно или автоматично.
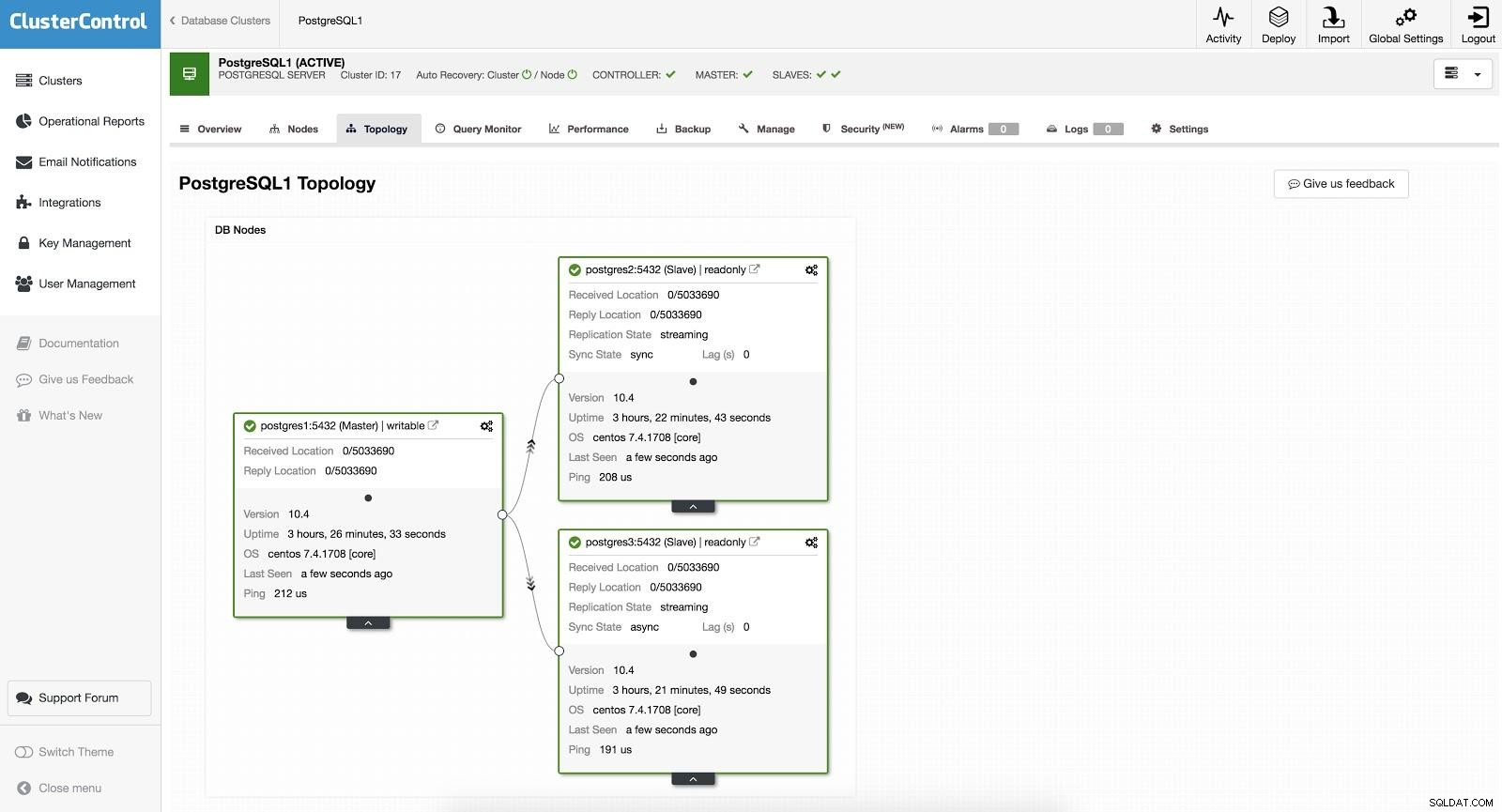 ClusterControl Failover 1
ClusterControl Failover 1 За да извършите ръчно преодоляване на срив, отидете на ClusterControl -> Изберете клъстер -> Възли и в възела за действие на един от нашите подчинени, изберете "Промотиране на подчинен". По този начин след няколко секунди нашият роб става господар, а това, което преди това е било наш господар, се превръща в роб.
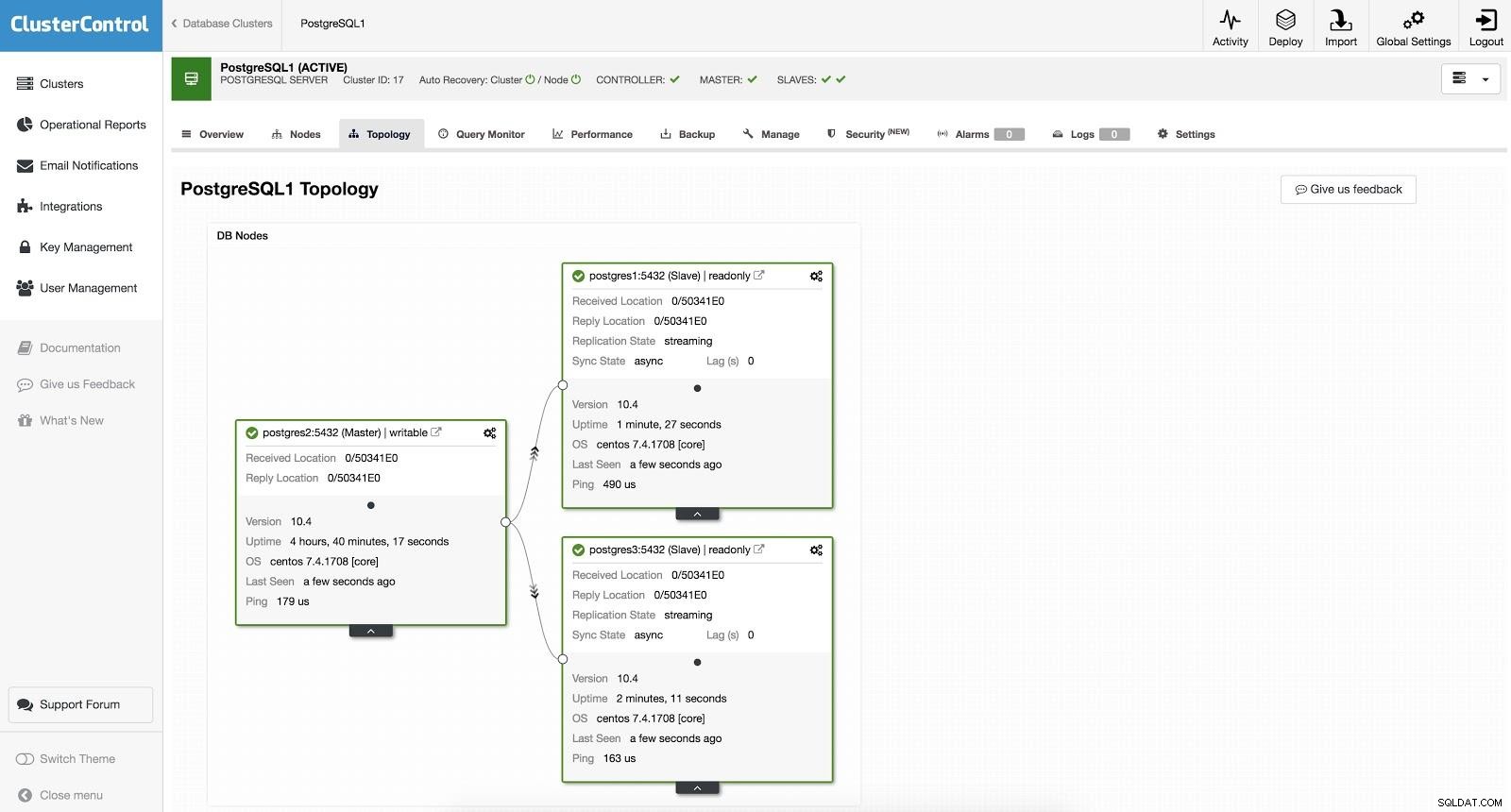 ClusterControl Failover 2
ClusterControl Failover 2 Горното е полезно за задачите по миграция, поддръжка и надстройки, които видяхме по-рано.
Автоматично преминаване при отказ
В случай на автоматично преминаване на отказ, ClusterControl открива неизправности в главната и промотира подчинен с най-актуалните данни като нов главен. Работи и върху останалите подчинени, за да ги накара да се репликират от новия главен.
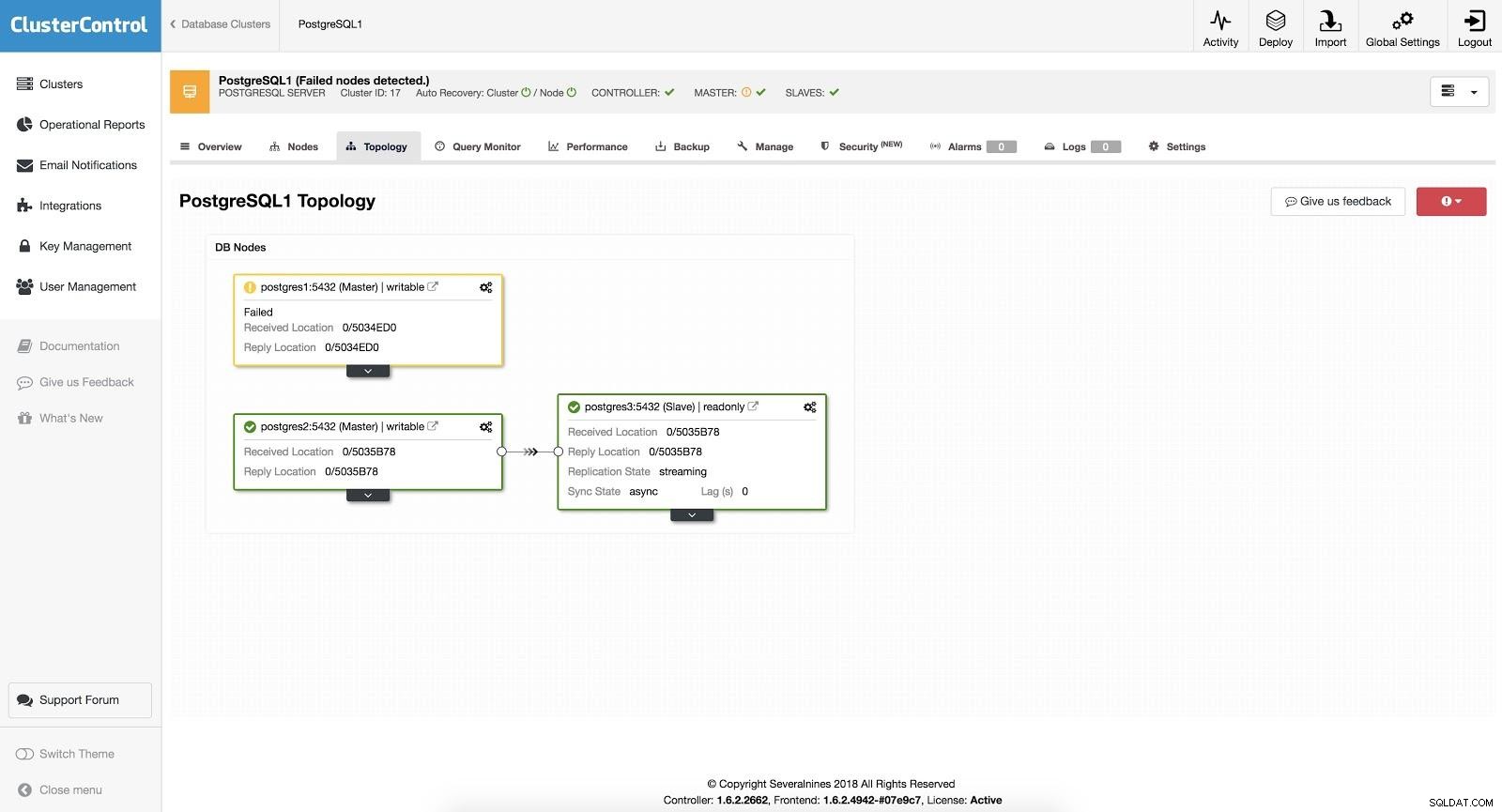 ClusterControl Failover 3
ClusterControl Failover 3 При включена опция „Автоматично възстановяване“, нашият ClusterControl ще извърши автоматично преминаване при отказ, както и ще ни уведоми за проблема. По този начин нашите системи могат да се възстановят за секунди и без наша намеса.
Cluster Control ни предлага възможността да конфигурираме бял списък/черен списък, за да дефинираме как искаме нашите сървъри да бъдат взети (или да не бъдат взети) предвид при вземане на решение за главен кандидат.
От наличните според горната конфигурация, ClusterControl ще избере най-модерния подчинен, използвайки за тази цел pg_current_xlog_location (PostgreSQL 9+) или pg_current_wal_lsn (PostgreSQL 10+) в зависимост от версията на нашата база данни.
ClusterControl също така извършва няколко проверки на процеса на отказ, за да избегне някои често срещани грешки. Един пример е, че ако успеем да възстановим нашия стар неуспешен главен, той НЯМА да бъде въведен автоматично в клъстера, нито като главен, нито като подчинен. Трябва да го направим ръчно. Това ще избегне възможността за загуба на данни или несъответствие в случай, че нашият подчинен (който сме повишени) е бил забавен в момента на неуспеха. Може също да искаме да анализираме проблема подробно, но когато го добавим към нашия клъстер, е възможно да загубим диагностична информация.
Освен това, ако преминаването при отказ не успее, не се правят допълнителни опити, е необходима ръчна намеса за анализ на проблема и извършване на съответните действия. Това е, за да се избегне ситуацията, в която ClusterControl, като мениджър с висока достъпност, се опитва да популяризира следващия подчинен и следващия. Възможно е да има проблем и ние не искаме да влошаваме нещата, като се опитваме да превключваме на множество откази.
Балансьори на натоварване
Както споменахме по-рано, балансьорът на натоварване е важен инструмент, който трябва да вземем предвид за нашето преминаване при отказ, особено ако искаме да използваме автоматично преминаване при отказ в топологията на нашата база данни.
За да бъде превключването при отказ да бъде прозрачно както за потребителя, така и за приложението, се нуждаем от компонент между тях, тъй като не е достатъчно да повишим главен в подчинен. За това можем да използваме HAProxy + Keepalived.
Какво е HAProxy?
HAProxy е балансьор на натоварване, който разпределя трафика от един източник към една или повече дестинации и може да дефинира специфични правила и/или протоколи за тази задача. Ако някоя от дестинациите спре да отговаря, тя се маркира като офлайн и трафикът се изпраща към останалите налични дестинации. Това предотвратява изпращането на трафик към недостъпна дестинация и предотвратява загубата на този трафик, като го насочва към валидна дестинация.
Какво е Keepalived?
Keepalived ви позволява да конфигурирате виртуален IP в рамките на активна/пасивна група сървъри. Този виртуален IP се присвоява на активен „основен“ сървър. Ако този сървър не успее, IP адресът автоматично се мигрира към „Вторичния“ сървър, за който е установено, че е пасивен, което му позволява да продължи да работи със същия IP по прозрачен начин за нашите системи.
За да приложим това решение с ClusterControl, започнахме така, сякаш ще добавим подчинен. Отидете на Cluster Actions и изберете Add Load Balancer (вижте ClusterControl Add Slave 1 image).
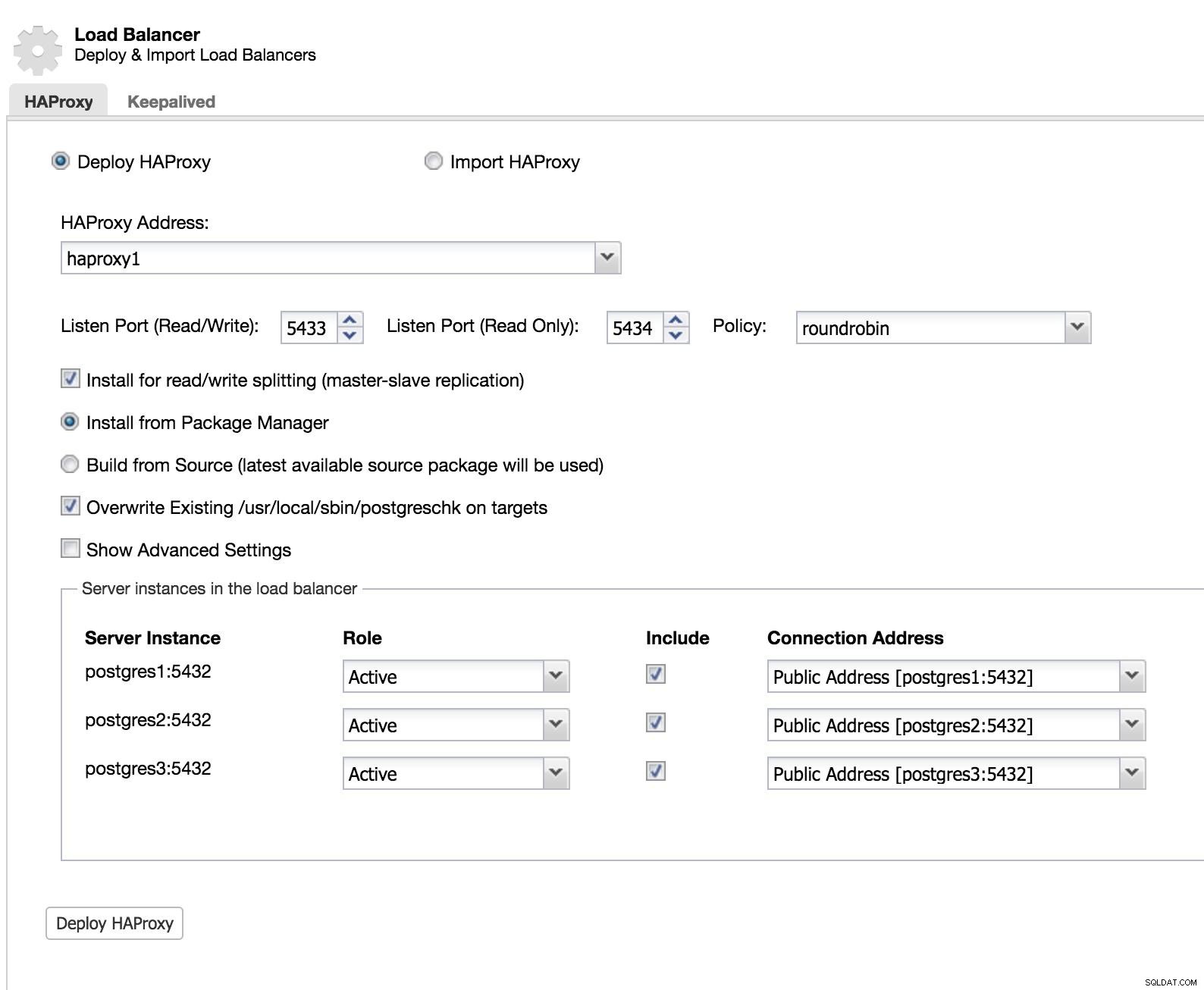 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Добавяме информацията от нашия нов балансьор на натоварването и как искаме да се държи (политика).
В случай, че искаме да приложим отказоустойчивост за нашия балансьор на натоварване, трябва да конфигурираме поне два екземпляра.
След това можем да конфигурираме Keepalived (Изберете Cluster -> Manage -> Load Balancer -> Keepalived).
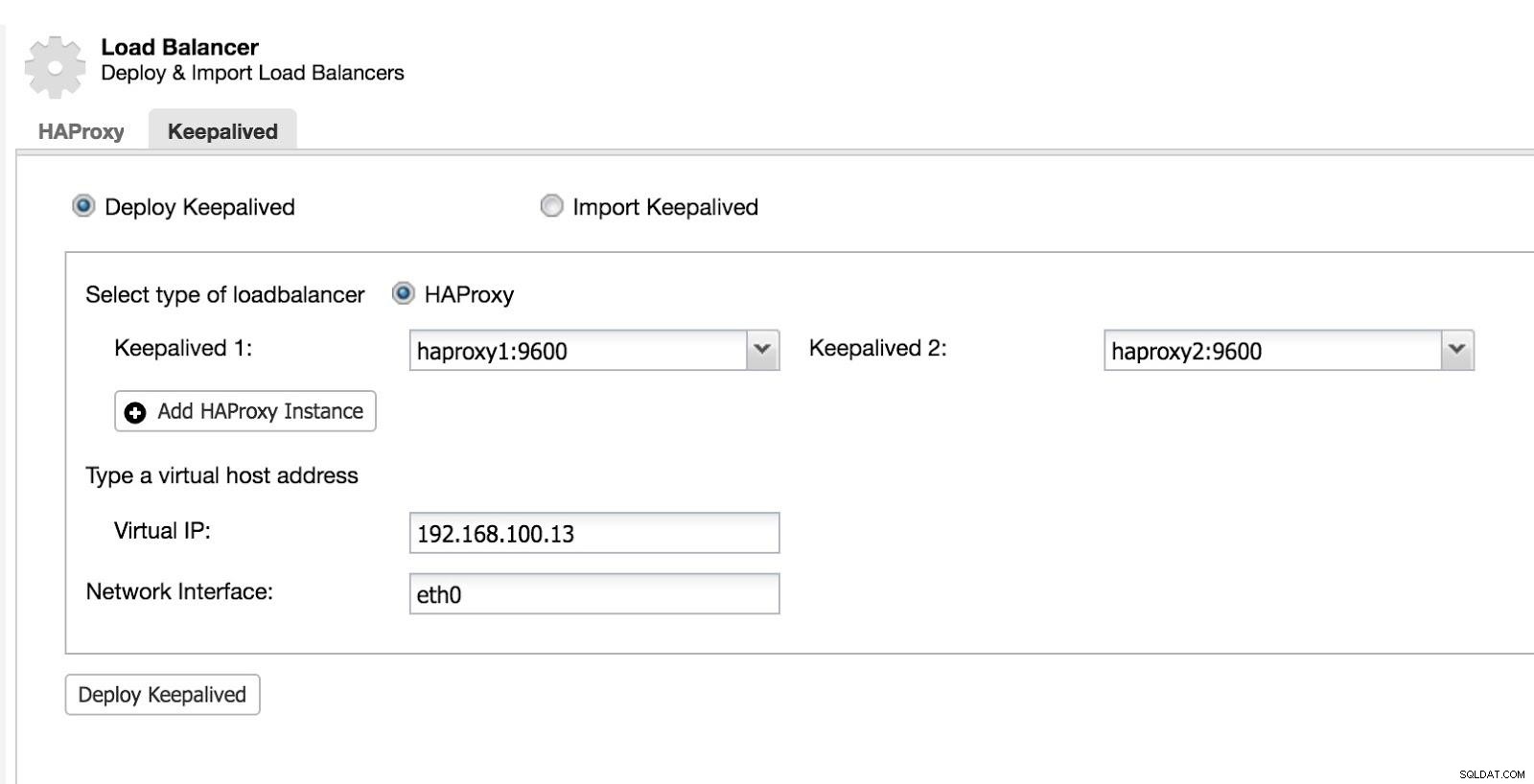 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 След това имаме следната топология:
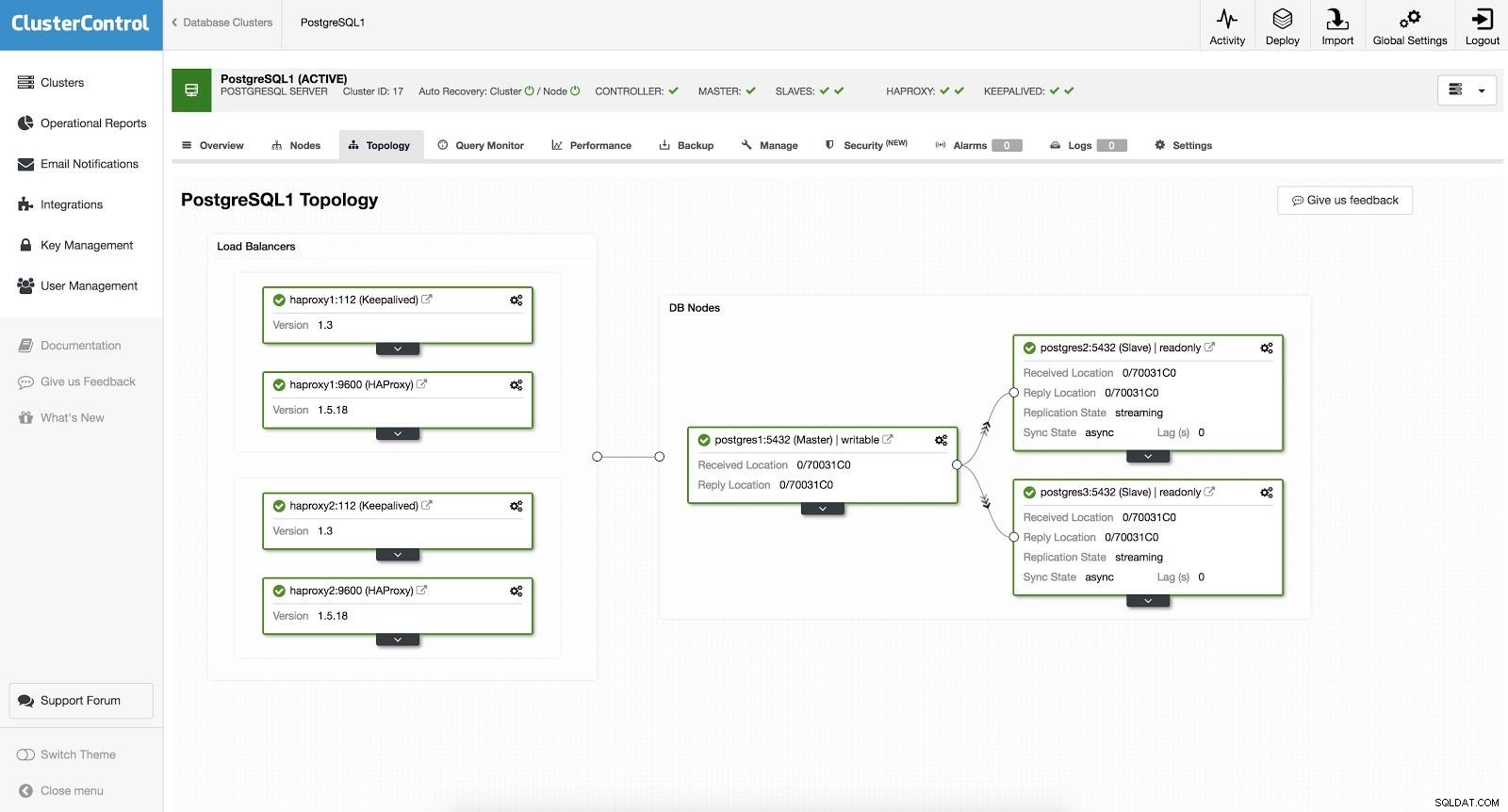 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy е конфигуриран с два различни порта, един за четене-запис и един само за четене.
В нашия порт за четене и запис имаме нашия главен сървър като онлайн, а останалите ни възли като офлайн. В порта само за четене имаме онлайн и главният, и подчинените. По този начин можем да балансираме трафика за четене между нашите възли. При запис ще се използва портът за четене-запис, който ще сочи към главния.
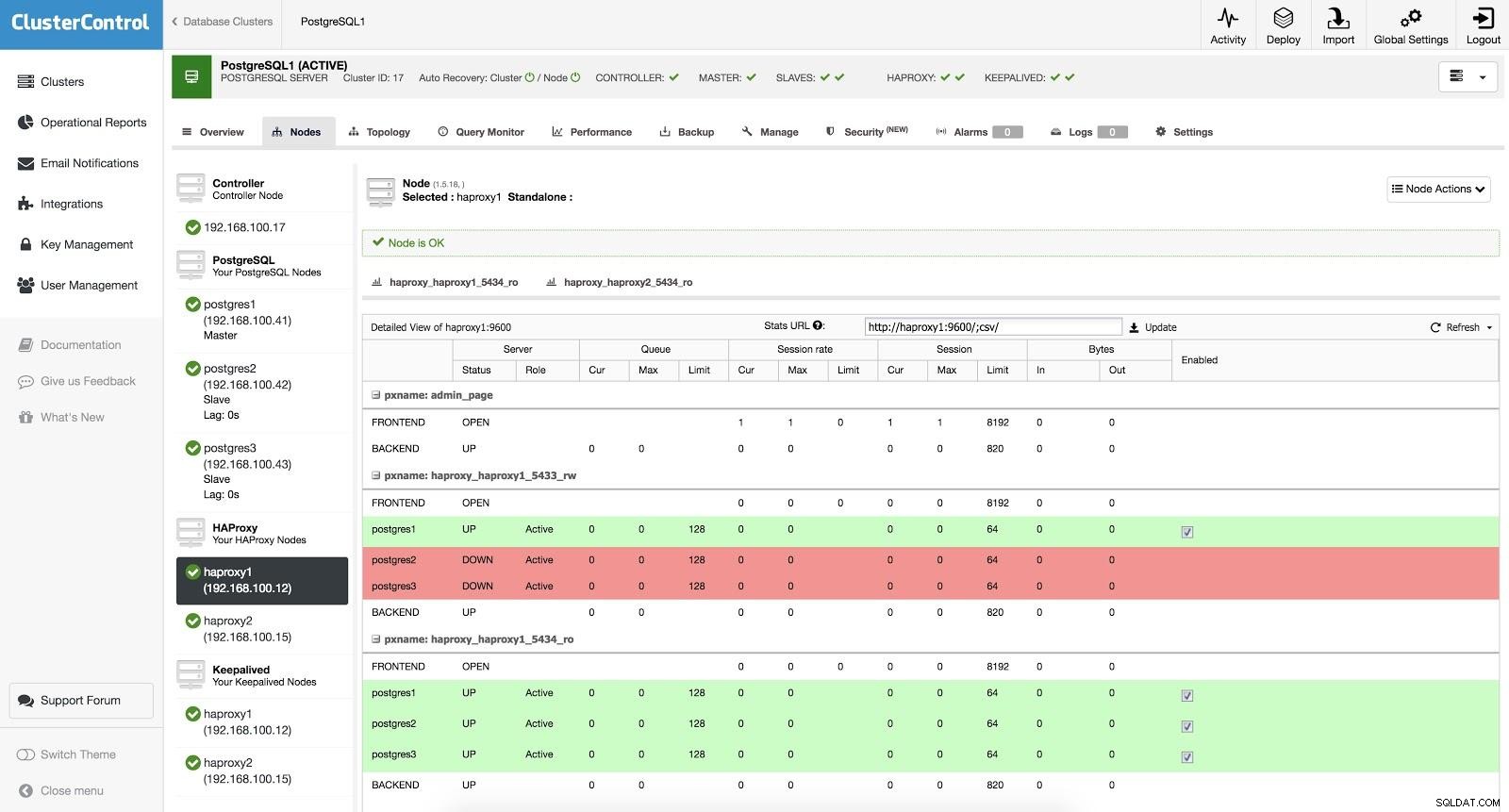 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Когато HAProxy открие, че един от нашите възли, главен или подчинен, не е достъпен, той автоматично го маркира като офлайн. HAProxy няма да изпраща трафик към него. Тази проверка се извършва от скриптове за проверка на състоянието, които са конфигурирани от ClusterControl по време на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Когато ClusterControl промотира подчинен към главен, нашият HAProxy маркира стария главен обект като офлайн (и за двата порта) и поставя повишения възел онлайн (в порта за четене-запис). По този начин нашите системи продължават да работят нормално.
Ако нашият активен HAProxy (на който е присвоен виртуален IP адрес, към който се свързват нашите системи) не успее, Keepalived мигрира този IP към нашия пасивен HAProxy автоматично. Това означава, че нашите системи могат да продължат да функционират нормално.
Заключение
Както можем да видим, отказът е основна част от всяка производствена база данни. Може да бъде полезно при изпълнение на общи задачи по поддръжка или миграции. Надяваме се, че този блог е бил полезен като въведение в темата, за да можете да продължите да проучвате и да създавате свои собствени стратегии за преодоляване на срив.