PostgreSQL, известен още като най-напредналата база данни с отворен код в света, има нова версия от миналата 24 септември 2020 г. и сега е зряла, можем да проверим какво е новото там, за да започнем да мислим за план за миграция. PostgreSQL 13 се предлага с много нови функции и подобрения. В този блог ще споменем някои от тези нови функции и ще видим как да разположите или надстроите текущата си версия на PostgreSQL.
Нови функции и подобрения на PostgreSQL 13
Нека започнем да споменаваме някои от новите функции и подобрения на тази версия на PostgreSQL 13, които можете да видите в официалната документация.
Разделяне на дялове
-
Разрешаване на подрязването на дялове и свързвания по дялове да се случват в повече случаи
-
Поддържа тригери на ниво ред ПРЕДИ задействания в разделени таблици
-
Разрешаване на разделените таблици да бъдат логически репликирани чрез публикация
-
Разрешаване на логическа репликация в разделени таблици на абонати
-
Разрешаване на променливи от цял ред да се използват в изразите за разделяне
Индекси
-
По-ефективно съхраняване на дубликати в индексите на B-дърво
-
Разрешаване на GiST и SP-GiST индекси в колоните на полето да поддържат ORDER BY поле <-> точкови заявки
-
Позволете на GIN индексите да се справят по-ефективно! (НЕ) клаузи в tsquery търсения
-
Разрешаване на класовете на индексни оператори да приемат параметри
Оптимизатор
-
Подобрете оценката на селективността на оптимизатора за оператори за ограничаване/съвпадение
-
Разрешаване на настройката на целта за статистически данни за разширени статистически данни
-
Разрешаване на използването на множество разширени статистически обекти в една заявка
-
Разрешаване на използването на разширени статистически обекти за клаузи ИЛИ и IN/ANY списъци с константи
-
Разрешаване на функциите в клаузите FROM да бъдат изтеглени (вградени), ако се оценяват до константи
Ефективност
-
Внедряване на инкрементално сортиране и подобряване на производителността на сортиране на inet стойности
-
Разрешаване на хеш агрегацията да използва дисково хранилище за големи набори от резултати от агрегиране
-
Разрешаване на вмъквания, а не само на актуализации и изтривания, за задействане на дейност по вакуумиране при автоматично вакуумиране
-
Добавете параметър за поддръжка_io_concurrency, за да контролирате паралелността на I/O за операции по поддръжка
-
Разрешаване на записите в WAL да бъдат пропуснати по време на транзакция, която създава или пренаписва релация, ако wal_level е минимален
-
Подобрете производителността при повторно възпроизвеждане на команди DROP DATABASE, когато се използват много пространства за таблици
-
Ускорете преобразуването на цели числа в текст
-
Намалете използването на паметта за низове на заявки и скриптове за разширения, които съдържат много SQL изрази
Наблюдение
-
Разрешаване на EXPLAIN, auto_explain, autovacuum и pg_stat_statements да проследяват статистически данни за използването на WAL
-
Разрешаване на записване на извадка от SQL изрази, а не на всички изрази
-
Добавете задния тип към csvlog и по избор log_line_prefix лог изход
-
Подобрете контрола на регистрирането на подготвени параметри на израза
-
Добавете leader_pid към pg_stat_activity, за да докладвате паралелен процес на лидер на работник
-
Добавете системен изглед pg_stat_progress_basebackup, за да докладвате напредъка на поточните базови архиви
-
Добавете системен изглед pg_stat_progress_analyze, за да отчетете напредъка на ANALYZE
-
Добавяне на системен изглед pg_shmem_allocations за показване на използването на споделена памет
Репликация и възстановяване
-
Разрешаване на конфигурацията на поточно репликация да се променят чрез презареждане
-
Разрешаване на WAL приемниците да използват временен слот за репликация, когато не е посочен постоянен.
-
Разрешаване на съхранението на WAL за слотове за репликация да бъде ограничено от max_slot_wal_keep_size
-
Разрешаване на промоцията в режим на готовност за отмяна на всяка заявена пауза
-
Генерирайте грешка, ако възстановяването не достигне посочената цел за възстановяване
-
Разрешаване на контрол върху това колко памет се използва от логическото декодиране, преди да се разлее на диск
-
Разрешаване на възстановяването да продължи дори ако WAL препраща към невалидни страници
Команди за помощни програми
-
Позволете на VACUUM да обработва паралелно индексите на таблица
-
Отчет за използването на буфера във времето за планиране в изхода BUFFER на EXPLAIN
-
Направете CREATE TABLE LIKE да разпространява свойството NO INHERIT на ограничението CHECK към създадената таблица
-
Добавете ALTER TABLE ... DROP EXPRESSION, за да позволите премахването на свойството GENERATED от колона
-
Добавете синтаксис ALTER VIEW, за да преименувате колоните на изгледа
-
Добавете опции ALTER TYPE, за да промените TOAST свойствата и поддържащите функции на базов тип
-
Добавяне на опция CREATE DATABASE LOCALE
-
Разрешаване на DROP DATABASE да прекъсне връзката на сесиите с помощта на целевата база данни, позволявайки успешно прехвърлянето
И много други промени. Току-що споменахме някои от тях, за да избегнем по-голяма публикация в блога. Сега нека видим как да разположим тази нова версия.
Как да внедря PostgreSQL 13
За това ще приемем, че имате инсталиран ClusterControl, в противен случай можете да следвате съответната документация, за да го инсталирате.
За да извършите внедряване от ClusterControl, просто изберете опцията Разгръщане и следвайте инструкциите, които се появяват.
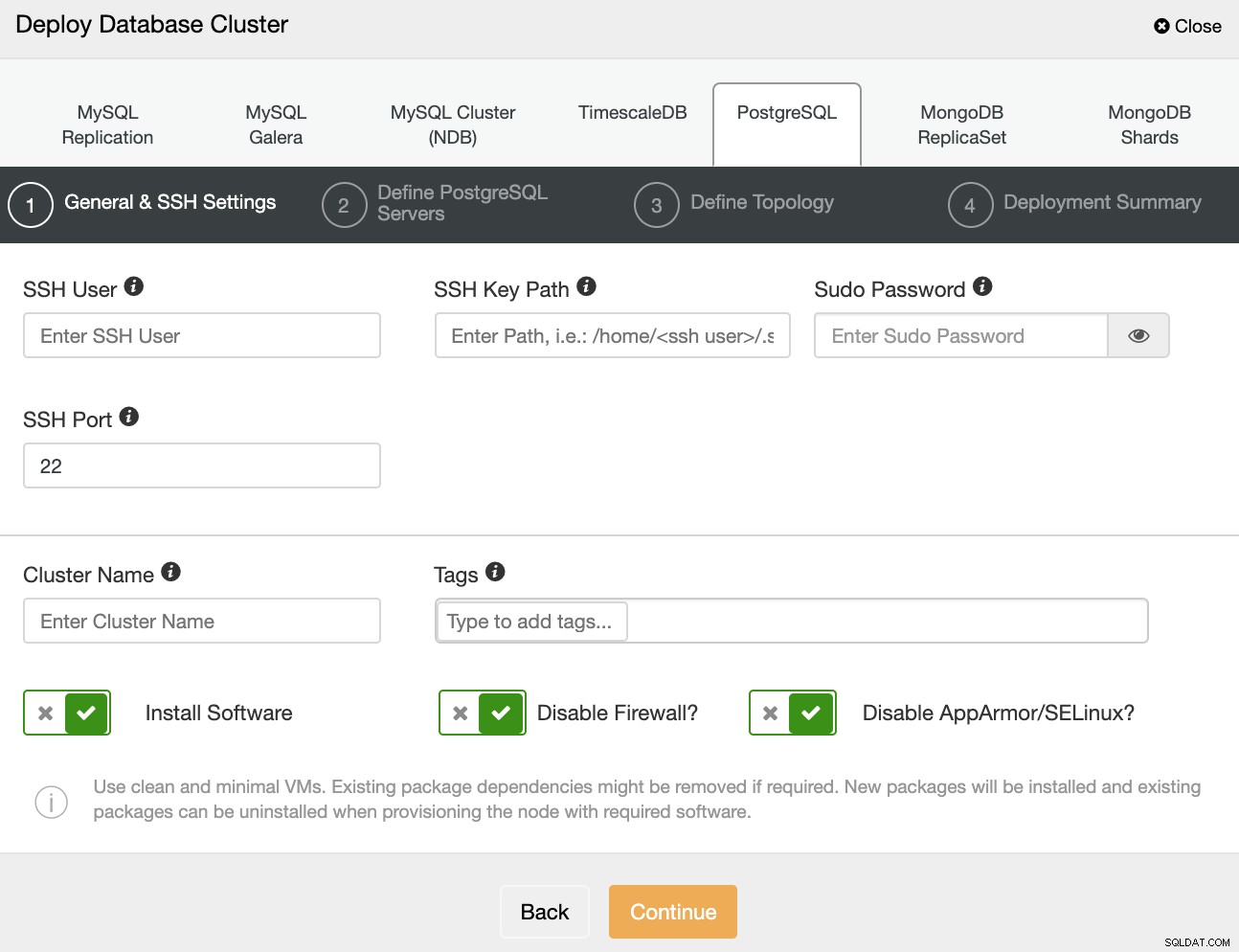
Когато избирате PostgreSQL, трябва да посочите потребител, ключ или парола и порт за да се свържете чрез SSH към вашите сървъри. Можете също да добавите име за вашия нов клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
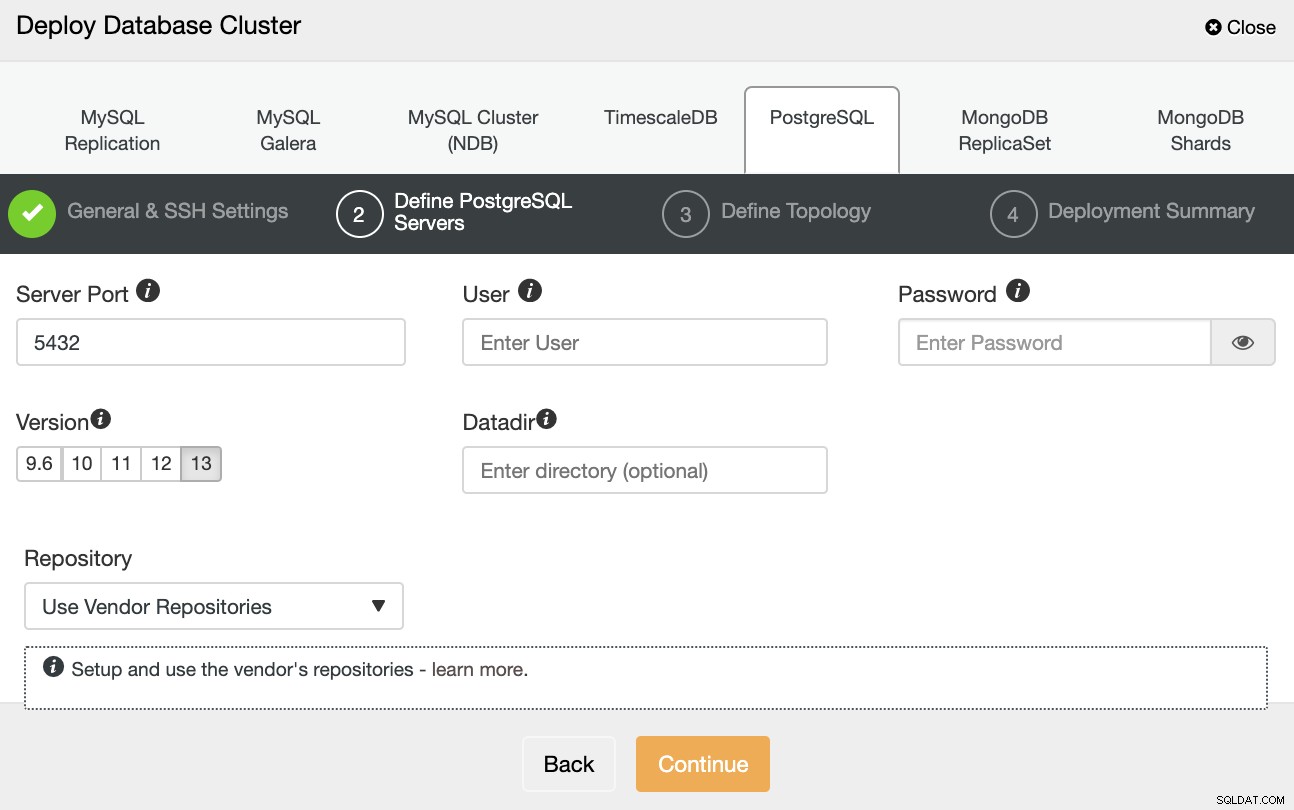
След като настроите информацията за SSH достъп, трябва да дефинирате идентификационните данни за базата данни , версия и datadir (по избор). Можете също да посочите кое хранилище да използвате.
В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете, използвайки IP адреса или името на хоста.
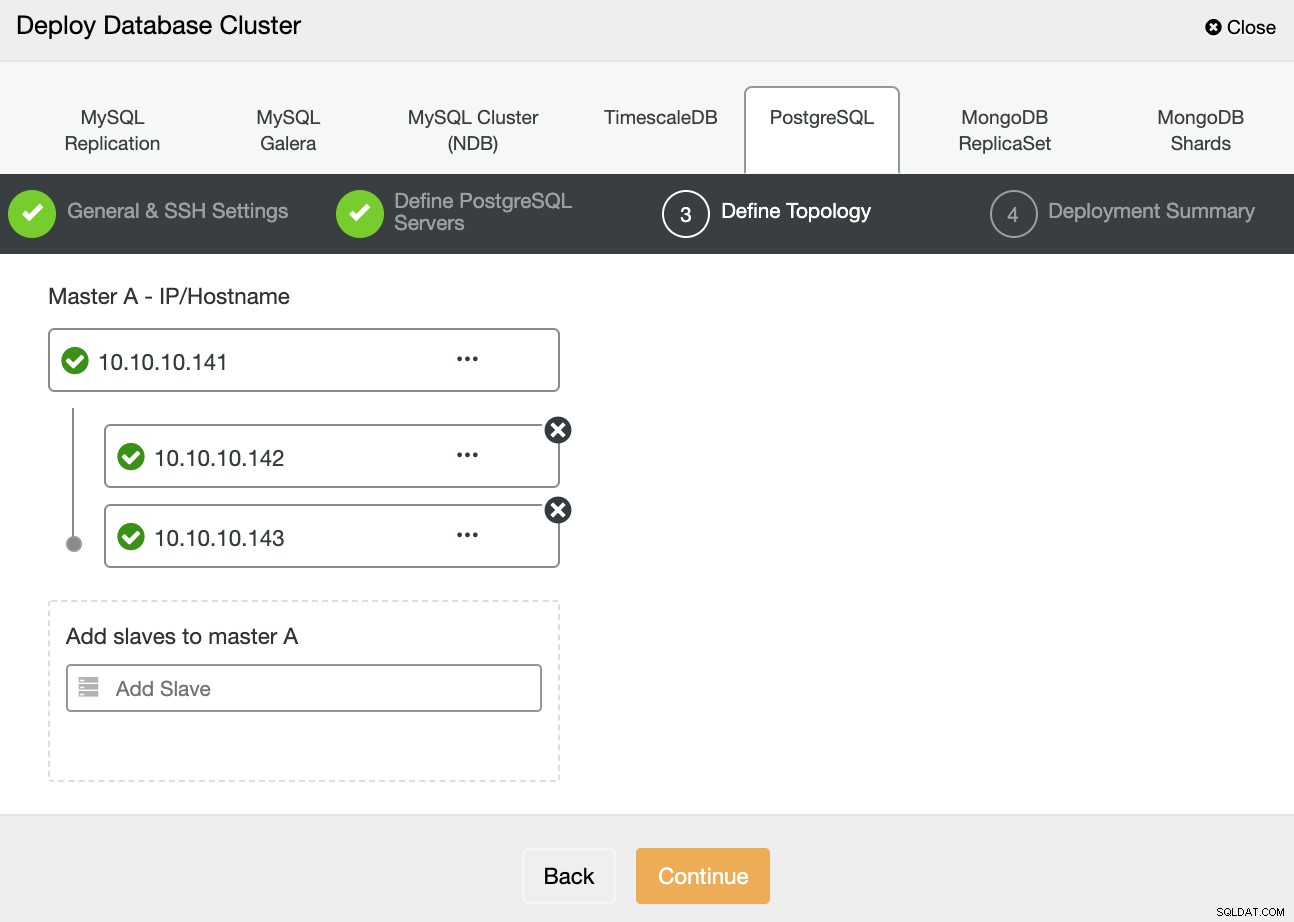
В последната стъпка можете да изберете дали репликацията ви ще бъде синхронна или Асинхронно и след това просто натиснете Разгръщане.
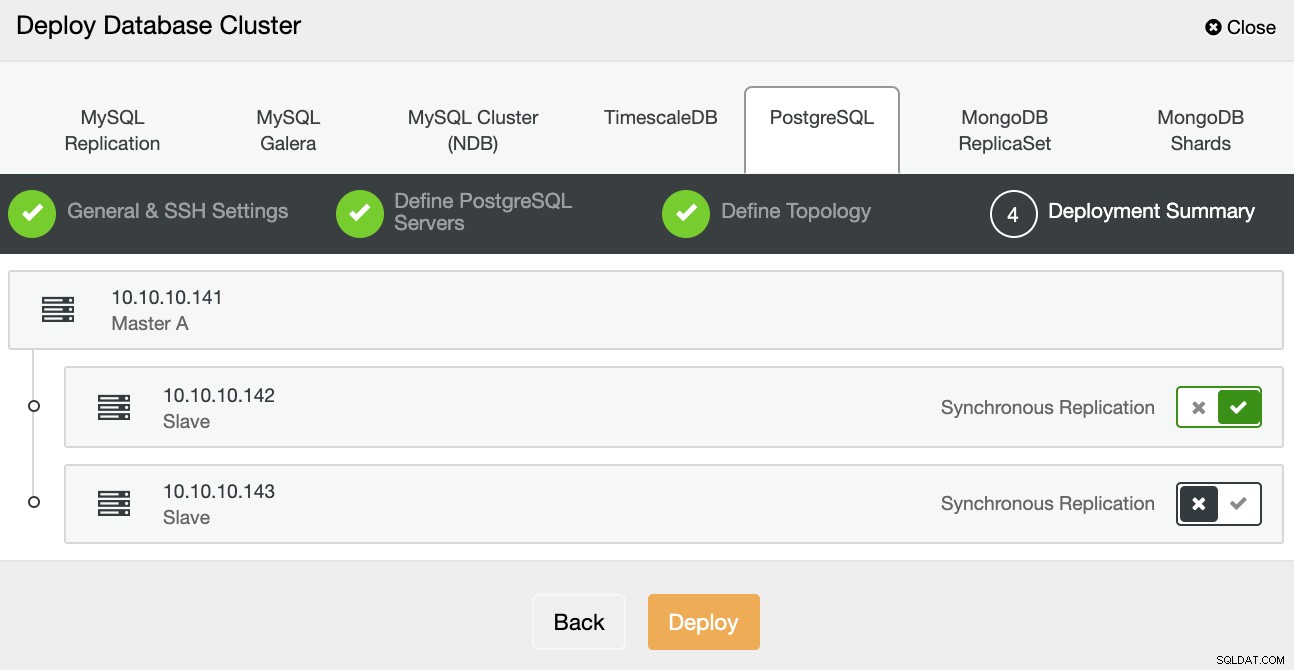
След като задачата приключи, можете да видите своя нов PostgreSQL клъстер в главен екран на ClusterControl.

Сега имате създаден клъстер, можете да изпълнявате няколко задачи върху него, като добавяне на балансьори на натоварване (HAProxy), пулери за връзки (PgBouncer) или нови подчинени устройства за репликация от същия потребителски интерфейс на ClusterControl.
Надстройване до PostgreSQL 13
Ако искате да надстроите текущата си версия на PostgreSQL до тази нова, имате три основни опции, които ще изпълнят тази задача.
-
Pg_dump:Това е инструмент за логично архивиране, който ви позволява да изхвърлите данните си и да ги възстановите в новия PostgreSQL версия. Тук ще имате период на престой, който ще варира в зависимост от размера на вашите данни. Трябва да спрете системата или да избегнете нови данни в основния възел, да стартирате pg_dump, да преместите генерирания дъмп в новия възел на базата данни и да го възстановите. През това време не можете да пишете в основната си база данни PostgreSQL, за да избегнете несъответствие на данните.
-
Pg_upgrade:Това е инструмент на PostgreSQL за надграждане на вашата PostgreSQL версия на място. Може да бъде опасно в производствена среда и ние не препоръчваме този метод в този случай. Използвайки този метод, вие също ще имате време за престой, но вероятно ще бъде значително по-малко от използването на предишния метод pg_dump.
-
Логическа репликация:От PostgreSQL 10 можете да използвате този метод на репликация, който ви позволява да извършвате големи надстройки на версията с нулев (или почти нулев) престой. По този начин можете да добавите резервен възел в последната версия на PostgreSQL и когато репликацията е актуална, можете да извършите процес на отказ, за да популяризирате новия PostgreSQL възел.
За по-подробна информация относно новите функции на PostgreSQL 13 можете да се обърнете към Официалната документация.



