Чудите ли се какво представляват схемите на Postgresql и защо са важни и как можете да използвате схемите, за да направите реализациите на базата си данни по-стабилни и поддържащи се? Тази статия ще представи основите на схемите в Postgresql и ще ви покаже как да ги създадете с някои основни примери. Бъдещите статии ще задълбават в примери за това как да защитите и използвате схеми за реални приложения.
Първо, за да изчистим потенциалното терминологично объркване, нека разберем, че в света на Postgresql терминът „схема“ може би е донякъде за съжаление претоварен. В по-широкия контекст на системите за управление на релационни бази данни (RDBMS), терминът „схема“ може да се разбира като отнасящ се до цялостния логически или физически дизайн на базата данни, т.е. дефиницията на всички таблици, колони, изгледи и други обекти които съставляват дефиницията на базата данни. В този по-широк контекст схемата може да бъде изразена в диаграма за връзка между обекти (ER) или скрипт от изрази на езика за дефиниране на данни (DDL), използвани за инстанциране на базата данни на приложението.
В света на Postgresql терминът „схема“ може да се разбира по-добре като „пространство от имена“. Всъщност в системните таблици на Postgresql схемите се записват в колони на таблицата, наречени „пространство на имената“, което, IMHO, е по-точна терминология. Като практически въпрос, винаги, когато видя „схема“ в контекста на Postgresql, мълчаливо го тълкувам като казвам „пространство за имена“.
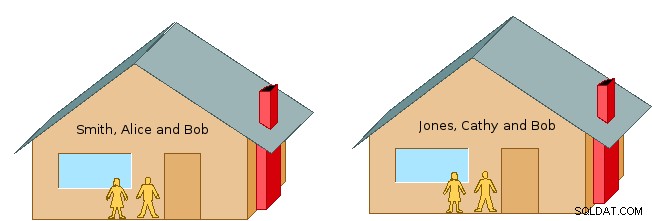
Но може да попитате:„Какво е пространство за имена?“ Като цяло пространството за имена е доста гъвкаво средство за организиране и идентифициране на информация по име. Например, представете си две съседни домакинства, Смит, Алис и Боб, и Джоунс, Боб и Кати (вж. Фигура 1). Ако използвахме само собствени имена, може да стане объркващо кой човек имаме предвид, когато говорим за Боб. Но като добавим фамилното име Смит или Джоунс, ние уникално идентифицираме кой човек имаме предвид.
Често пространствата за имена са организирани във вложена йерархия. Това позволява ефективно класифициране на огромни количества информация в много фина структура, като например системата за имена на интернет домейни. На най-високо ниво „.com“, „.net“, „.org“, „.edu“ и т.н. дефинират широки пространства от имена, в които са регистрирани имена за конкретни субекти, така например „severalnines.com“ и “postgresql.org” са уникално дефинирани. Но под всеки от тях има редица общи поддомейни като „www“, „mail“ и „ftp“, например, които сами по себе си са дублиращи се, но в рамките на съответните пространства за имена са уникални.
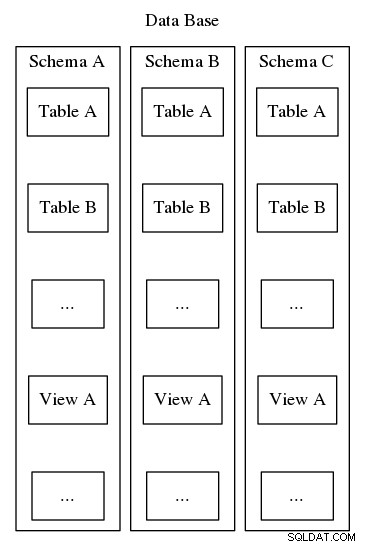
Postgresql схемите служат на същата цел за организиране и идентифициране, но за разлика от втория пример по-горе, Postgresql схемите не могат да бъдат вложени в йерархия. Въпреки че базата данни може да съдържа много схеми, винаги има само едно ниво и така в рамките на база данни имената на схемите трябва да са уникални. Освен това всяка база данни трябва да включва поне една схема. Всеки път, когато се инстанцира нова база данни, се създава схема по подразбиране, наречена „public“. Съдържанието на схемата включва всички други обекти на базата данни, като таблици, изгледи, съхранени процедури, тригери и т.н. За да визуализирате, вижте фигура 2, която изобразява гнездене, подобно на матрьошка, показващо къде се вписват схемите в структурата на Postgresql база данни.
Освен простото организиране на обекти от база данни в логически групи, за да ги направят по-управляеми, схемите служат на практическата цел за избягване на сблъсък на имена. Една оперативна парадигма включва дефиниране на схема за всеки потребител на база данни, така че да осигури известна степен на изолация, пространство, където потребителите могат да дефинират свои собствени таблици и изгледи, без да се намесват един в друг. Друг подход е да инсталирате инструменти на трети страни или разширения за база данни в отделни схеми, така че да поддържате всички свързани компоненти логически заедно. По-късна статия от тази серия ще описва подробно нов подход към стабилен дизайн на приложения, използвайки схеми като средство за индиректно ограничаване на излагането на физическия дизайн на базата данни и вместо това представя потребителски интерфейс, който разрешава синтетични ключове и улеснява дългосрочната поддръжка и управление на конфигурацията тъй като системните изисквания се развиват.
Нека направим някакъв код!
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаНай-простата команда за създаване на схема в база данни е
CREATE SCHEMA hollywood;Тази команда изисква привилегии за създаване в базата данни, а новосъздадената схема „холивуд“ ще бъде собственост на потребител, извикащ командата. По-сложното извикване може да включва незадължителни елементи, посочващи различен собственик, и дори може да включва DDL изрази, инстанциращи обекти от база данни в схемата всичко в една команда!
Общият формат е
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]където „потребителско име“ е кой ще притежава схемата и „schema_element“ може да е една от определени DDL команди (вижте документацията на Postgresql за подробности). Необходими са привилегии на суперпотребител за използване на опцията АВТОРИЗАЦИЯ.
Така например, за да създадете схема с име „холивуд“, съдържаща таблица с име „films“ и преглед на име „winners“ в една команда, можете да направите
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Впоследствие могат да бъдат създадени директно допълнителни обекти на базата данни, например допълнителна таблица ще бъде добавена към схемата с
CREATE TABLE hollywood.actors (name text, dob date, gender text);Забележете в горния пример префикса на името на таблицата с името на схемата. Това е необходимо, тъй като по подразбиране, без изрична спецификация на схемата, нови обекти на база данни се създават в рамките на текущата схема, която ще разгледаме по-нататък.
Припомнете си как в примера за първо име за пространство по-горе имахме двама души на име Боб и описахме как да ги разграничим или разграничим, като включим фамилното име. Но във всяко от домакинствата на Смит и Джоунс поотделно, всяко семейство разбира „Боб“ за това, което върви с това конкретно домакинство. Така например в контекста на всяко съответно домакинство, Алис не трябва да се обръща към съпруга си с Боб Джоунс, а Кати не трябва да се отнася към съпруга си като Боб Смит:всеки от тях може просто да каже „Боб“.
Текущата схема на Postgresql е нещо като домакинството в горния пример. Обектите в текущата схема могат да бъдат посочени неквалифицирани, но позоваването на подобни наименувани обекти в други схеми изисква квалифициране на името чрез префикс на името на схемата, както е по-горе.
Текущата схема се извлича от конфигурационния параметър „search_path“. Този параметър съхранява разделен със запетая списък с имена на схеми и може да бъде проверен с командата
SHOW search_path;или задайте нова стойност с
SET search_path TO schema [, schema, ...];Първото име на схема в списъка е „текущата схема“ и е мястото, където се създават нови обекти, ако е указано без квалификация на името на схемата.
Разделеният със запетая списък с имена на схеми също служи за определяне на реда на търсене, по който системата намира съществуващи неквалифицирани наименувани обекти. Например, обратно в квартала Смит и Джоунс, доставка на пакет, адресирана само до „Боб“, ще изисква посещение във всяко домакинство, докато не бъде намерен първият жител на име „Боб“. Имайте предвид, че това може да не е целевият получател. Същата логика важи и за Postgresql. Системата търси таблици, изгледи и други обекти в рамките на схеми в реда на search_path и след това се използва първият намерен обект за съвпадение на име. Квалифицираните за схемата именувани обекти се използват директно без препратка към пътя_търсене.
В конфигурацията по подразбиране, запитването на конфигурационната променлива search_path разкрива тази стойност
SHOW search_path;
Search_path
--------------
"$user", publicСистемата интерпретира първата стойност, показана по-горе, като текущо влязло потребителско име и приспособява случая на използване, споменат по-рано, където на всеки потребител се разпределя схема с име на потребител за работно пространство, отделно от другите потребители. Ако не е създадена такава схема с име на потребител, този запис се игнорира и „публичната“ схема става текущата схема, където се създават нови обекти.
По този начин, обратно към нашия по-ранен пример за създаване на таблицата “hollywood.actors”, ако не бяхме квалифицирали името на таблицата с името на схемата, тогава таблицата щеше да бъде създадена в публичната схема. Ако очаквахме да създадем всички обекти в рамките на конкретна схема, тогава може да е удобно да зададем променливата search_path като
SET search_path TO hollywood,public;улесняване на стенографията за въвеждане на неквалифицирани имена за създаване или достъп до обекти на база данни.
Има и функция за системна информация, която връща текущата схема със заявка
select current_schema();В случай на тлъсти пръсти на правописа, собственикът на схема може да промени името, при условие че потребителят също има права за създаване на базата данни, с
ALTER SCHEMA old_name RENAME TO new_name;И накрая, за да изтриете схема от база данни, има команда drop
DROP SCHEMA schema_name;Командата DROP ще се провали, ако схемата съдържа обекти, така че те трябва да бъдат изтрити първо, или по избор можете да изтриете рекурсивно цялото й съдържание на схема с опцията CASCADE
DROP SCHEMA schema_name CASCADE;Тези основи ще ви помогнат да започнете с разбирането на схеми!