Мониторингът на промените в схемата на вашата база данни в MySQL/MariaDB предоставя огромна помощ, тъй като спестява време за анализиране на растежа на вашата база данни, промените в дефинициите на таблицата, размера на данните, размера на индекса или размера на реда. За MySQL/MariaDB изпълнението на заявка, препращаща information_schema заедно с performance_schema, ви дава колективни резултати за по-нататъшен анализ. Схемата на sys ви предоставя изгледи, които служат като колективни показатели, които са много полезни за проследяване на промени в базата данни или активност.
Ако имате много сървъри на бази данни, би било досадно да изпълнявате заявка през цялото време. Вие също трябва да усвоите този резултат в по-четлив и по-лесен за разбиране.
В този блог ще създадем автоматизация, която би била полезна като помощен инструмент за наблюдение на съществуващата ви база данни и ще събираме показатели относно промени в базата данни или операции за промяна на схеми.
Създаване на автоматизация за проверка на обект на схема на база данни
В това упражнение ще наблюдаваме следните показатели:
-
Няма таблици с първичен ключ
-
Дублиращи се индекси
-
Генерирайте графика за общия брой редове в нашите схеми на база данни
-
Генерирайте графика за общия размер на нашите схеми на база данни
Това упражнение ще ви даде информация и може да бъде променено, за да съберете по-разширени показатели от вашата MySQL/MariaDB база данни.
Използване на Puppet за нашия IaC и автоматизация
Това упражнение ще използва Puppet за осигуряване на автоматизация и генериране на очакваните резултати въз основа на показателите, които искаме да наблюдаваме. Няма да покриваме инсталацията и настройката за Puppet, включително сървър и клиент, така че очаквам да знаете как да използвате Puppet. Може да искате да посетите нашия стар блог Automated Deployment на MySQL Galera Cluster в Amazon AWS с Puppet, който обхваща настройката и инсталирането на Puppet.
Ще използваме най-новата версия на Puppet в това упражнение, но тъй като кодът ни се състои от основен синтаксис, той ще работи за по-стари версии на Puppet.
Предпочитан MySQL сървър на база данни
В това упражнение ще използваме Percona Server 8.0.22-13, тъй като предпочитам Percona Server най-вече за тестване и някои незначителни внедрявания за бизнес или лична употреба.
Инструмент за графики
Има много опции за използване, особено в средата на Linux. В този блог ще използвам най-лесния, който намерих, и инструмент с отворен код https://quickchart.io/.
Да играем с кукла
Предположението, което направих тук, е, че сте настроили главния сървър с регистриран клиент, който е готов да комуникира с главния сървър, за да получава автоматично внедряване.
Преди да продължим, ето информацията за моя сървър:
Главен сървър:192.168.40.200
Сървър клиент/агент:192.168.40.160
В този блог нашият клиент/агент сървър е мястото, където работи нашият сървър на база данни. В реален сценарий не е задължително той да е специално за наблюдение. Стига да може да комуникира сигурно с целевия възел, това също е перфектна настройка.
Настройте модула и кода
-
Отидете до главния сървър и в пътя /etc/puppetlabs/code/environments/production/module, нека създадем необходимите директории за това упражнение:
mkdir schema_change_mon/{files,manifests}
-
Създайте файловете, от които се нуждаем
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Попълнете скрипта init.pp със следното съдържание:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Попълнете файла graphing_gen.sh. Този скрипт ще работи на целевия възел и ще генерира графики за общия брой редове в нашата база данни, както и за общия размер на нашата база данни. За този скрипт нека го направим по-опростен и разрешим само MyISAM или InnoDB бази данни.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Накрая отидете в директорията на пътя на модула или /etc/puppetlabs/code/environments /производство в моята настройка. Нека създадем файла manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
След това попълнете файла manifests/schema_change_mon.pp със следното съдържание,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Ако сте готови, трябва да имате следната структура на дърво, точно като моята,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppКакво прави нашият модул?
Нашият модул, който се нарича schema_change_mon, събира следното,
exec { "mysql-without-primary-key" :...
Който изпълнява команда mysql и изпълнява заявка за извличане на таблици без първични ключове. След това,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :който събира дублиращи се индекси, които съществуват в таблиците на базата данни.
След това линиите генерират графики въз основа на събраните показатели. Това са следните редове,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…След като заявката се изпълни успешно, тя генерира графиката, която зависи от API, предоставен от https://quickchart.io/.
Ето следните резултати от графиката:
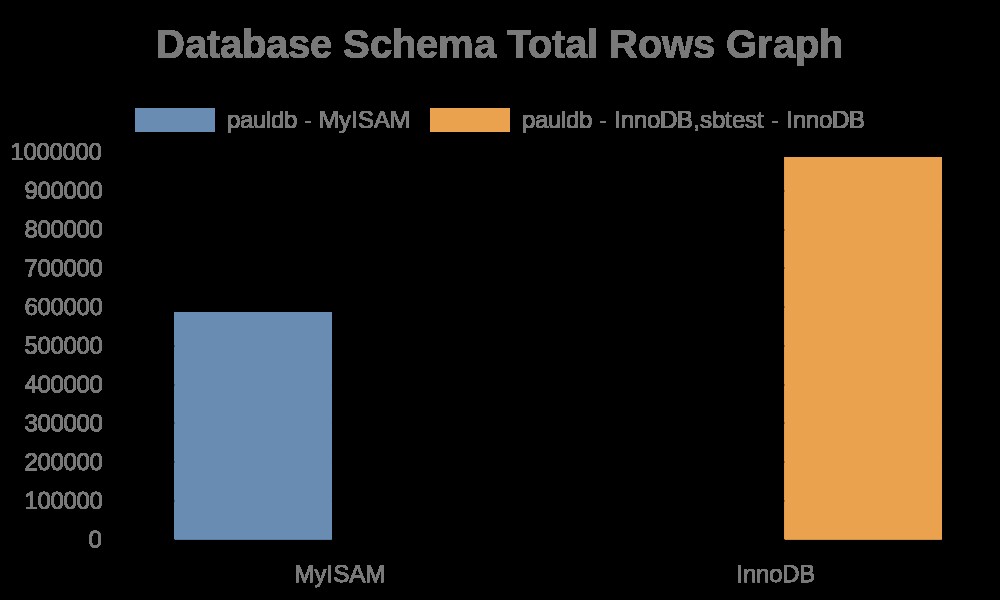
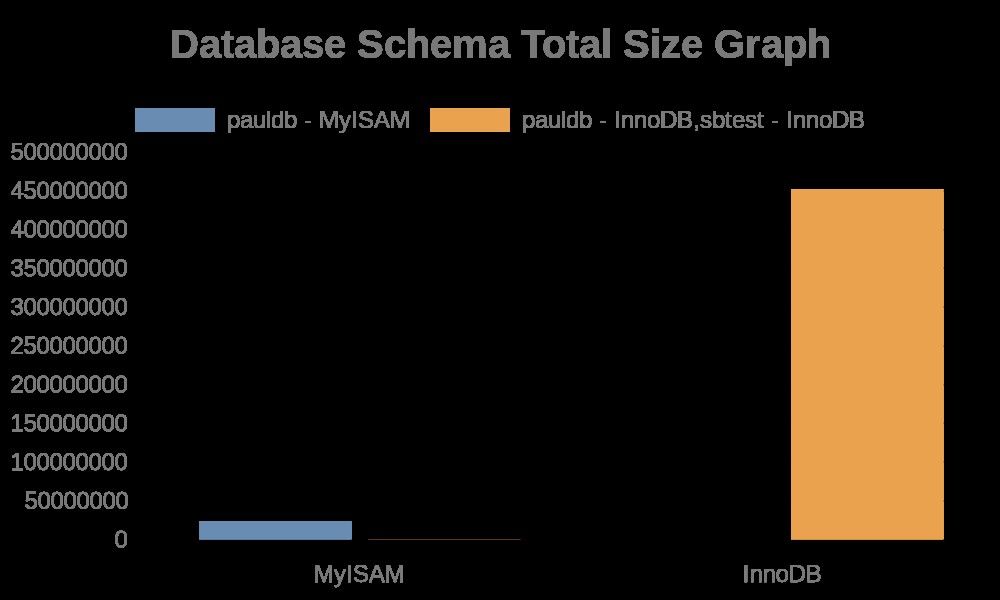
Докато регистрационните файлове на файла съдържат просто низове с имена на таблици, имена на индекси. Вижте резултата по-долу,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBЗащо да не използвате ClusterControl?
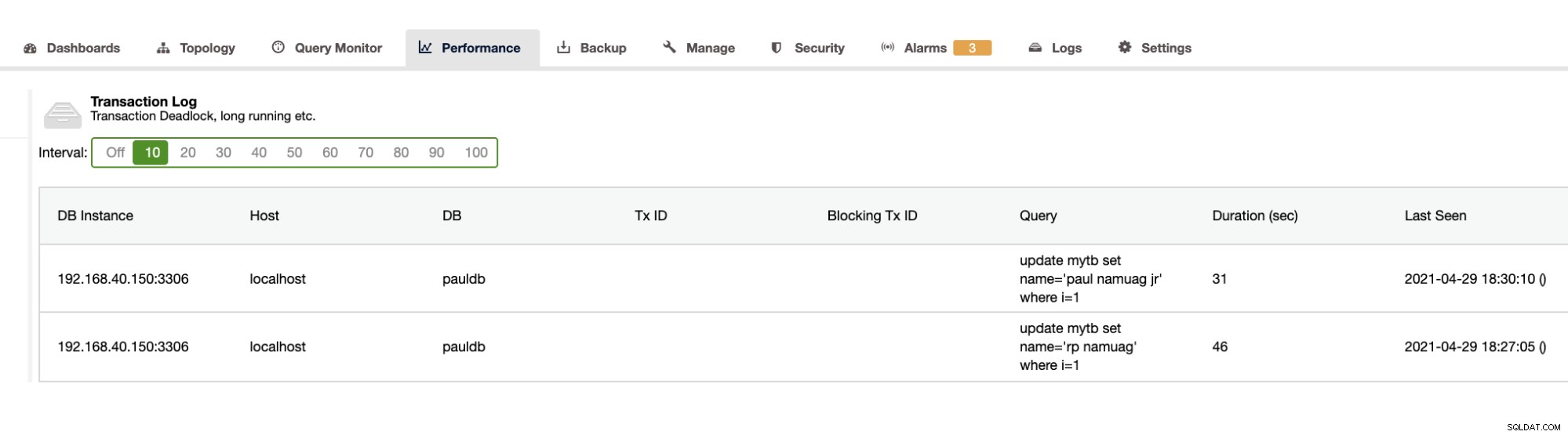
Тъй като нашето упражнение показва автоматизацията и получаването на статистически данни за схемата на базата данни, като промени или операции, ClusterControl предоставя и това. Освен това има и други функции и не е нужно да изобретявате колелото. ClusterControl може да предостави регистрационните файлове на транзакциите като блокиране, както е показано по-горе, или продължителни заявки, както е показано по-долу:
ClusterControl също показва растежа на DB, както е показано по-долу,
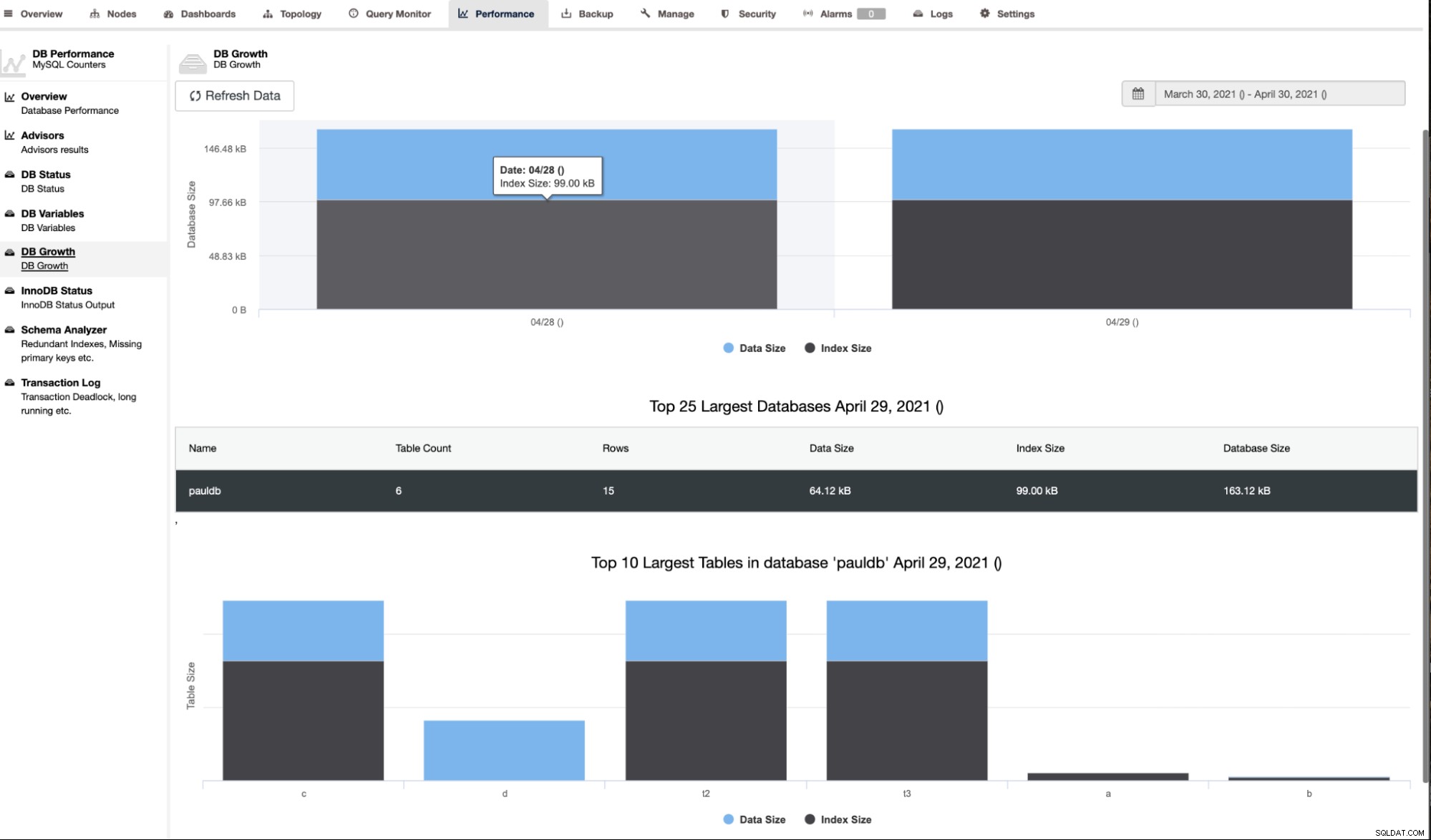
ClusterControl също така предоставя допълнителна информация като брой редове, размер на диска, размер на индекса и общ размер.
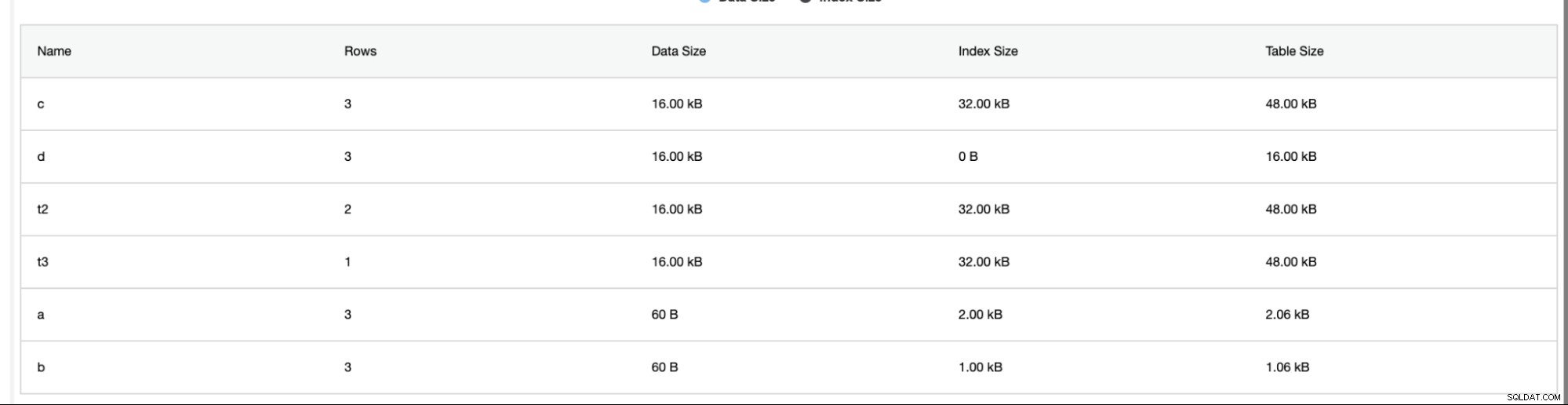
Анализаторът на схеми в раздела Производителност -> Анализатор на схеми е много полезен. Той предоставя таблици без първични ключове, MyISAM таблици и дублиращи се индекси,

Той също така предоставя аларми в случай, че има открити дублиращи се индекси или таблици без първични клавиши като по-долу,

Можете да разгледате повече информация за ClusterControl и другите му функции на страницата на нашия продукт.
Заключение
Осигуряването на автоматизация за наблюдение на промените в базата данни или каквито и да било статистически данни на схемата, като например записвания, дублирани индекси, актуализации на операции, като промени в DDL, и много дейности в базата данни е много полезно за администраторите на база данни. Помага бързо да идентифицирате слабите връзки и проблемните заявки, които биха ви дали обща представа за възможна причина за лоши заявки, които биха заключили вашата база данни или застояли вашата база данни.